Spring 中不得不了解的姿势
说明
本文非原创,我只是进行了整理以及做了一些改动,仅供学习,若需进行商业使用,请联系原作者
原作者:苏三
原文链接:苏三说技术:Spring系列
Spring IOC
本章节解读的流程为Spring容器初始化的前期准备工作
- Spring容器初始化的入口
- refresh方法的主要流程
- 解析xml配置文件
- 生成BeanDefinition
- 注册BeanDefinition
- 修改BeanDefinition
- 注册BeanPostProcessor
真正的好戏是后面的流程:实例化Bean、依赖注入、初始化Bean、BeanPostProcessor调用等。
入口
Spring容器的顶层接口是:BeanFactory,但我们使用更多的是它的子接口:ApplicationContext。
通常情况下,如果我们想要手动初始化通过xml文件配置的Spring容器时,代码是这样的:
ClassPathXmlApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext.xml");
User user = (User)applicationContext.getBean("name");
如果想要手动初始化通过配置类配置的Spring容器时,代码是这样的:
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(Config.class);
User user = (User)applicationContext.getBean("name");
这两个类应该是最常见的入口了,它们却殊途同归,最终都会调用refresh方法,该方法才是Spring容器初始化的真正入口。


调用refresh方法的类并非只有这两个,用一张图整体认识一下:
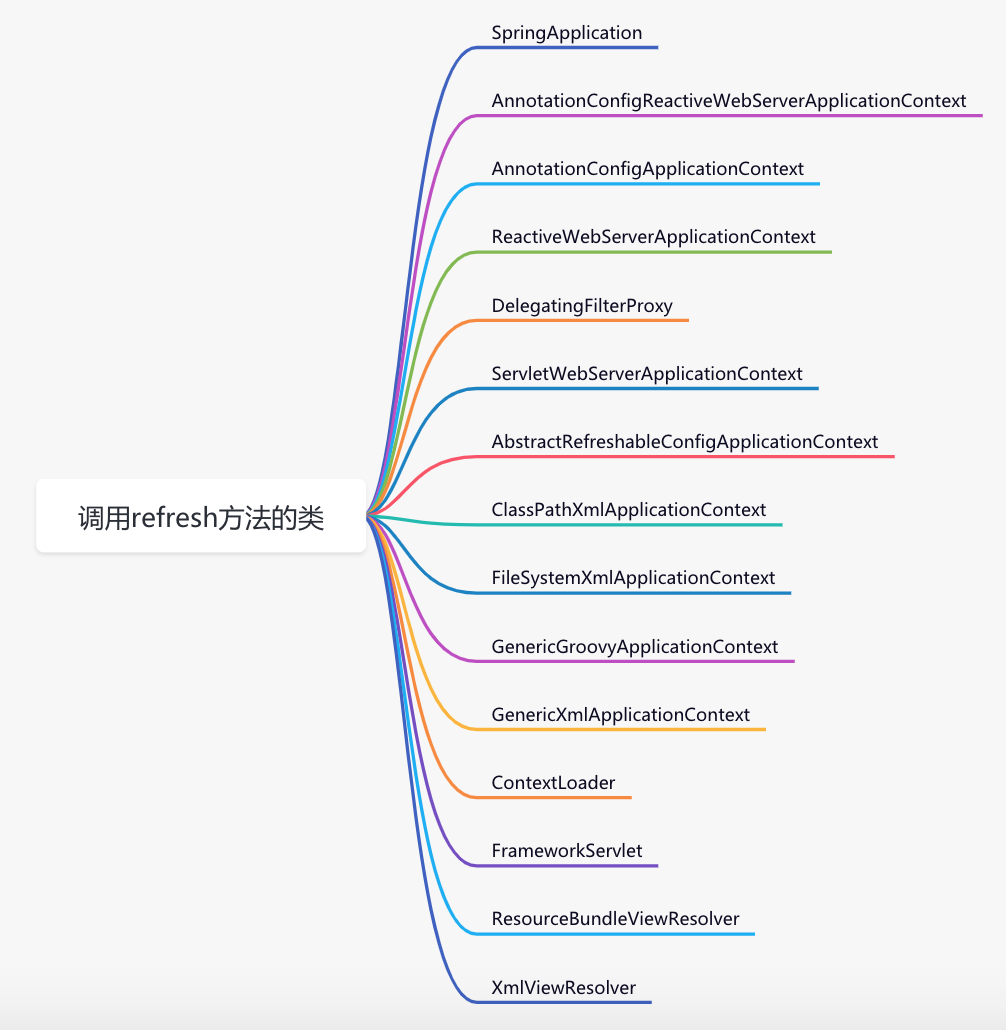
虽说调用refresh方法的类有这么多,但我决定用ClassPathXmlApplicationContext类作为列子,因为它足够经典,而且难度相对来说要小一些。
refresh方法
refresh方法是Spring IOC的真正入口,它负责初始化Spring容器。refresh表示重新构建的意思。
既然这个方法的作用是初始化Spring容器,那方法名为啥不叫init?因为它不只被调用一次。
在Spring Boot的SpringAppication类中的run方法会调用refreshContext方法,该方法会调用一次refresh方法。
在spring Cloud的BootstrapApplicationListener类中的onApplicationEvent方法会调用SpringAppication类中的run方法。也会调用一次refresh方法。
这是Spring Boot项目中如果引入了Spring Cloud,则
refresh方法会被调用两次的原因。
在Spring MVC的FrameworkServlet类中的initWebApplicationContext方法会调用configureAndRefreshWebApplicationContext方法,该方法会调用一次refresh方法,不过会提前判断容器是否激活。
所以这里的refresh表示重新构建的意思。
refresh的关键步骤:

一眼看过去好像有很多方法,但是真正的核心的方法不多,我主要讲其中最重要的:
- obtainFreshBeanFactory
- invokeBeanFactoryPostProcessors
- registerBeanPostProcessors
- 【finishBeanFactoryInitialization】
obtainFreshBeanFactory:解析xml配置文件,生成BeanDefinition对象,注册到Spring容器中
obtainFreshBeanFactory方法会解析xml的bean配置,生成BeanDefinition对象,并且注册到Spring容器中(说白了就是很多map集合中)。
经过几层调用之后,会调到AbstractBeanDefinitionReader类的loadBeanDefinitions方法:

该方法会循环locations(applicationContext.xml文件路径),调用另外一个loadBeanDefinitions方法,一个文件一个文件解析。
经过一些列的骚操作,会将location转换成inputSource和resource,然后再转换成Document对象,方便解析。

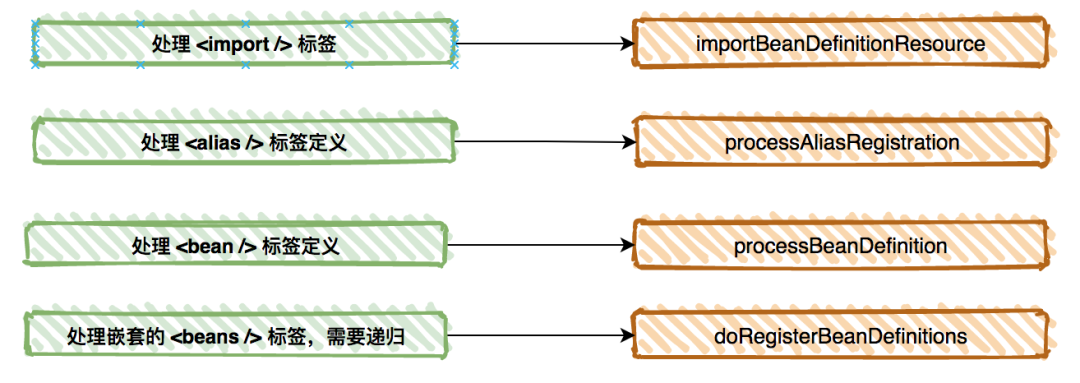
在解析xml文件时,需要判断是默认标签,还是自定义标签,处理逻辑不一样:

Spring的默认标签只有4种:
<import/><alias/><bean/><beans/>
对应的处理方法是:
提示
常见的:
<aop/>、<context/>、<mvc/>等都是自定义标签。
从上图中处理<bean/>标签的processBeanDefinition方法开始,经过一系列调用,最终会调到DefaultBeanDefinitionDocumentReader类的processBeanDefinition方法。这个方法包含了关键步骤:解析元素生成BeanDefinition 和 注册BeanDefinition。

生成BeanDefinition
上面的方法会调用BeanDefinitionParserDelegate类的parseBeanDefinitionElement方法:

一个<bean/>标签会对应一个BeanDefinition对象。
该方法又会调用同名的重载方法:processBeanDefinition,真正创建BeanDefinition对象,并且解析一系列参数填充到对象中:

其实真正创建BeanDefinition的逻辑是非常简单的,直接new了一个对象:
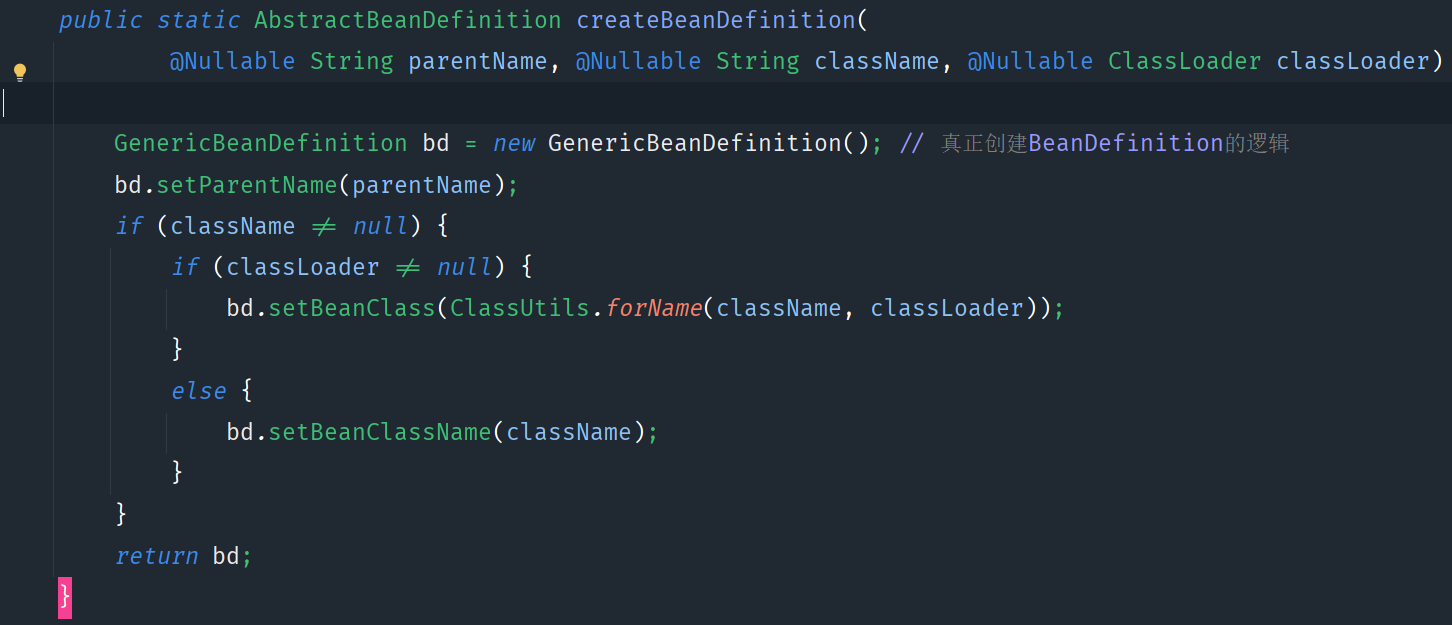
真正复杂的地方是在前面的各种属性的解析和赋值上。
注册BeanDefinition
上面通过解析xml文件生成了很多BeanDefinition对象,下面就需要把BeanDefinition对象注册到Spring容器中,这样Spring容器才能初始化bean。
BeanDefinitionReaderUtils类的registerBeanDefinition方法很简单,只有两个流程:

先看看DefaultListableBeanFactory类的registerBeanDefinition方法是如何注册beanName的:

接下来看看SimpleAliasRegistry类的registerAlias方法是如何注册alias别名的:

这样就能通过多个不同的alias找到同一个name,再通过name就能找到BeanDefinition。
invokeBeanFactoryPostProcessors:修改已经注册的BeanDefinition对象
上面BeanDefinition对象已经注册到Spring容器当中了,接下来,如果想要修改已经注册的BeanDefinition对象该怎么办?
refresh方法中通过invokeBeanFactoryPostProcessors方法修改BeanDefinition对象。
经过一系列的调用,最终会到PostProcessorRegistrationDelegate类的invokeBeanFactoryPostProcessors方法:

流程看起来很长,其实逻辑比较简单,主要是在处理BeanDefinitionRegistryPostProcessor和BeanFactoryPostProcessor。
而BeanDefinitionRegistryPostProcessor本身是一种特殊的BeanFactoryPostProcessor,它也会执行BeanFactoryPostProcessor的逻辑,只是加了一个额外的方法

ConfigurationClassPostProcessor可能是最重要的BeanDefinitionRegistryPostProcessor,它负责处理@Configuration注解。
registerBeanPostProcessors:注册BeanPostProcessor
处理完前面的逻辑,refresh方法接着会调用registerBeanPostProcessors注册BeanPostProcessor,它的功能非常强大。
经过一系列的调用,最终会到PostProcessorRegistrationDelegate类的registerBeanPostProcessors方法:
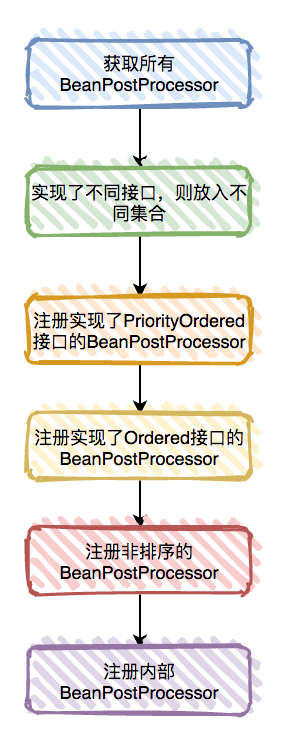
注意
这一步只是注册
BeanPostProcessor,真正的使用在后面。
Spring AOP
从实战出发
在Spring AOP还没出现之前,想要在目标方法之前先后加上日志打印的功能,我们一般是这样做的:
@Service
public class TestService {
public void doSomething1() {
beforeLog();
System.out.println("==doSomething1==");
afterLog();
}
public void doSomething2() {
beforeLog();
System.out.println("==doSomething1==");
afterLog();
}
public void doSomething3() {
beforeLog();
System.out.println("==doSomething1==");
afterLog();
}
public void beforeLog() {
System.out.println("打印请求日志");
}
public void afterLog() {
System.out.println("打印响应日志");
}
}
如果加了新doSomethingXXX方法,就需要在新方法前后手动加beforeLog和afterLog方法。
原本相安无事的,但长此以往,总会出现几个刺头青。
刺头青A说:每加一个新方法,都需要加两行重复的代码,是不是很麻烦?
刺头青B说:业务代码和公共代码是不是耦合在一起了?
刺头青C说:如果有几千个类中加了公共代码,而有一天我需要删除,是不是要疯了?
Spring大师们说:我们提供一套Spring的AOP机制,你们可以闭嘴了。
下面看看用Spring AOP(还用了aspectj)是如何打印日志的:
@Service
public class TestService {
public void doSomething1() {
System.out.println("==doSomething1==");
}
public void doSomething2() {
System.out.println("==doSomething1==");
}
public void doSomething3() {
System.out.println("==doSomething1==");
}
}
@Component
@Aspect
public class LogAspect {
@Pointcut("execution(public * com.sue.cache.service.*.*(..))")
public void pointcut() {
}
@Before("pointcut()")
public void beforeLog() {
System.out.println("打印请求日志");
}
@After("pointcut()")
public void afterLog() {
System.out.println("打印响应日志");
}
}
改造后,业务方法在TestService类中,而公共方法在LogAspect类中,是分离的。如果要新加一个业务方法,直接加就好,LogAspect类不用改任何代码,新加的业务方法就自动拥有打印日志的功能

Spring AOP其实是一种横切的思想,通过动态代理技术将公共代码织入到业务方法中。
AOP不是spring独有的,目前市面上比较出名的有:
- aspectj
- spring aop
- jboss aop
我们现在主流的做法是将Spring AOP和aspectj结合使用,Spring借鉴了AspectJ的切面,以提供注解驱动的AOP。
此时,一个吊毛一闪而过。
刺头青D问:你说的“横切”,“动态代理”,“织入” 是什么鸡巴意思?
几个重要的概念
根据上面Spring AOP的代码,用一张图聊聊几个重要的概念:

- 连接点(Joinpoint):程序执行的某个特定位置,如某个方法调用前,调用后,方法抛出异常后,这些代码中的特定点称为连接点。
- 切点(Pointcut):每个程序的连接点有多个,如何定位到某个感兴趣的连接点,就需要通过切点来定位。
- 通知 / 增强(Advice):增强是织入到目标类连接点上的一段程序代码。
- 切面(Aspect):切面由切点和通知组成,它既包括了横切逻辑的定义,也包括了连接点的定义,SpringAOP就是将切面所定义的横切逻辑织入到切面所制定的连接点中。
- 目标对象(Target):需要被增强的业务对象
- 代理类(Proxy):一个类被AOP织入增强后,就产生了一个代理类。
- 织入(Weaving):织入就是将增强添加到对目标类具体连接点上的过程。
还是刺头青D那个吊毛说(旁边:这位仁兄比较好学):Spring AOP概念弄明白了,@Pointcut注解的execution表达式刚刚看得我一脸懵逼,可以再说说不?贫道请你去洗脚城
execution:切入点表达式
@Pointcut注解的execution切入点表达,看似简单,里面还是有些内容的。为了更直观一些,还是用张图来总结一下:

该表达式的含义是:匹配访问权限是public,任意返回值,包名为:com.sue.cache.service,下面的所有类所有方法和所有参数类型(用*表示)。
如果具体匹配某个类,比如:TestService,则表达式可以换成:
@Pointcut("execution(public * com.sue.cache.service.TestService.*(..))")
其实Spring支持9种表达式,execution只是其中一种

有哪些入口?
Spring AOP有哪些入口?说人话就是在问:Spring中有哪些场景需要调用AOP生成代理对象?你不好奇?

一张图概括:
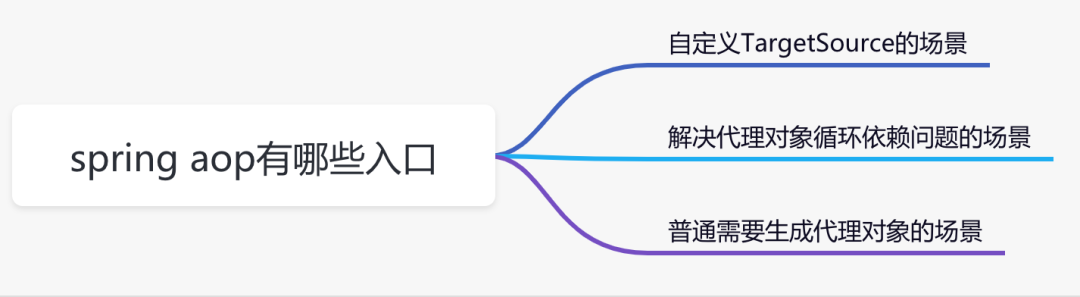
入口1:自定义TargetSource的场景
AbstractAutowireCapableBeanFactory类的createBean方法中,有这样一段代码:

它通过BeanPostProcessor提供了一个生成代理对象的机会。具体逻辑在AbstractAutoProxyCreator类的postProcessBeforeInstantiation方法中:

说白了,需要实现
TargetSource才有可能会生成代理对象。该接口是对Target目标对象的封装,通过该接口可以获取到目标对象的实例。
不出意外,这时又会冒出一个吊毛。
刺头青F说:这里生成代理对象有什么用呢?
有时我们想自己控制bean的创建和初始化,而不需要通过spring容器,这时就可以通过实现TargetSource满足要求。只是创建单纯的实例还好,如果我们想使用代理该怎么办呢?这时候,入口1的作用就体现出来了。
入口2:解决代理对象循环依赖问题的场景
AbstractAutowireCapableBeanFactory类的doCreateBean方法中,有这样一段代码:
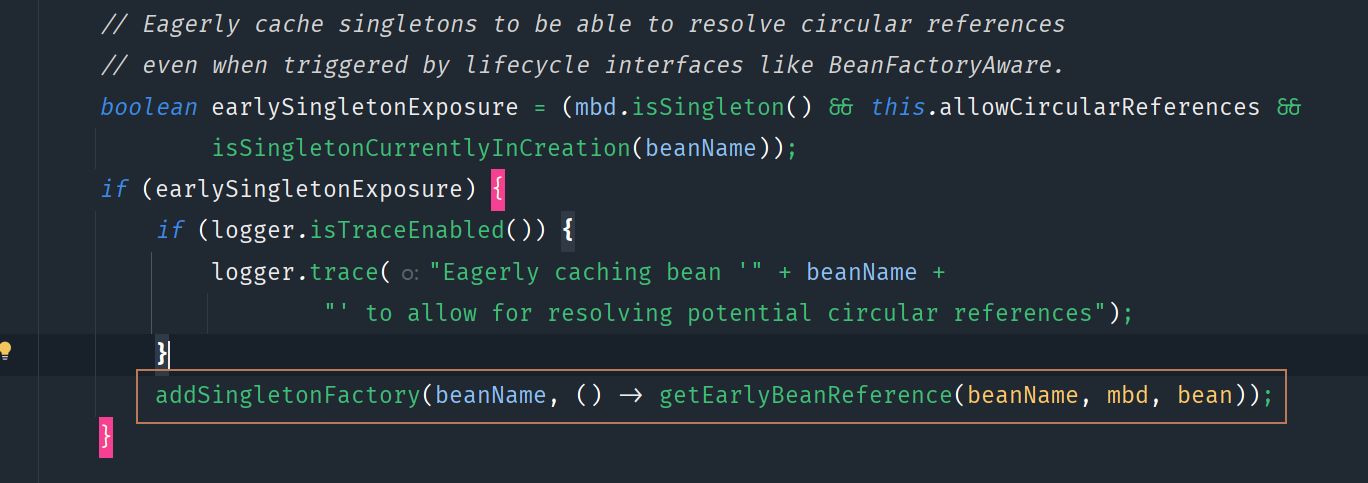
它主要作用是为了解决对象的循环依赖问题,核心思路是提前暴露singletonFactory到缓存中。
通过getEarlyBeanReference方法生成代理对象:

它又会调用wrapIfNecessary方法:

这里有你想看到的生成代理的逻辑。
这时。。。。,你猜错了,吊毛为报养育之恩,带父嫖娼去了。。。
入口3:普通Bean生成代理对象的场景
AbstractAutowireCapableBeanFactory类的initializeBean方法中,有这样一段代码:
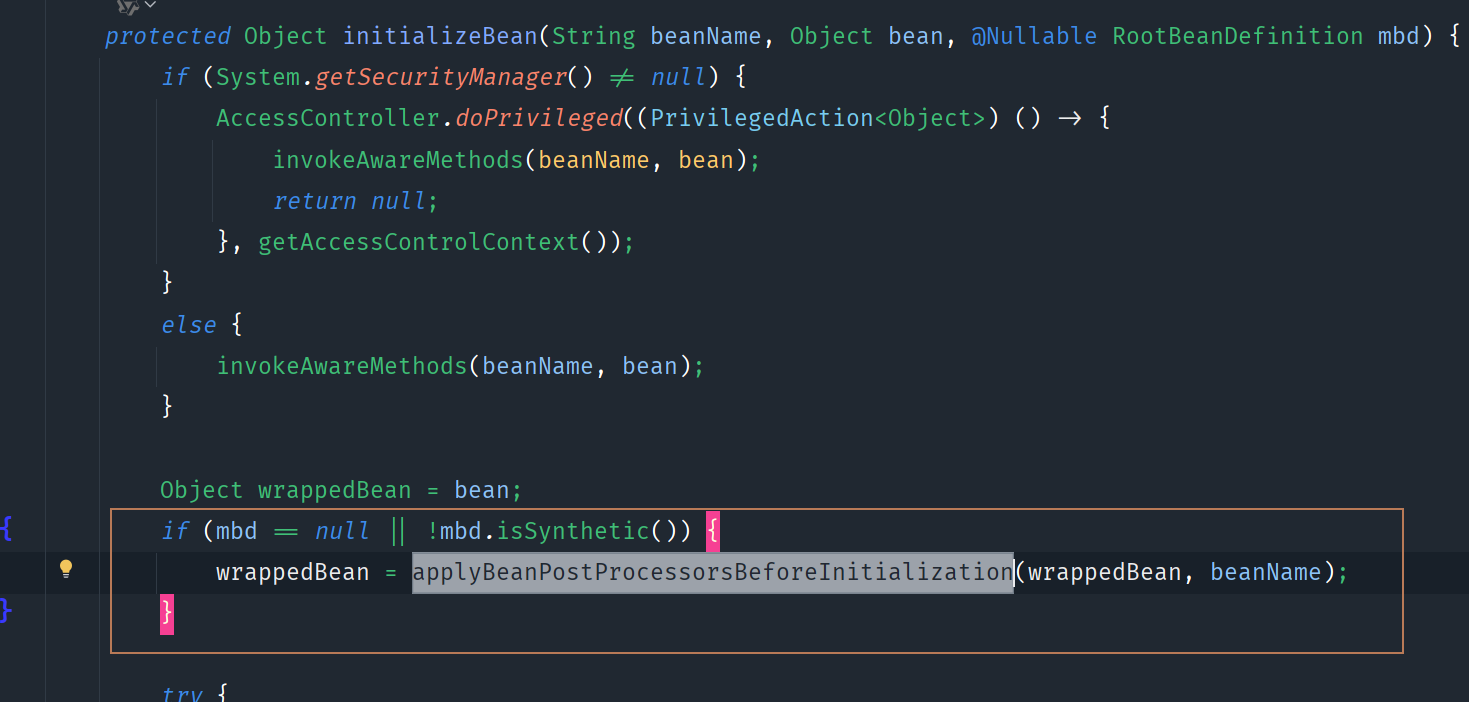
它会调用到AbstractAutoProxyCreator类postProcessAfterInitialization方法:

该方法中能看到我们熟悉的面孔:wrapIfNecessary方法。从上面得知该方法里面包含了真正生成代理对象的逻辑。
这个入口,是为了给普通bean能够生成代理用的,是Spring最常见并且使用最多的入口。
JDK动态代理 vs cglib
JDK动态代理
jdk动态代理是通过反射技术实现的
jdk动态代理三个要素:
- 定义一个接口
- 实现InvocationHandler接口
- 使用Proxy创建代理对象
public interface IUser {
void add();
}
public class User implements IUser{
@Override
public void add() {
System.out.println("===add===");
}
}
public class JdkProxy implements InvocationHandler {
private Object target;
public Object getProxy(Object target) {
this.target = target;
// 创建一个代理对象
return Proxy.newProxyInstance(this.getClass().getClassLoader(),
target.getClass().getInterfaces(),
this);
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
before();
Object result = method.invoke(target, args);
after();
return result;
}
private void before() {
System.out.println("===before===");
}
private void after() {
System.out.println("===after===");
}
}
public class Test {
public static void main(String[] args) {
User user = new User();
JdkProxy jdkProxy = new JdkProxy();
IUser proxy = (IUser)jdkProxy.getProxy(user);
proxy.add();
}
}
cglib
cglib底层是通过asm字节码技术实现的
cglib两个要素:
- 实现MethodInterceptor接口
- 使用Enhancer创建代理对象
public class User {
public void add() {
System.out.println("===add===");
}
}
public class CglibProxy implements MethodInterceptor {
private Object target;
public Object getProxy(Object target) {
this.target = target;
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(target.getClass());
enhancer.setCallback(this);
// 通过Enhancer创建代理对象
return enhancer.create();
}
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
before();
Object result = method.invoke(target,objects);
after();
return result;
}
private void before() {
System.out.println("===before===");
}
private void after() {
System.out.println("===after===");
}
}
public class Test {
public static void main(String[] args) {
User user = new User();
CglibProxy cglibProxy = new CglibProxy();
IUser proxy = (IUser)cglibProxy.getProxy(user);
proxy.add();
}
}
Spring中如何用的?
DefaultAopProxyFactory类的createAopProxy方法中,有这样一段代码:

它里面包含:
- JdkDynamicAopProxy JDK动态代理生成类
- ObjenesisCglibAopProxy cglib代理生成类
JdkDynamicAopProxy类的invoke方法生成的代理对象。而ObjenesisCglibAopProxy类的父类:CglibAopProxy,它的getProxy方法生成的代理对象。
哪个更好?
不出意外,又会来个吊毛,但这吊毛不是别人,是你!
啊,苍天啊,大地呀!勒个坟哇,我热你温啦:JDK动态代理和cglib哪个更好啊?
嘻嘻~其实这个问题没有标准答案,要看具体的业务场景:
- 没有定义接口,只能使用cglib,不说它好不行。
- 定义了接口,需要创建单例或少量对象,调用多次时,可以使用jdk动态代理,因为它创建时更耗时,但调用时速度更快。
- 定义了接口,需要创建多个对象时,可以使用cglib,因为它创建速度更快。
随着jdk版本不断迭代更新,jdk动态代理创建耗时不断被优化,8以上的版本中,跟cglib已经差不多。所以Spring官方默认推荐使用jdk动态代理,因为它调用速度更快。
如果要强制使用cglib,可以通过以下两种方式:
spring.aop.proxy-target-class=true@EnableAspectJAutoProxy(proxyTargetClass = true)
五种通知 / 增强

Spring AOP给这五种通知,分别分配了一个xxxAdvice类。在ReflectiveAspectJAdvisorFactory类的getAdvice方法中可以看得到:

用一张图总结一下对应关系:

这五种xxxAdvice类都实现了Advice接口,但是有些差异。
下面三个xxxAdvice类实现了MethodInterceptor接口:

前置通知
该通知在方法执行之前执行,只需在公共方法上加
@Before注解,就能定义前置通知
@Before("pointcut()")
public void beforeLog(JoinPoint joinPoint) {
System.out.println("打印请求日志");
}
后置通知
该通知在方法执行之后执行,只需在公共方法上加
@After注解,就能定义后置通知
@After("pointcut()")
public void afterLog(JoinPoint joinPoint) {
System.out.println("打印响应日志");
}
环绕通知
该通知在方法执行前后执行,只需在公共方法上加
@Round注解,就能定义环绕通知
@Around("pointcut()")
public Object around(ProceedingJoinPoint joinPoint) throws Throwable {
System.out.println("打印请求日志");
Object result = joinPoint.proceed();
System.out.println("打印响应日志");
return result;
}
结果通知
该通知在方法结束后执行,能够获取方法返回结果,只需在公共方法上加
@AfterReturning注解,就能定义结果通知
@AfterReturning(pointcut = "pointcut()",returning = "retVal")
public void afterReturning(JoinPoint joinPoint, Object retVal) {
System.out.println("获取结果:"+retVal);
}
异常通知
该通知在方法抛出异常之后执行,只需在公共方法上加
@AfterThrowing注解,就能定义异常通知
@AfterThrowing(pointcut = "pointcut()", throwing = "e")
public void afterThrowing(JoinPoint joinPoint, Throwable e) {
System.out.println("异常:"+e);
}
一个猝不及防,依然是刺头青D那个吊毛,不知何时从洗脚城回来站你身后,你莫名感觉一紧问了句:这五种通知的执行顺序是怎么样的?
五种通知的执行顺序
单个切面正常情况

单个切面异常情况
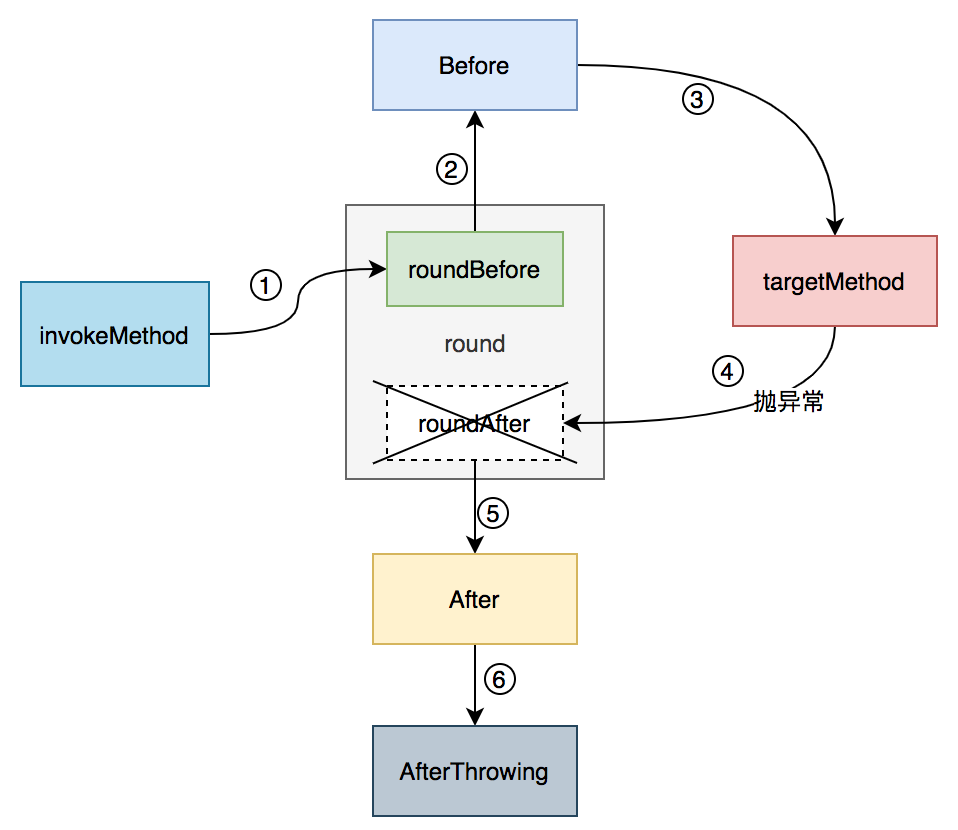
多个切面正常情况
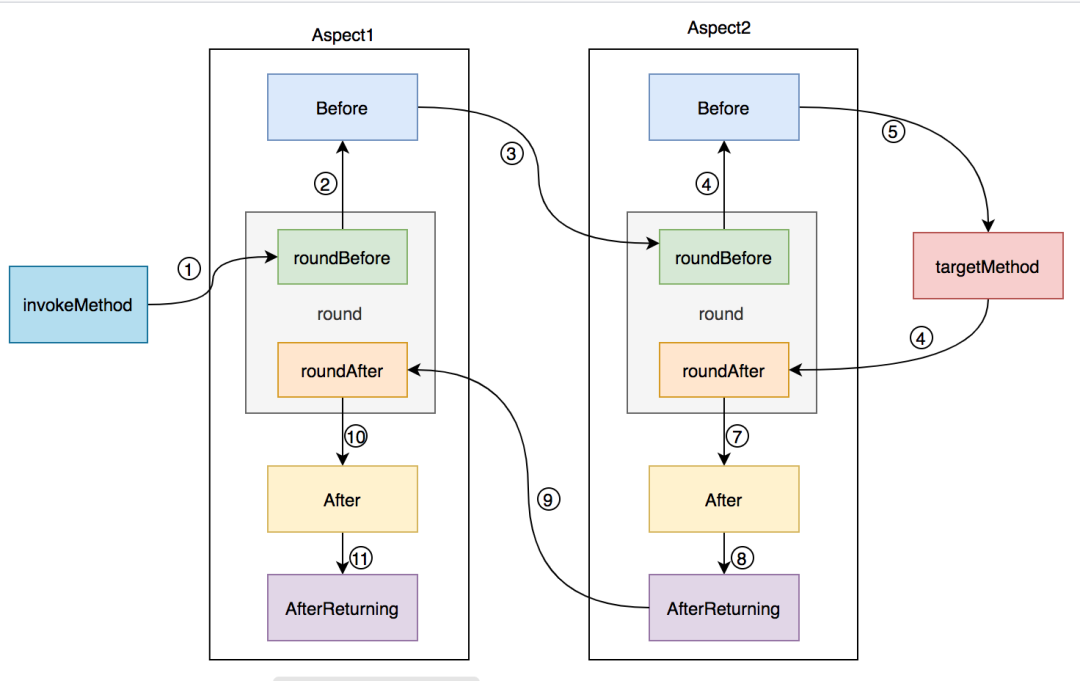
多个切面异常情况

提示
当有多切面时,按照可以通过
@Order(n)指定执行顺序,n值越小越先执行。
为什么使用链式调用?
这个问题没人问,是我自己想聊聊(旁白:因为我长得相当哇塞)
其实这个问题一看就知道答案了,即为什么要使用责任链模式?
先看看Spring是如何使用链式调用的,在ReflectiveMethodInvocation的proceed方法中,有这样一段代码:

用一张图捋一捋上面的逻辑:

包含了一个递归的链式调用,为什么要这样设计?
假如不这样设计,我们代码中是不是需要写很多if...else,根据不同的切面和通知单独处理?
而Spring巧妙的使用责任链模式消除了原本需要大量的if...else判断,让代码的扩展性更好,很好的体现了开闭原则:对扩展开放,对修改关闭。
缓存中存的是原始对象还是代理对象?
都知道Spring中为了性能考虑是有缓存的,通常说包含了三级缓存:

只听“咻儿”地一声,刺头青D的兄弟,刺头青F忍不住赶过来问了句:缓存中存的是原始对象还是代理对象?
前面那位带父搬砖的仁兄下意识地来了一句:应该不是对象,是马子
嘻嘻~这个问题要从三个方面回答
singletonFactories(三级缓存)
AbstractAutowireCapableBeanFactory类的doCreateBean方法中,有这样一段代码:
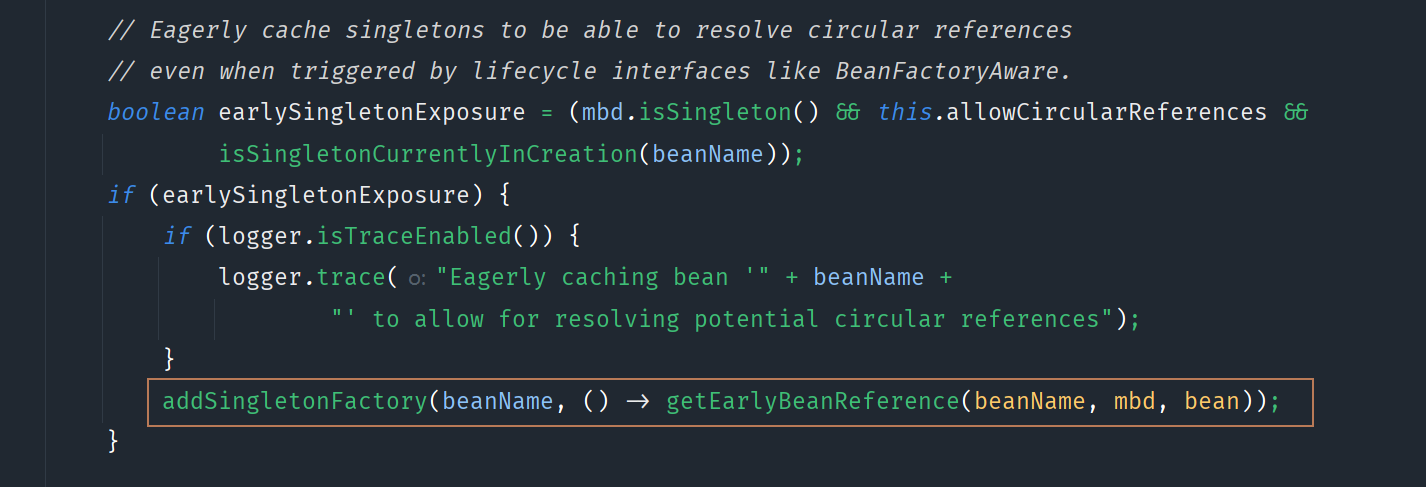
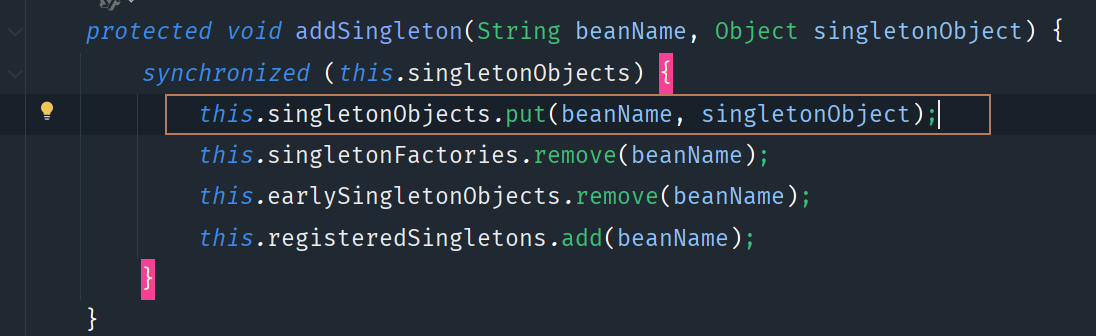
其实之前已经说过,它是为了解决循环依赖问题。这次要说的是addSingletonFactory方法:
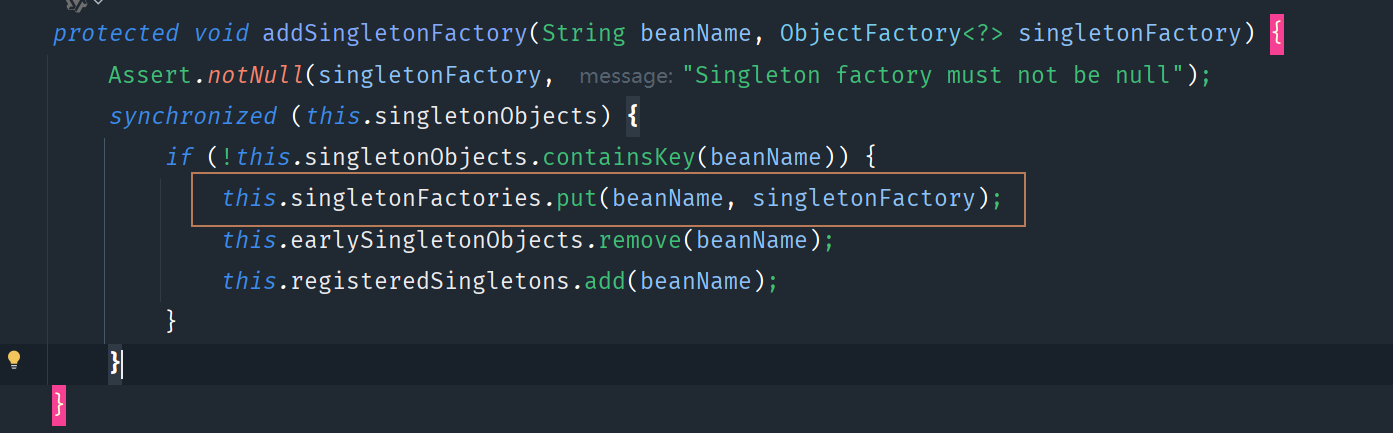
它里面保存的是singletonFactory对象,所以是原始对象
earlySingletonObjects(二级缓存)
AbstractBeanFactory类的doGetBean方法中,有这样一段代码:

在调用getBean方法获取bean实例时,会调用getSingleton尝试先从缓存中看能否获取到,如果能获取到则直接返回。
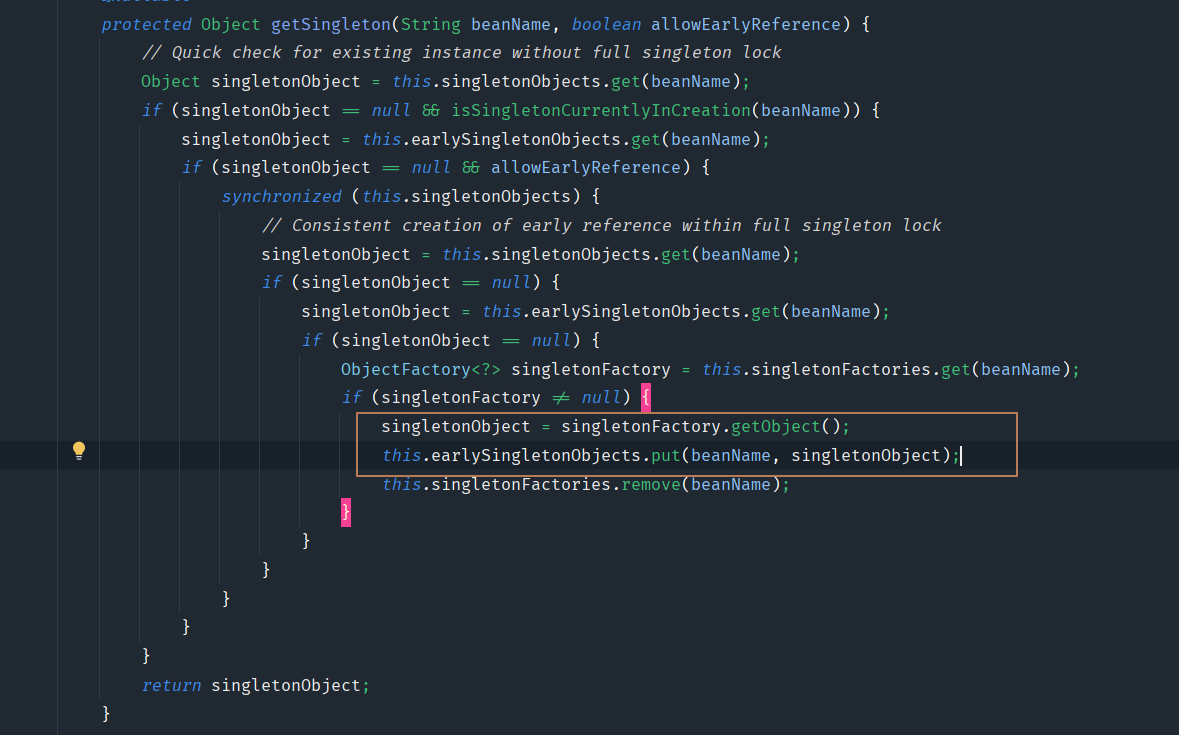
这段代码会先从一级缓存中获取bean,如果没有再从二级缓存中获取,如果还是没有则从三级缓存中获取singletonFactory,通过getObject方法获取实例,将该实例放入到二级缓存中。
答案的谜底就聚焦在getObject方法中,而这个方法又是在哪来定义的呢?
其实就是上面的getEarlyBeanReference方法,我们知道这个方法生成的是代理对象,所以二级缓存中存的是代理对象。
singletonObjects(一级缓存)
提示
走好,看好,眼睛不要打跳(t iao~ 三声),这里是DefaultSingletonBeanRegistry类的getSingleton方法,跟上面二级缓存中说的AbstractBeanFactory类getSingleton方法不一样
DefaultSingletonBeanRegistry类的getSingleton方法中,有这样一段代码:
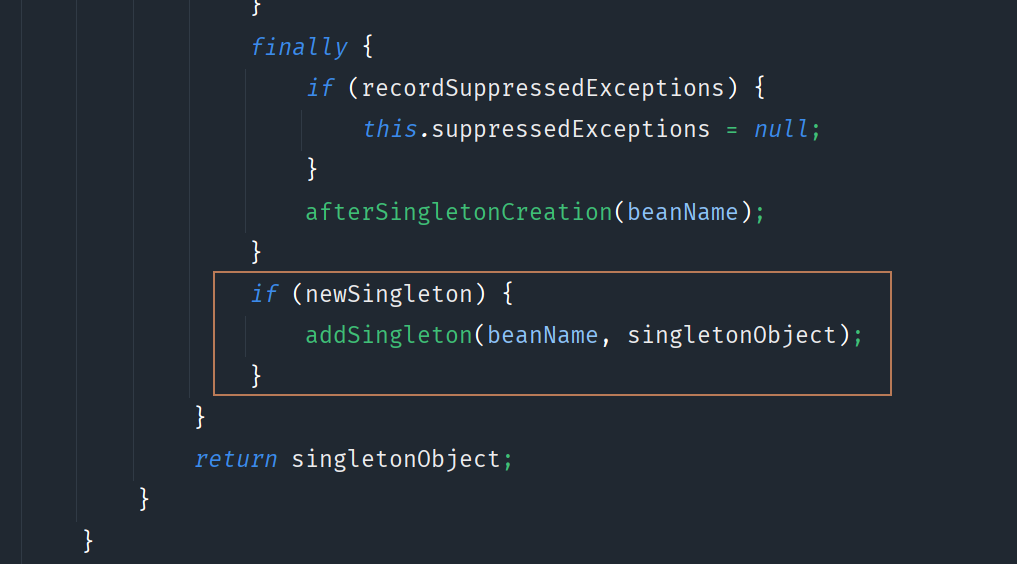
此时的bean创建、注入和初始化完成了,判断如果是新的单例对象,则会加入到一级缓存中,具体代码如下:
Spring AOP几个常见的坑
我们几乎每天都在用Spring AOP。
“啥子?我怎么不知道,你说儿豁诶?” 。
如果你每天在用Spring事务的话,就是每天在用Spring AOP,因为Spring事务的底层就用到了Spring AOP。
本节可跳过,可直接看后面的:Spring事务,这里只选取了部分内容
坑1:方法内部调用
使用Spring事务时,直接方法调用
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
@Transactional
public void add(UserModel userModel) {
userMapper.queryUser(userModel);
save(userModel);
}
@Transactional
public void save(UserModel userModel) {
System.out.println("保存数据");
}
}
这种情况直接方法调用Spring AOP无法生成代理对象,事务会失效。这个问题的解决办法有很多:
- 使用TransactionTemplate手动开启事务
- 将事务方法save放到新加的类UserSaveService中,通过userSaveService.save调用事务方法。
- UserService类中
@Autowired注入自己的实例userService,通过userService.save调用事务方法。 - 通过AopContext类获取代理对象:
((UserService)AopContext.currentProxy()).save(user);
坑2:访问权限错误
@Service
public class UserService {
@Autowired
private UserService userService;
@Autowired
private UserMapper userMapper;
public void add(UserModel userModel) {
userMapper.queryUser(userModel);
userService.save(userModel);
}
@Transactional
private void save(UserModel userModel) {
System.out.println("保存数据");
}
}
上面用 UserService类中@Autowired注入自己的实例userService的方式解决事务失效问题,如果不出意外的话,是可以的。
但是恰恰出现了意外,save方法被定义成了private的,这时也无法生成代理对象,事务同样会失效。
因为Spring要求被代理方法必须是public的
坑3:目标类用final修饰
@Service
public class UserService {
@Autowired
private UserService userService;
@Autowired
private UserMapper userMapper;
public void add(UserModel userModel) {
userMapper.queryUser(userModel);
userService.save(userModel);
}
@Transactional
public final void save(UserModel userModel) {
System.out.println("保存数据");
}
}
这种情况Spring AOP生成代理对象,重写save方法时,发现的final的,重写不了,也会导致事务失效。
如果某个方法用final修饰了,那么在它的代理类中,就无法重写该方法,而添加事务功能。
重要提示
如果某个方法是static的,同样无法通过动态代理,变成事务方法。
坑4:循环依赖问题
在使用@Async注解开启异步功能的场景,它会通过AOP自动生成代理对象
@Service
public class TestService1 {
@Autowired
private TestService2 testService2;
@Async
public void test1() {
}
}
@Service
public class TestService2 {
@Autowired
private TestService1 testService1;
public void test2() {
}
}
启动服务会报错:
org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'testService1': Bean with name 'testService1' has been injected into other beans [testService2] in its raw version as part of a circular reference, but has eventually been wrapped. This means that said other beans do not use the final version of the bean. This is often the result of over-eager type matching - consider using 'getBeanNamesOfType' with the 'allowEagerInit' flag turned off, for example.
获取Spring容器对象的方式
实现BeanFactoryAware接口
实现BeanFactoryAware接口,然后重写setBeanFactory方法,就能从该方法中获取到Spring容器对象。
@Service
public class PersonService implements BeanFactoryAware {
private BeanFactory beanFactory;
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
this.beanFactory = beanFactory;
}
public void add() {
Person person = (Person) beanFactory.getBean("person");
}
}
实现ApplicationContextAware接口
实现ApplicationContextAware接口,然后重写setApplicationContext方法,也能从该方法中获取到Spring容器对象。
@Service
public class PersonService2 implements ApplicationContextAware {
private ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
public void add() {
Person person = (Person) applicationContext.getBean("person");
}
}
实现ApplicationListener接口
实现ApplicationListener接口,需要注意的是该接口接收的泛型是ContextRefreshedEvent类,然后重写onApplicationEvent方法,也能从该方法中获取到Spring容器对象。
@Service
public class PersonService3 implements ApplicationListener<ContextRefreshedEvent> {
private ApplicationContext applicationContext;
@Override
public void onApplicationEvent(ContextRefreshedEvent event) {
applicationContext = event.getApplicationContext();
}
public void add() {
Person person = (Person) applicationContext.getBean("person");
}
}
提一下Aware接口,它其实是一个空接口,里面不包含任何方法。它表示已感知的意思,通过这类接口可以获取指定对象,比如:
- 通过BeanFactoryAware获取BeanFactory
- 通过ApplicationContextAware获取ApplicationContext
- 通过BeanNameAware获取BeanName等
Aware接口是很常用的功能,目前包含如下功能:
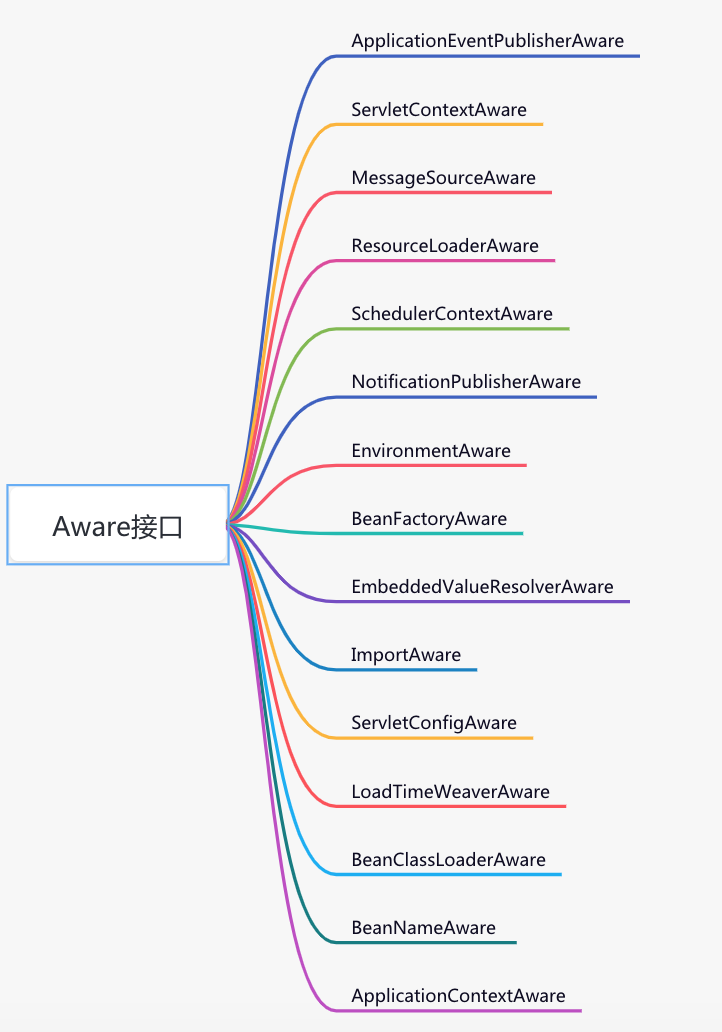
如何初始化bean
Spring中支持3种初始化bean的方法:
- xml中指定init-method方法。此种方式很老了
- 使用@PostConstruct注解
- 实现InitializingBean接口
使用@PostConstruct注解
在需要初始化的方法上增加@PostConstruct注解,这样就有初始化的能力。
@Service
public class AService {
@PostConstruct
public void init() {
System.out.println("===初始化===");
}
}
实现InitializingBean接口
实现InitializingBean接口,重写afterPropertiesSet方法,该方法中可以完成初始化功能。
@Service
public class BService implements InitializingBean {
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("===初始化===");
}
}
顺便抛出一个有趣的问题:init-method、PostConstruct 和 InitializingBean 的执行顺序是什么样的?
决定他们调用顺序的关键代码在AbstractAutowireCapableBeanFactory类的initializeBean方法中。

这段代码中会先调用BeanPostProcessor的postProcessBeforeInitialization方法,而PostConstruct是通过InitDestroyAnnotationBeanPostProcessor实现的,它就是一个BeanPostProcessor,所以PostConstruct先执行。
而invokeInitMethods方法中的代码:
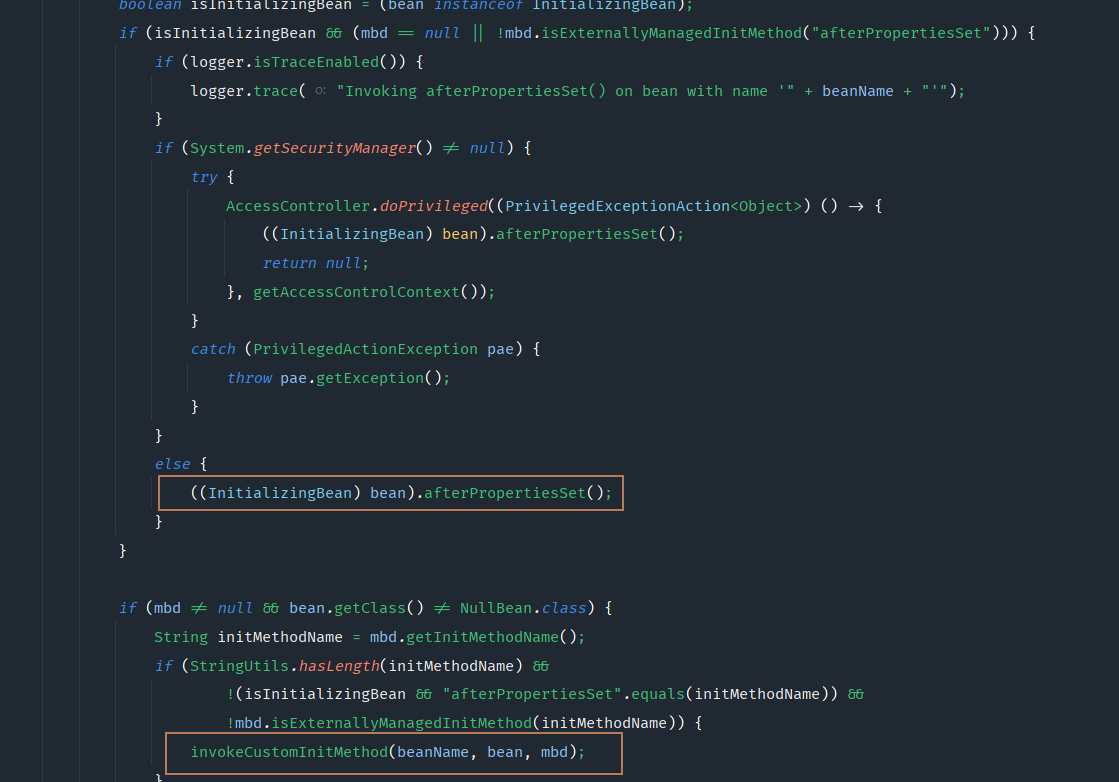
决定了先调用InitializingBean,再调用init-method。
所以得出结论,他们的调用顺序是:

自定义自己的Scope
我们都知道Spring默认支持的Scope只有两种:
- singleton 单例,每次从Spring容器中获取到的bean都是同一个对象。
- prototype 多例,每次从Spring容器中获取到的bean都是不同的对象。
Spring web又对Scope进行了扩展,增加了:
- RequestScope 同一次请求从Spring容器中获取到的bean都是同一个对象。
- SessionScope 同一个会话从Spring容器中获取到的bean都是同一个对象。
即便如此,有些场景还是无法满足我们的要求。
比如,我们想在同一个线程中从Spring容器获取到的bean都是同一个对象,该怎么办?
这就需要自定义Scope了。
- 实现
Scope接口
public class ThreadLocalScope implements Scope {
private static final ThreadLocal THREAD_LOCAL_SCOPE = new ThreadLocal();
@Override
public Object get(String name, ObjectFactory<?> objectFactory) {
Object value = THREAD_LOCAL_SCOPE.get();
if (value != null) {
return value;
}
Object object = objectFactory.getObject();
THREAD_LOCAL_SCOPE.set(object);
return object;
}
@Override
public Object remove(String name) {
THREAD_LOCAL_SCOPE.remove();
return null;
}
@Override
public void registerDestructionCallback(String name, Runnable callback) {
}
@Override
public Object resolveContextualObject(String key) {
return null;
}
@Override
public String getConversationId() {
return null;
}
}
- 将新定义的
Scope注入到Spring容器中
@Component
public class ThreadLocalBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
beanFactory.registerScope("threadLocalScope", new ThreadLocalScope());
}
}
- 使用新定义的
Scope
@Scope("threadLocalScope")
@Service
public class CService {
public void add() {
}
}
FactoryBean
说起FactoryBean就不得不提BeanFactory,因为面试官老喜欢问它们的区别。
- BeanFactory:Spring容器的顶级接口,管理bean的工厂。
- FactoryBean:并非普通的工厂bean,它隐藏了实例化一些复杂Bean的细节,给上层应用带来了便利。
Spring源码中有70多个地方在用FactoryBean接口。
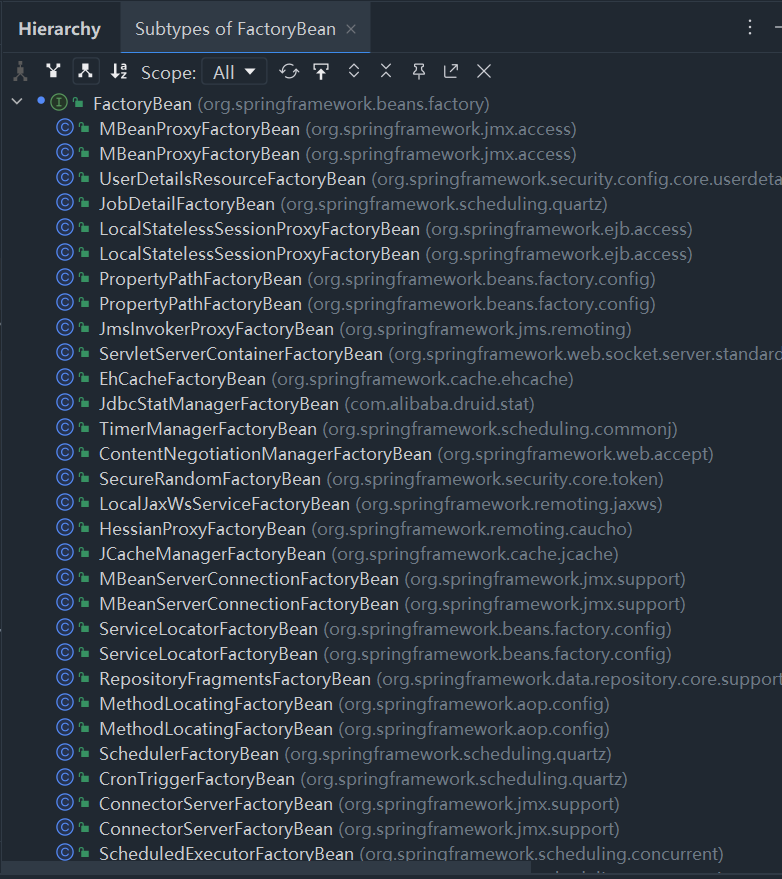
上面这张图足以说明该接口的重要性
提一句:
mybatis的SqlSessionFactory对象就是通过SqlSessionFactoryBean类创建的。
定义自己的FactoryBean
@Component
public class MyFactoryBean implements FactoryBean {
@Override
public Object getObject() throws Exception {
String data1 = buildData1();
String data2 = buildData2();
return buildData3(data1, data2);
}
private String buildData1() {
return "data1";
}
private String buildData2() {
return "data2";
}
private String buildData3(String data1, String data2) {
return data1 + data2;
}
@Override
public Class<?> getObjectType() {
return null;
}
}
获取FactoryBean实例对象
@Service
public class MyFactoryBeanService implements BeanFactoryAware {
private BeanFactory beanFactory;
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
this.beanFactory = beanFactory;
}
public void test() {
Object myFactoryBean = beanFactory.getBean("myFactoryBean");
System.out.println(myFactoryBean);
Object myFactoryBean1 = beanFactory.getBean("&myFactoryBean");
System.out.println(myFactoryBean1);
}
}
getBean("myFactoryBean");获取的是MyFactoryBeanService类中getObject方法返回的对象,getBean("&myFactoryBean");获取的才是MyFactoryBean对象。
自定义类型转换
Spring目前支持3中类型转换器:
- Converter<S,T>:将 S 类型对象转为 T 类型对象
- ConverterFactory<S, R>:将 S 类型对象转为 R 类型及子类对象
- GenericConverter:它支持多个source和目标类型的转化,同时还提供了source和目标类型的上下文,这个上下文能让你实现基于属性上的注解或信息来进行类型转换。
这3种类型转换器使用的场景不一样,我们以Converter<S,T>为例。假如:接口中接收参数的实体对象中,有个字段的类型是Date,但是实际传参的是字符串类型:2021-01-03 10:20:15,要如何处理呢?
- 定义一个实体
User
@Data
public class User {
private Long id;
private String name;
private Date registerDate;
}
- 实现
Converter接口
public class DateConverter implements Converter<String, Date> {
private SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
@Override
public Date convert(String source) {
if (source != null && !"".equals(source)) {
try {
simpleDateFormat.parse(source);
} catch (ParseException e) {
e.printStackTrace();
}
}
return null;
}
}
- 将新定义的类型转换器注入到Spring容器中
@Configuration
public class WebConfig extends WebMvcConfigurerAdapter {
@Override
public void addFormatters(FormatterRegistry registry) {
registry.addConverter(new DateConverter());
}
}
- 调用接口
RequestMapping("/user")
@RestController
public class UserController {
@RequestMapping("/save")
public String save(@RequestBody User user) {
return "success";
}
}
请求接口时User对象中registerDate字段会被自动转换成Date类型。
Spring MVC拦截器
Spring MVC拦截器跟Spring拦截器相比,它里面能够获取HttpServletRequest和HttpServletResponse 等web对象实例。
Spring MVC拦截器的顶层接口是:HandlerInterceptor,包含三个方法:
- preHandle 目标方法执行前执行
- postHandle 目标方法执行后执行
- afterCompletion 请求完成时执行
为了方便我们一般情况会用HandlerInterceptor接口的实现类HandlerInterceptorAdapter类。
假如有权限认证、日志、统计的场景,可以使用该拦截器。
- 继承
HandlerInterceptorAdapter类定义拦截器
public class AuthInterceptor extends HandlerInterceptorAdapter {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
throws Exception {
String requestUrl = request.getRequestURI();
if (checkAuth(requestUrl)) {
return true;
}
return false;
}
private boolean checkAuth(String requestUrl) {
System.out.println("===权限校验===");
return true;
}
}
- 将该拦截器注册到Spring容器
@Configuration
public class WebAuthConfig extends WebMvcConfigurerAdapter {
@Bean
public AuthInterceptor getAuthInterceptor() {
return new AuthInterceptor();
}
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new AuthInterceptor());
}
}
在请求接口时Spring MVC通过该拦截器,能够自动拦截该接口,并且校验权限。
可以在DispatcherServlet类的doDispatch方法中看到调用过程:

RestTemplate拦截器
我们使用RestTemplate调用远程接口时,有时需要在header中传递信息,比如:traceId,source等,便于在查询日志时能够串联一次完整的请求链路,快速定位问题。
这种业务场景就能通过ClientHttpRequestInterceptor接口实现,具体做法如下:
- 实现
ClientHttpRequestInterceptor接口
public class RestTemplateInterceptor implements ClientHttpRequestInterceptor {
@Override
public ClientHttpResponse intercept(HttpRequest request, byte[] body, ClientHttpRequestExecution execution) throws IOException {
request.getHeaders().set("traceId", MdcUtil.get());
return execution.execute(request, body);
}
}
MdcUtil其实是利用MDC工具在ThreadLocal中存储和获取traceId
public class MdcUtil {
private static final String TRACE_ID = "TRACE_ID";
public static String get() {
return MDC.get(TRACE_ID);
}
public static void add(String value) {
MDC.put(TRACE_ID, value);
}
}
- 定义配置类
@Configuration
public class RestTemplateConfiguration {
@Bean
public RestTemplate restTemplate() {
RestTemplate restTemplate = new RestTemplate();
restTemplate.setInterceptors(Collections.singletonList(restTemplateInterceptor()));
return restTemplate;
}
@Bean
public RestTemplateInterceptor restTemplateInterceptor() {
return new RestTemplateInterceptor();
}
}
这个例子中没有演示MdcUtil类的add方法具体调的地方,我们可以在filter中执行接口方法之前,生成traceId,调用MdcUtil类的add方法添加到MDC中,然后在同一个请求的其他地方就能通过MdcUtil类的get方法获取到该traceId。
统一异常处理
@RestControllerAdvice // controller增强
public class GlobalExceptionHandler {
@ExceptionHandler(Exception.class) // 捕获哪种异常会触发本方法
public String handleException(Exception e) {
if (e instanceof ArithmeticException) {
return "数据异常";
}
if (e instanceof Exception) {
return "服务器内部异常";
}
retur nnull;
}
}
只需在handleException方法中处理异常情况,业务接口中可以放心使用,不再需要捕获异常(有人统一处理了)。
异步
以前我们在使用异步功能时,通常情况下有三种方式:
- 继承Thread类
- 实现Runable接口
- 使用线程池
第一种:继承Thread类
public class MyThread extends Thread {
@Override
public void run() {
System.out.println("===call MyThread===");
}
public static void main(String[] args) {
new MyThread().start();
}
}
第二种:实现Runable接口
public class MyWork implements Runnable {
@Override
public void run() {
System.out.println("===call MyWork===");
}
public static void main(String[] args) {
new Thread(new MyWork()).start();
}
}
第三种:使用线程池
public class MyThreadPool {
private static ExecutorService executorService = new ThreadPoolExecutor(1, 5, 60, TimeUnit.SECONDS, new ArrayBlockingQueue<>(200));
static class Work implements Runnable {
@Override
public void run() {
System.out.println("===call work===");
}
}
public static void main(String[] args) {
try {
executorService.submit(new MyThreadPool.Work());
} finally {
executorService.shutdown();
}
}
}
这三种实现异步的方法不能说不好,但是Spring已经帮我们抽取了一些公共的地方,我们无需再继承Thread类或实现Runable接口,它都搞定了。使用方式如下:
- Spring Boot项目启动类上加
@EnableAsync注解
@EnableAsync
@SpringBootApplication
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(WebApplicationType.SERVLET).run(args);
}
}
- 在需要使用异步的方法上加上
@Async注解
@Service
public class PersonService {
@Async
public String get() {
System.out.println("===add==");
return "data";
}
}
然后在使用的地方调用一下:personService.get();就拥有了异步功能。
默认情况下,Spring会为我们的异步方法创建一个线程去执行,如果该方法被调用次数非常多的话,需要创建大量的线程,会导致资源浪费。
这时,我们可以定义一个线程池,异步方法将会被自动提交到线程池中执行。
@Configuration
public class ThreadPoolConfig {
@Value("${thread.pool.corePoolSize:5}")
private int corePoolSize;
@Value("${thread.pool.maxPoolSize:10}")
private int maxPoolSize;
@Value("${thread.pool.queueCapacity:200}")
private int queueCapacity;
@Value("${thread.pool.keepAliveSeconds:30}")
private int keepAliveSeconds;
@Value("${thread.pool.threadNamePrefix:ASYNC_}")
private String threadNamePrefix;
@Bean
public Executor MessageExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(maxPoolSize);
executor.setQueueCapacity(queueCapacity);
executor.setKeepAliveSeconds(keepAliveSeconds);
executor.setThreadNamePrefix(threadNamePrefix);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.initialize();
return executor;
}
}
Spring异步的核心方法:
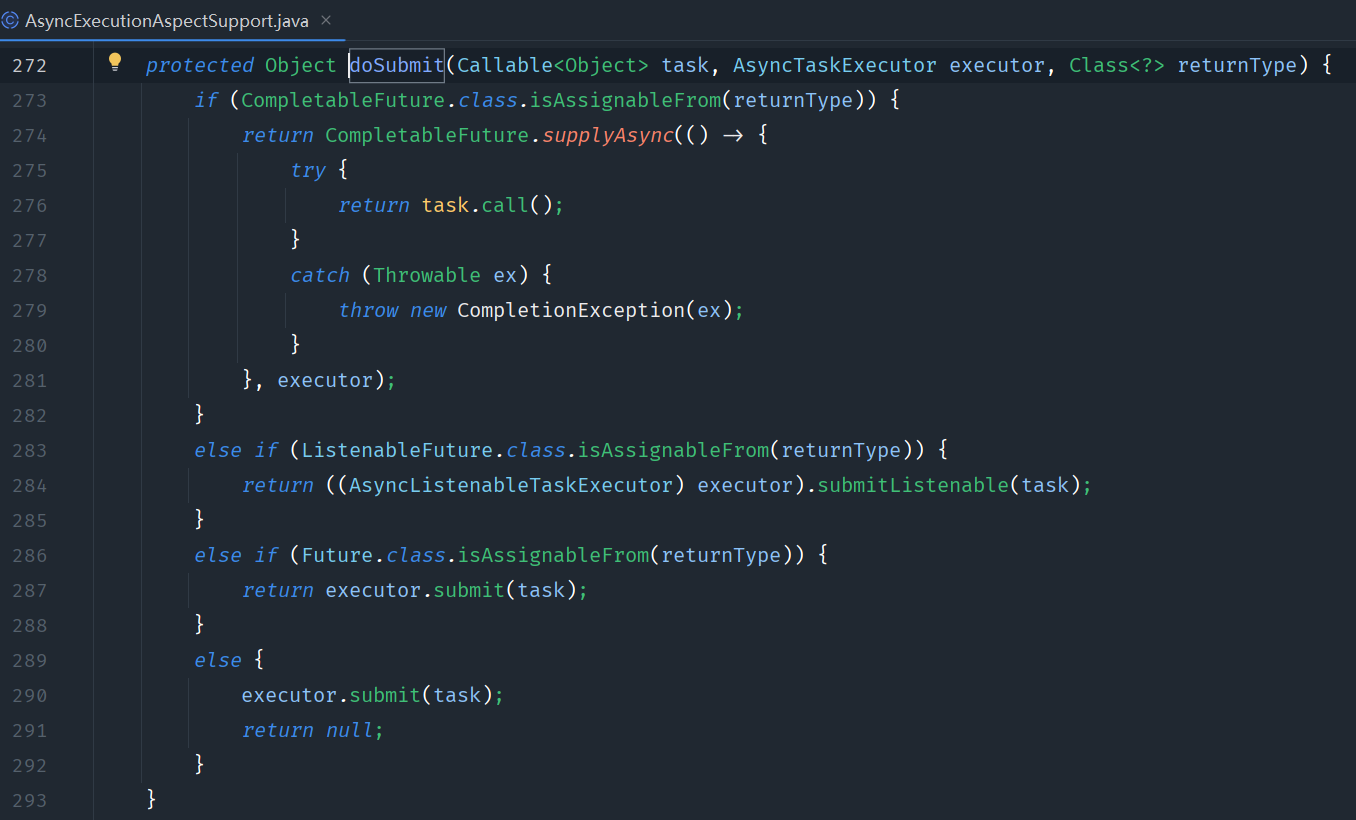
根据返回值不同,处理情况也不太一样,具体分为如下情况:

Spring cache
Spring cache架构图:

它目前支持多种缓存:

这里以caffeine为例,它是Spring官方推荐的。
- 引入
caffeine的相关jar包
<dependency>
<groupId>org.Springframework.boot</groupId>
<artifactId>Spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.6.0</version>
</dependency>
- 配置
CacheManager,开启EnableCaching
@Configuration
@EnableCaching // 此注解根据情况也可以放到启动类上
public class CacheConfig {
@Bean
public CacheManager cacheManager(){
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
// Caffeine配置
Caffeine<Object, Object> caffeine = Caffeine.newBuilder()
// 最后一次写入后经过固定时间过期
.expireAfterWrite(10, TimeUnit.SECONDS)
// 缓存的最大条数
.maximumSize(1000);
cacheManager.setCaffeine(caffeine);
return cacheManager;
}
}
- 使用
Cacheable注解获取数据
@Service
public class CategoryService {
// category是缓存名称,#type是具体的key,可支持el表达式
@Cacheable(value = "category", key = "#type")
public CategoryModel getCategory(Integer type) {
return getCategoryByType(type);
}
private CategoryModel getCategoryByType(Integer type) {
System.out.println("根据不同的type:" + type + "获取不同的分类数据");
CategoryModel categoryModel = new CategoryModel();
categoryModel.setId(1L);
categoryModel.setParentId(0L);
categoryModel.setName("电器");
categoryModel.setLevel(3);
return categoryModel;
}
}
调用categoryService.getCategory()方法时,先从caffine缓存中获取数据,如果能够获取到数据则直接返回该数据,不会进入方法体。如果不能获取到数据,则直接方法体中的代码获取到数据,然后放到caffine缓存中。
@CacheConfig注解
用于标注在类上,可以存放该类中所有缓存的公有属性(如:设置缓存名字)。
@CacheConfig(cacheNames = "users")
public class UserService{
}
当然:这个注解其实可以使用@Cacheable来代替。
@Cacheable注解(读数据时):用得最多
应用到读取数据的方法上,如:查找数据的方法,使用了之后可以做到先从本地缓存中读取数据,若是没有,则再调用此注解下的方法去数据库中读取数据,当然:还可以将数据库中读取的数据放到用此注解配置的指定缓存中。
@Cacheable(value = "user", key = "#userId")
User selectUserById( Integer userId );
@Cacheable 注解的属性:
value、cacheNames- 这两个参数其实是等同的( acheNames为Spring 4新增的,作为value的别名)。
- 这两个属性的作用:用于指定缓存存储的集合名。
key作用:缓存对象存储在Map集合中的key值。condition作用:缓存对象的条件。 即:只有满足这里面配置的表达式条件的内容才会被缓存,如:@Cache( key = "#userId",condition="#userId.length() < 3"这个表达式表示只有当userId长度小于3的时候才会被缓存。unless作用:另外一个缓存条件。 它不同于condition参数的地方在于此属性的判断时机(此注解中编写的条件是在函数被调用之后才做判断,所以:这个属性可以通过封装的result进行判断)。keyGenerator- 作用:用于指定key生成器。 若需要绑定一个自定义的key生成器,我们需要去实现
org.Springframewart.cahce.intercceptor.KeyGenerator接口,并使用该参数来绑定。 - 注意点:该参数与上面的key属性是互斥的。
- 作用:用于指定key生成器。 若需要绑定一个自定义的key生成器,我们需要去实现
cacheManager作用:指定使用哪个缓存管理器。 也就是当有多个缓存器时才需要使用。cacheResolver- 作用:指定使用哪个缓存解析器。
- 需要通过
org.Springframewaork.cache.interceptor.CacheResolver接口来实现自己的缓存解析器。
@CachePut注解 (写数据时)
用在写数据的方法上,如:新增 / 修改方法,调用方法时会自动把对应的数据放入缓存,
@CachePut的参数和@Cacheable差不多。
@CachePut(value="user", key = "#userId")
public User save(User user) {
users.add(user);
return user;
}
@CacheEvict注解 (删除数据时)
用在删除数据的方法上,调用方法时会从缓存中移除相应的数据。
@CacheEvict(value = "user", key = "#userId")
void delete( Integer userId);
这个注解除了和 @Cacheable 一样的参数之外,还有另外两个参数:
allEntries: 默认为false,当为true时,会移除缓存中该注解该属性所在的方法的所有数据。beforeInvocation:默认为false,在调用方法之后移除数据,当为true时,会在调用方法之前移除数据。
@Cacheing组合注解:推荐
// 将userId、username、userAge放到名为user的缓存中存起来
@Caching(
put = {
@CachePut(value = "user", key = "#userId"),
@CachePut(value = "user", key = "#username"),
@CachePut(value = "user", key = "#userAge"),
}
)
@Conditional
有没有遇到过这些问题:
- 某个功能需要根据项目中有没有某个jar判断是否开启该功能。
- 某个bean的实例化需要先判断另一个bean有没有实例化,再判断是否实例化自己。
- 某个功能是否开启,在配置文件中有个参数可以对它进行控制。
@ConditionalOnClass
某个功能需要根据项目中有没有某个jar判断是否开启该功能,可以用
@ConditionalOnClass注解解决。
public class A {
}
public class B {
}
@ConditionalOnClass(B.class)
@Configuration
public class TestConfiguration {
@Bean
public A a() {
return new A();
}
}
如果项目中存在B类,则会实例化A类。如果不存在B类,则不会实例化A类。
可能会问:不是判断有没有某个jar吗?怎么现在判断某个类了?
直接判断有没有该jar下的某个关键类更简单。
这个注解有个升级版的应用场景:比如common工程中写了一个发消息的工具类mqTemplate,业务工程引用了common工程,只需再引入消息中间件,比如rocketmq的jar包,就能开启mqTemplate的功能。而如果有另一个业务工程,通用引用了common工程,如果不需要发消息的功能,不引入rocketmq的jar包即可。
@ConditionalOnBean
某个bean的实例化需要先判断另一个bean有没有实例化,再判断是否实例化自己。可以通过
@ConditionalOnBean注解解决。
@Configuration
public class TestConfiguration {
@Bean
public B b() {
return new B();
}
@ConditionalOnBean(name="b")
@Bean
public A a() {
return new A();
}
}
实例A只有在实例B存在时,才能实例化。
@ConditionalOnProperty
某个功能是否开启,在配置文件中有个参数可以对它进行控制。可以通过
@ConditionalOnProperty注解解决
applicationContext.properties文件中配置参数:
demo.enable=false
@ConditionalOnProperty(
prefix = "demo", // 表示参数名的前缀
name = "enable", // 表示参数名
havingValue = "true", // 表示指定的值,参数中配置的值需要跟指定的值比较是否相等,相等才满足条件
matchIfMissing = true // 表示是否允许缺省配置
)
@Configuration
public class TestConfiguration {
@Bean
public A a() {
return new A();
}
}
这个功能可以作为开关,相比EnableXXX注解的开关更优雅,因为它可以通过参数配置是否开启,而EnableXXX注解的开关需要在代码中硬编码开启或关闭。
其他的Conditional注解
Spring用得比较多的Conditional注解还有:ConditionalOnMissingClass、ConditionalOnMissingBean、ConditionalOnWebApplication等。
整体认识一下@Conditional家族:

自定义Conditional
Spring Boot自带的Conditional系列已经可以满足我们绝大多数的需求了。但如果你有比较特殊的场景,也可以自定义自定义Conditional。
- 自定义注解
@Conditional(MyCondition.class)
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
@Documented
public @interface MyConditionOnProperty {
String name() default "";
String havingValue() default "";
}
- 实现Condition接口
public class MyCondition implements Condition {
@Override
public boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata) {
System.out.println("实现自定义逻辑");
return false;
}
}
- 使用
@MyConditionOnProperty注解
Conditional的奥秘就藏在ConfigurationClassParser类的processConfigurationClass方法中:


- 先判断有没有使用Conditional注解,如果没有直接返回false
- 收集condition到集合中
- 按
order排序该集合 - 遍历该集合,循环调用
condition的matchs方法。
@Import
有时我们需要在某个配置类中引入另外一些类,被引入的类也加到Spring容器中。这时可以使用
@Import注解完成这个功能。
引入的类支持三种不同类型:最好将普通类和@Configuration注解的配置类分开讲解,所以列了四种不同类型

这四种引入类的方式各有千秋,总结如下:
- 普通类,用于创建没有特殊要求的bean实例。
@Configuration注解的配置类,用于层层嵌套引入的场景。- 实现ImportSelector接口的类,用于一次性引入多个类的场景,或者可以根据不同的配置决定引入不同类的场景。
- 实现ImportBeanDefinitionRegistrar接口的类,主要用于可以手动控制BeanDefinition的创建和注册的场景,它的方法中可以获取BeanDefinitionRegistry注册容器对象。
在ConfigurationClassParser类的processImports方法中可以看到这三种方式的处理逻辑:

最后的else方法其实包含了:普通类和@Configuration注解的配置类两种不同的处理逻辑。
普通类
Spring4.2之后
@Import注解可以实例化普通类的bean实例,即被引入的类会被实例化bean对象
public class A {
}
@Import(A.class)
@Configuration
public class TestConfiguration {
}
通过@Import注解引入A类,Spring就能自动实例化A对象,然后在需要使用的地方通过@Autowired注解注入即可:
@Autowired
private A a;
问题:
@Import注解能定义单个类的bean,但如果有多个类需要定义bean该怎么办?
其实@Import注解也支持:
@Import({Role.class, User.class})
@Configuration
public class MyConfig {
}
甚至,如果想偷懒,不想写这种MyConfig类,Spring Boot也欢迎:
@Import({Role.class, User.class})
@SpringBootApplication(
exclude = {
DataSourceAutoConfiguration.class,
DataSourceTransactionManagerAutoConfiguration.class
}
)
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(WebApplicationType.SERVLET).run(args);
}
}
这样也能生效?
Spring Boot的启动类一般都会加@SpringBootApplication注解,该注解上加了@SpringBootConfiguration注解。

而@SpringBootConfiguration注解,上面又加了@Configuration注解,所以,Spring Boot启动类本身带有@Configuration注解的功能。
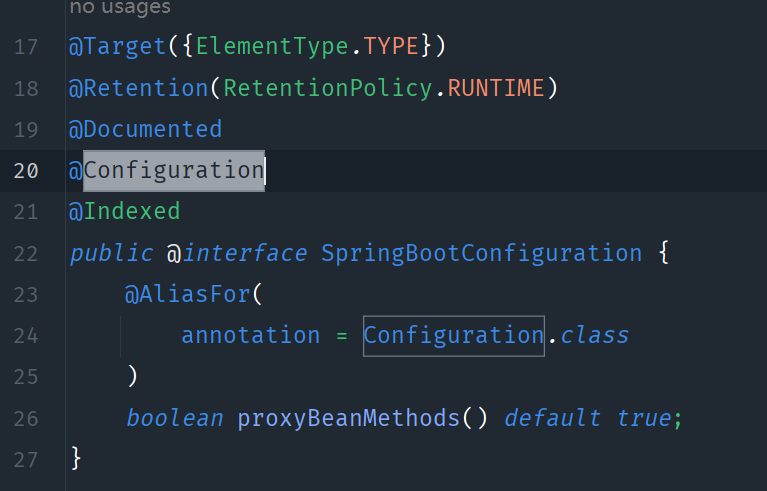
@Configuration 注解的配置类
缺点:不太适合加复杂的判断条件,根据某些条件定义这些bean,根据另外的条件定义那些bean
这种引入方式是最复杂的,因为@Configuration注解还支持多种组合注解,比如:
@Import@ImportResource@PropertySource等
public class A {
}
public class B {
}
@Import(B.class)
@Configuration
public class AConfiguration {
@Bean
public A a() {
return new A();
}
}
@Import(AConfiguration.class)
@Configuration
public class TestConfiguration {
}
通过@Import注解引入@Configuration注解的配置类,会把该配置类相关@Import、@ImportResource、@PropertySource等注解引入的类进行递归,一次性全部引入。
这种方式,如果AConfiguration类已经在Spring指定的扫描目录或者子目录下,则AConfiguration类会显得有点多余。因为AConfiguration类本身就是一个配置类,它里面就能定义bean。
但如果AConfiguration类不在指定的Spring扫描目录或者子目录下,则通过AConfiguration类的导入功能,也能把AConfiguration类识别成配置类。
拓展:swagger2是如何导入相关类的?
众所周知,我们引入swagger相关jar包之后,只需要在Spring Boot的启动类上加上@EnableSwagger2注解,就能开启swagger的功能。
其中@EnableSwagger2注解中导入了Swagger2DocumentationConfiguration类。

该类是一个Configuration类,它又导入了另外两个类:
- SpringfoxWebMvcConfiguration
- SwaggerCommonConfiguration

SpringfoxWebMvcConfiguration类又会导入新的Configuration类,并且通过@ComponentScan注解扫描了一些其他的路径。

SwaggerCommonConfiguration同样也通过@ComponentScan注解扫描了一些额外的路径。

如此一来,我们通过一个简单的@EnableSwagger2注解,就能轻松的导入swagger所需的一系列bean,并且拥有swagger的功能。
实现ImportSelector接口的类
上一节知道:@Configuration 注解配置的类不太适合加复杂的判断条件,根据某些条件定义这些bean,根据另外的条件定义那些bean。
而本节的实现ImportSelector接口的类就可以做到了。
这种引入方式需要实现
ImportSelector接口这种方式的好处是
selectImports方法返回的是数组,意味着可以同时引入多个类缺点:没法自定义bean的名称和作用域等属性
实现ImportSelector接口的好处主要有以下两点:
- 把某个功能的相关类,可以放到一起,方面管理和维护。
- 重写selectImports方法时,能够根据条件判断某些类是否需要被实例化,或者某个条件实例化这些bean,其他的条件实例化那些bean等。我们能够非常灵活的定制化bean的实例化。
public class AImportSelector implements ImportSelector {
private static final String CLASS_NAME = "com.zixq.cache.service.test13.A";
/**
* 指定需要定义bean的类名,注意要包含完整路径,而非相对路径
*/
@Override
public String[] selectImports(AnnotationMetadata importingClassMetadata) {
return new String[]{CLASS_NAME};
}
}
@Import(AImportSelector.class)
@Configuration
public class TestConfiguration {
}
ImportSelector接口相关:@EnableAutoConfiguration注解
@EnableAutoConfiguration注解中导入了AutoConfigurationImportSelector类,并且里面包含系统参数名称:Spring.boot.enableautoconfiguration。
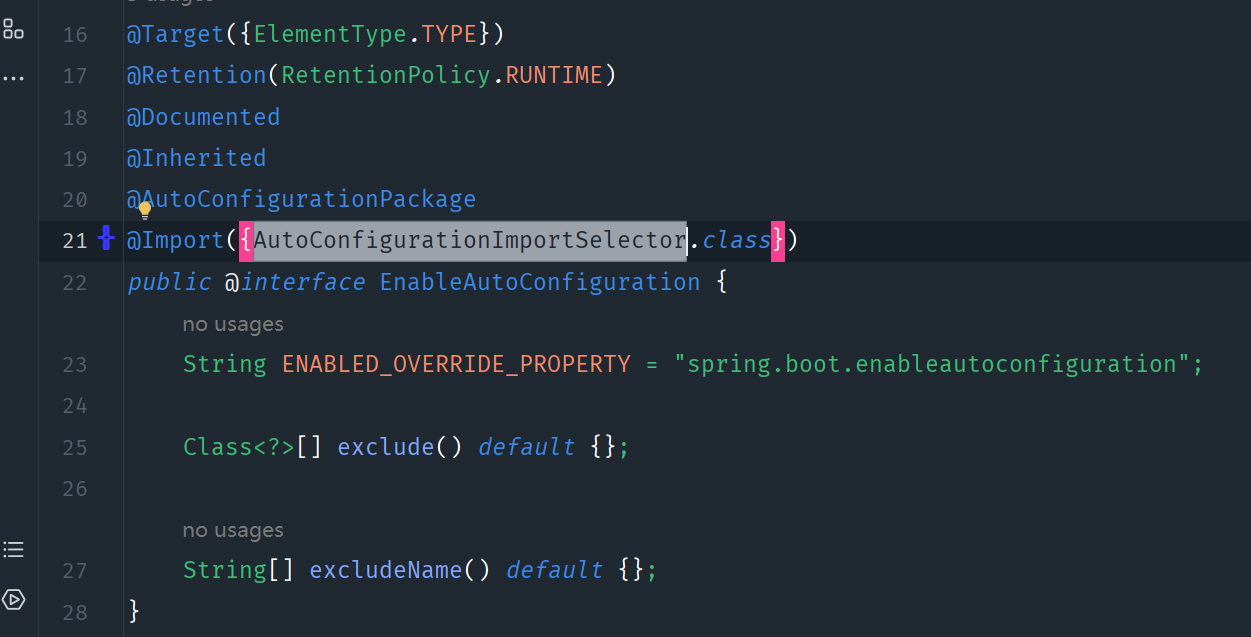
AutoConfigurationImportSelector类实现了ImportSelector接口。

并且重写了selectImports(AnnotationMetadata importingClassMetadata)方法,该方法会根据某些注解去找所有需要创建bean的类名,然后返回这些类名。其中在查找这些类名之前,先调用isEnabled方法,判断是否需要继续查找。

该方法会根据ENABLED_OVERRIDE_PROPERTY的值来作为判断条件。

而这个值就是Spring.boot.enableautoconfiguration。
换句话说,这里能根据系统参数控制bean是否需要被实例化
实现ImportBeanDefinitionRegistrar接口的类
由上一节知道:实现ImportSelector接口的方式没法自定义bean的名称和作用域等属性。
有需求,就有解决方案,通过本节的内容即可解决
这种引入方式需要实现
ImportBeanDefinitionRegistrar接口这种方式是最灵活的,能在
registerBeanDefinitions方法中获取到BeanDefinitionRegistry容器注册对象,可以手动控制BeanDefinition的创建和注册
public class AImportBeanDefinitionRegistrar implements ImportBeanDefinitionRegistrar {
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata,
BeanDefinitionRegistry registry) {
RootBeanDefinition rootBeanDefinition = new RootBeanDefinition(A.class);
registry.registerBeanDefinition("a", rootBeanDefinition);
}
}
@Import(AImportBeanDefinitionRegistrar.class)
@Configuration
public class TestConfiguration {
}
当然@import注解非常人性化,还支持同时引入多种不同类型的类。
@Import({B.class, AImportBeanDefinitionRegistrar.class})
@Configuration
public class TestConfiguration {
}
我们所熟悉的fegin功能,就是使用ImportBeanDefinitionRegistrar接口实现的:

@ConfigurationProperties赋值
@ConfigurationProperties是Spring Boot中新加的注解
在项目中使用配置参数是非常常见的场景,比如,我们在配置线程池的时候,需要在applicationContext.propeties文件中定义如下配置:
thread.pool.corePoolSize=5
thread.pool.maxPoolSize=10
thread.pool.queueCapacity=200
thread.pool.keepAliveSeconds=30
第一种方式:通过@Value注解读取这些配置。适合参数少的情况
缺点:@Value注解定义的参数看起来有点分散,不容易辨别哪些参数是一组的
建议在使用时都加上
:,因为:后面跟的是默认值,比如:@Value("${thread.pool.corePoolSize:5}"),定义的默认核心线程数是5
假如有这样的场景:business工程下定义了这个ThreadPoolConfig类,api工程引用了business工程,同时job工程也引用了business工程,而ThreadPoolConfig类只想在api工程中使用。这时,如果不配置默认值,job工程启动的时候可能会报错
public class ThreadPoolConfig {
@Value("${thread.pool.corePoolSize:5}")
private int corePoolSize;
@Value("${thread.pool.maxPoolSize:10}")
private int maxPoolSize;
@Value("${thread.pool.queueCapacity:200}")
private int queueCapacity;
@Value("${thread.pool.keepAliveSeconds:30}")
private int keepAliveSeconds;
@Value("${thread.pool.threadNamePrefix:ASYNC_}")
private String threadNamePrefix;
@Bean
public Executor threadPoolExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(maxPoolSize);
executor.setQueueCapacity(queueCapacity);
executor.setKeepAliveSeconds(keepAliveSeconds);
executor.setThreadNamePrefix(threadNamePrefix);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.initialize();
return executor;
}
}
第二种方式:@ConfigurationProperties注解
- 定义ThreadPoolProperties类
@Data
@Component
@ConfigurationProperties("thread.pool")
public class ThreadPoolProperties {
private int corePoolSize;
private int maxPoolSize;
private int queueCapacity;
private int keepAliveSeconds;
private String threadNamePrefix;
}
- 使用ThreadPoolProperties类
@Configuration
public class ThreadPoolConfig {
@Autowired
private ThreadPoolProperties threadPoolProperties;
@Bean
public Executor threadPoolExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(threadPoolProperties.getCorePoolSize());
executor.setMaxPoolSize(threadPoolProperties.getMaxPoolSize());
executor.setQueueCapacity(threadPoolProperties.getQueueCapacity());
executor.setKeepAliveSeconds(threadPoolProperties.getKeepAliveSeconds());
executor.setThreadNamePrefix(threadPoolProperties.getThreadNamePrefix());
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.initialize();
return executor;
}
}
这种方式要方便很多,我们只需编写xxxProperties类,Spring会自动装配参数。此外,不同系列的参数可以定义不同的xxxProperties类,也便于管理,推荐优先使用这种方式。
底层是通过:ConfigurationPropertiesBindingPostProcessor类实现的,该类实现了BeanPostProcessor接口,在postProcessBeforeInitialization方法中解析@ConfigurationProperties注解,并且绑定数据到相应的对象上。
绑定是通过Binder类的bindObject方法完成的:

以上这段代码会递归绑定数据,主要考虑了三种情况:
bindAggregate绑定集合类bindBean绑定对象bindProperty绑定参数 前面两种情况最终也会调用到bindProperty方法。
@ConfigurationProperties对应参数动态更新问题
使用@ConfigurationProperties注解有些场景有问题,比如:在apollo中修改了某个参数,正常情况可以动态更新到@ConfigurationProperties注解定义的xxxProperties类的对象中,但是如果出现比较复杂的对象,比如:
private Map<String, Map<String,String>> urls;
可能动态更新不了。这时候该怎么办呢?
答案是使用ApolloConfigChangeListener监听器自己处理:
@ConditionalOnClass(com.ctrip.framework.apollo.Spring.annotation.EnableApolloConfig.class)
public class ApolloConfigurationAutoRefresh implements ApplicationContextAware {
private ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
@ApolloConfigChangeListener
private void onChange(ConfigChangeEvent changeEvent) {
refreshConfig(changeEvent.changedKeys());
}
private void refreshConfig(Set<String> changedKeys){
System.out.println("将变更的参数更新到相应的对象中");
}
}
Spring事务
需要同时写入多张表的数据。为了保证操作的原子性(要么同时成功,要么同时失败),避免数据不一致的情况,我们一般都会用到Spring事务(也会选择其他事务框架)。
Spring事务用起来贼爽,就用一个简单的注解:@Transactional,就能轻松搞定事务。而且一直用一直爽。
但如果使用不当,它也会坑人于无形。

事务不生效
访问权限问题
Java的访问权限主要有四种:private、default、protected、public,它们的权限从左到右,依次变大。
在开发过程中,把某些事务方法,定义了错误的访问权限,就会导致事务功能出问题。
@Service
public class UserService {
@Transactional
private void add(UserModel userModel) {
saveData(userModel);
updateData(userModel);
}
}
上述代码就会导致事务失效,因为Spring要求被代理方法必须是public的。
在 AbstractFallbackTransactionAttributeSource 类的 computeTransactionAttribute 方法中有个判断,如果目标方法不是public,则TransactionAttribute返回null,即不支持事务。
protected TransactionAttribute computeTransactionAttribute(Method method, @Nullable Class<?> targetClass) {
// Don't allow no-public methods as required.
if (allowPublicMethodsOnly() && !Modifier.isPublic(method.getModifiers())) {
return null;
}
// The method may be on an interface, but we need attributes from the target class.
// If the target class is null, the method will be unchanged.
Method specificMethod = AopUtils.getMostSpecificMethod(method, targetClass);
// First try is the method in the target class.
TransactionAttribute txAttr = findTransactionAttribute(specificMethod);
if (txAttr != null) {
return txAttr;
}
// Second try is the transaction attribute on the target class.
txAttr = findTransactionAttribute(specificMethod.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
return txAttr;
}
if (specificMethod != method) {
// Fallback is to look at the original method.
txAttr = findTransactionAttribute(method);
if (txAttr != null) {
return txAttr;
}
// Last fallback is the class of the original method.
txAttr = findTransactionAttribute(method.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
return txAttr;
}
}
return null;
}
方法用final修饰
有时候,某个方法不想被子类重新,这时可以将该方法定义成final的。普通方法这样定义是没问题的,但如果将事务方法定义成final就会导致事务失效。
@Service
public class UserService {
@Transactional
public final void add(UserModel userModel){
saveData(userModel);
updateData(userModel);
}
}
因为Spring事务底层使用了AOP帮我们生成代理类,在代理类中实现的事务功能。如果某个方法用final修饰了,那么在它的代理类中,就无法重写该方法,而添加事务功能。
重要提示
如果某个方法是static的,同样无法通过动态代理,变成事务方法。
方法内部调用
有时需要在某个Service类的某个事务方法中调用另外一个事务方法。
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
@Transactional
public void add(UserModel userModel) {
userMapper.insertUser(userModel);
updateStatus(userModel);
}
@Transactional
public void updateStatus(UserModel userModel) {
doSameThing();
}
}
上述代码就会导致事务失效,因为updateStatus方法拥有事务的能力是Spring AOP生成代理对象,但是updateStatus这种方法直接调用了this对象的方法,所以updateStatus方法不会生成事务。
如果有些场景,确实想在同一个类的某个方法中,调用它自己的另外一个方法,该怎么办?
- 第一种方式:新加一个Service方法。把
@Transactional注解加到新Service方法上,把需要事务执行的代码移到新方法中。
@Servcie
public class ServiceA {
@Autowired
prvate ServiceB serviceB;
public void save(User user) {
queryData1();
queryData2();
serviceB.doSave(user);
}
}
@Servcie
public class ServiceB {
@Transactional(rollbackFor=Exception.class)
public void doSave(User user) {
addData1();
updateData2();
}
}
- 第二种方式:在该Service类中注入自己。如果不想再新加一个Service类,在该Service类中注入自己也是一种选择。
@Servcie
public class ServiceA {
@Autowired
prvate ServiceA serviceA;
public void save(User user) {
queryData1();
queryData2();
serviceA.doSave(user);
}
@Transactional(rollbackFor=Exception.class)
public void doSave(User user) {
addData1();
updateData2();
}
}
第二种做法会不会出现循环依赖问题?
不会。Spring IOC内部的三级缓存保证了它,不会出现循环依赖问题。但有些坑,解放方式去参考:Spring:如何解决循环依赖
循环依赖:就是一个或多个对象实例之间存在直接或间接的依赖关系,这种依赖关系构成了构成一个环形调用。
第一种情况:自己依赖自己的直接依赖。

第二种情况:两个对象之间的直接依赖。

第三种情况:多个对象之间的间接依赖。
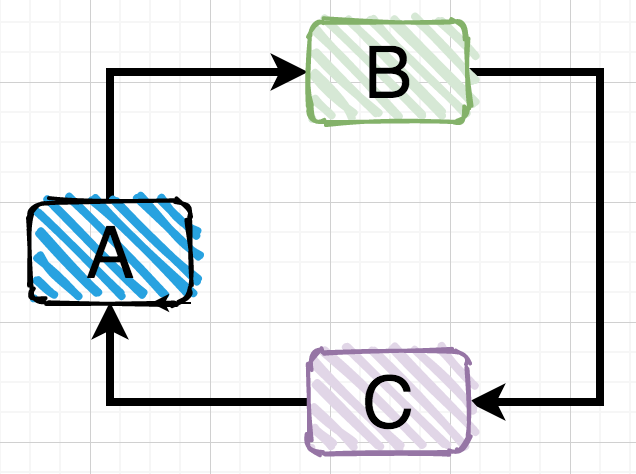
前面两种情况的直接循环依赖比较直观,非常好识别,但是第三种间接循环依赖的情况有时候因为业务代码调用层级很深,不容易识别出来。
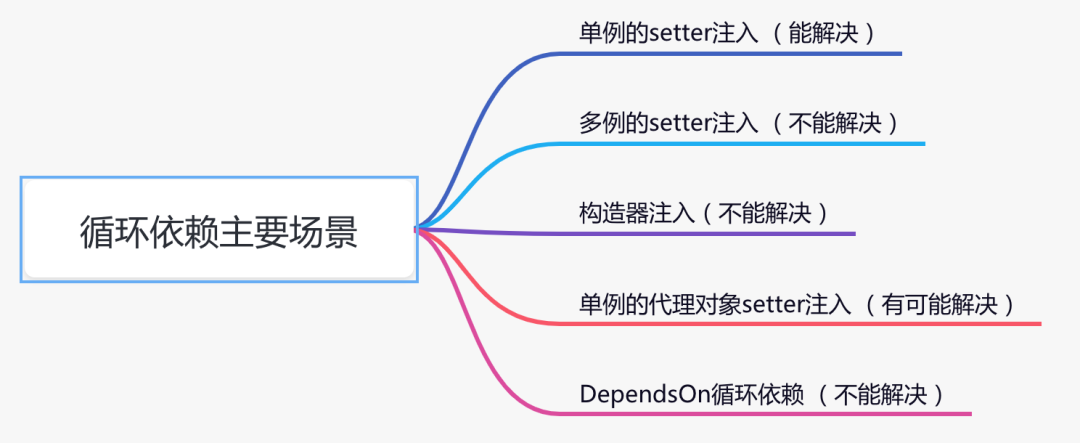
循环依赖的N种场景
- 第三种方式:通过AopContent类。在该Service类中使用
AopContext.currentProxy()获取代理对象。
上面第二种方式确实可以解决问题,但是代码看起来并不直观,还可以通过在该Service类中使用AOPProxy获取代理对象,实现相同的功能。
@Servcie
public class ServiceA {
public void save(User user) {
queryData1();
queryData2();
((ServiceA)AopContext.currentProxy()).doSave(user);
}
@Transactional(rollbackFor=Exception.class)
public void doSave(User user) {
addData1();
updateData2();
}
}
未被Spring托管
使用Spring事务的前提是:对象要被Spring管理,需要创建bean实例。
通常情况下,我们通过@Controller、@Service、@Component、@Repository等注解,可以自动实现bean实例化和依赖注入的功能。
但要是噼里啪啦敲完Service类,忘了加 @Service 注解呢?
那么该类不会交给Spring管理,它的方法也不会生成事务。
多线程调用
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
@Autowired
private RoleService roleService;
@Transactional
public void add(UserModel userModel) throws Exception {
userMapper.insertUser(userModel);
new Thread(() -> {
roleService.doOtherThing();
}).start();
}
}
@Service
public class RoleService {
@Transactional
public void doOtherThing() {
System.out.println("保存role表数据");
}
}
上述代码事务方法add中是另外一个线程调用的事务方法doOtherThing。
这样会导致两个方法不在同一个线程中,获取到的数据库连接不一样,从而是两个不同的事务。如果想doOtherThing方法中抛了异常,add方法也回滚是不可能的。
Spring事务其实是通过数据库连接来实现的。当前线程中保存了一个map,key是数据源,value是数据库连接。
private static final ThreadLocal<Map<Object, Object>> resources =
new NamedThreadLocal<>("Transactional resources");
我们说的同一个事务,其实是指同一个数据库连接,只有拥有同一个数据库连接才能同时提交和回滚。如果在不同的线程,拿到的数据库连接肯定是不一样的,所以是不同的事务。
表不支持事务
MySQL 5之前,默认的数据库引擎是myisam。好处是:索引文件和数据文件是分开存储的,对于查多写少的单表操作,性能比innodb更好。
但有个很致命的问题是:不支持事务。如果需要跨多张表操作,由于其不支持事务,数据极有可能会出现不完整的情况。
提示
有时候我们在开发的过程中,发现某张表的事务一直都没有生效,那不一定是Spring事务的锅,最好确认一下你使用的那张表,是否支持事务。
未开启事务
有时候,事务没有生效的根本原因是没有开启事务。
看到这句话可能会觉得好笑。因为开启事务不是一个项目中,最最最基本的功能吗?为什么还会没有开启事务?
如果使用的是Spring Boot项目,那很幸运。因为Spring Boot通过 DataSourceTransactionManagerAutoConfiguration 类,已经默默的帮忙开启了事务。自己所要做的事情很简单,只需要配置Spring.datasource相关参数即可。
但如果使用的还是传统的Spring项目,则需要在applicationContext.xml文件中,手动配置事务相关参数。如果忘了配置,事务肯定是不会生效的。
<!-- 配置事务管理器 -->
<bean class="org.Springframework.jdbc.datasource.DataSourceTransactionManager" id="transactionManager">
<property name="dataSource" ref="dataSource"></property>
</bean>
<tx:advice id="advice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="*" propagation="REQUIRED"/>
</tx:attributes>
</tx:advice>
<!-- 用切点把事务切进去 -->
<aop:config>
<aop:pointcut expression="execution(* com.zixieqing.*.*(..))" id="pointcut"/>
<aop:advisor advice-ref="advice" pointcut-ref="pointcut"/>
</aop:config>
注意
如果在pointcut标签中的切入点匹配规则配错了的话,有些类的事务也不会生效。
事务不回滚
错误的传播特性
在使用@Transactional注解时,是可以指定propagation参数的。
该参数的作用是指定事务的传播特性,Spring目前支持7种传播特性:
REQUIRED如果当前上下文中存在事务,那么加入该事务,如果不存在事务,创建一个事务,这是默认的传播属性值。REQUIRES_NEW每次都会新建一个事务,并且同时将上下文中的事务挂起,执行当前新建事务完成以后,上下文事务恢复再执行。NESTED如果当前上下文中存在事务,则嵌套事务执行,如果不存在事务,则新建事务。SUPPORTS如果当前上下文存在事务,则支持事务加入事务,如果不存在事务,则使用非事务的方式执行。MANDATORY如果当前上下文中存在事务,否则抛出异常。NOT_SUPPORTED如果当前上下文中存在事务,则挂起当前事务,然后新的方法在没有事务的环境中执行。NEVER如果当前上下文中存在事务,则抛出异常,否则在无事务环境上执行代码。
如果我们在手动设置propagation参数的时候,把传播特性设置错了就会出问题。
@Service
public class UserService {
// Propagation.NEVER 这种类型的传播特性不支持事务,如果有事务则会抛异常
@Transactional(propagation = Propagation.NEVER)
public void add(UserModel userModel) {
saveData(userModel);
updateData(userModel);
}
}
目前只有这三种传播特性才会创建新事务:REQUIRED,REQUIRES_NEW,NESTED。
自己吞了异常
事务不会回滚,最常见的问题是:开发者在代码中手动try...catch了异常。
@Slf4j
@Service
public class UserService {
@Transactional
public void add(UserModel userModel) {
try {
saveData(userModel);
updateData(userModel);
} catch (Exception e) {
log.error(e.getMessage(), e);
}
}
}
这种情况下Spring事务当然不会回滚,因为开发者自己捕获了异常,又没有手动抛出,换句话说就是把异常吞掉了。
如果想要Spring事务能够正常回滚,必须抛出它能够处理的异常。如果没有抛异常,则Spring认为程序是正常的。
手动抛了别的异常
即使开发者没有手动捕获异常,但如果抛的异常不正确,Spring事务也不会回滚。
@Slf4j
@Service
public class UserService {
@Transactional
public void add(UserModel userModel) throws Exception {
try {
saveData(userModel);
updateData(userModel);
} catch (Exception e) {
log.error(e.getMessage(), e);
throw new Exception(e);
}
}
}
手动抛出了异常:Exception,事务同样不会回滚。
因为Spring事务,默认情况下只会回滚RuntimeException(运行时异常)和Error(错误),对于普通的Exception(非运行时异常),它不会回滚。
自定义了回滚异常
在使用@Transactional注解声明事务时,有时我们想自定义回滚的异常,Spring也是支持的。可以通过设置rollbackFor参数,来完成这个功能。
但如果这个参数的值设置错了,就会引出一些莫名其妙的问题,
@Service
public class UserService {
@Transactional(rollbackFor = BusinessException.class)
public void add(UserModel userModel) throws Exception {
saveData(userModel);
updateData(userModel);
}
}
如果在执行上面这段代码,保存和更新数据时,程序报错了,抛了SqlException、DuplicateKeyException等异常。而BusinessException是我们自定义的异常,报错的异常不属于BusinessException,所以事务也不会回滚。
即使rollbackFor有默认值,但阿里巴巴开发者规范中,还是要求开发者重新指定该参数。why?
因为如果使用默认值,一旦程序抛出了Exception,事务不会回滚,这会出现很大的bug。所以,建议一般情况下,将该参数设置成:Exception或Throwable。
嵌套事务回滚多了
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
@Autowired
private RoleService roleService;
@Transactional
public void add(UserModel userModel) throws Exception {
userMapper.insertUser(userModel);
roleService.doOtherThing();
}
}
@Service
public class RoleService {
@Transactional(propagation = Propagation.NESTED)
public void doOtherThing() {
System.out.println("保存role表数据");
}
}
这种情况使用了嵌套的内部事务,原本是希望调用roleService.doOtherThing()方法时,如果出现了异常,只回滚doOtherThing方法里的内容,不回滚 userMapper.insertUser里的内容,即回滚保存点。。但事实是,insertUser也回滚了。why?
因为doOtherThing方法出现了异常,没有手动捕获,会继续往上抛,到外层add方法的代理方法中捕获了异常。所以,这种情况是直接回滚了整个事务,不只回滚单个保存点。
怎么样才能只回滚保存点?
将内部嵌套事务放在try/catch中,并且不继续往上抛异常。这样就能保证,如果内部嵌套事务中出现异常,只回滚内部事务,而不影响外部事务。
@Slf4j
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
@Autowired
private RoleService roleService;
@Transactional
public void add(UserModel userModel) throws Exception {
userMapper.insertUser(userModel);
try {
roleService.doOtherThing();
} catch (Exception e) {
log.error(e.getMessage(), e);
}
}
}
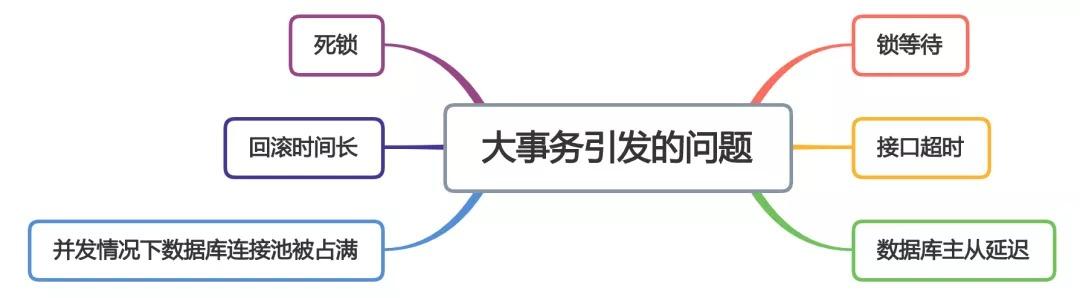
大事务问题
在使用Spring事务时,有个让人非常头疼的问题,就是大事务问题。
通常情况下,我们会在方法上@Transactional注解,填加事务功能,
但@Transactional注解,如果被加到方法上,有个缺点就是整个方法都包含在事务当中了。
@Service
public class UserService {
@Autowired
private RoleService roleService;
@Transactional
public void add(UserModel userModel) throws Exception {
query1();
query2();
query3();
roleService.save(userModel);
update(userModel);
}
}
@Service
public class RoleService {
@Autowired
private RoleService roleService;
@Transactional
public void save(UserModel userModel) throws Exception {
query4();
query5();
query6();
saveData(userModel);
}
}
上述代码,在UserService类中,其实只有这两行才需要事务:
roleService.save(userModel);
update(userModel);
在RoleService类中,只有这一行需要事务:
saveData(userModel);
而上面的写法会导致所有的query方法也被包含在同一个事务当中。
如果query方法非常多,调用层级很深,而且有部分查询方法比较耗时的话,会造成整个事务非常耗时,从而造成大事务问题。
编程式事务
上面这些内容都是基于@Transactional注解的,主要说的是它的事务问题,我们把这种事务叫做:声明式事务。
其实,Spring还提供了另外一种创建事务的方式,即通过手动编写代码实现的事务,我们把这种事务叫做:编程式事务。
在Spring中为了支持编程式事务,专门提供了一个类:TransactionTemplate,在它的execute()方法中,就实现了事务的功能。
@Autowired
private TransactionTemplate transactionTemplate;
...
public void save(final User user) {
queryData1();
queryData2();
transactionTemplate.execute((status) => {
addData1();
updateData2();
return Boolean.TRUE;
})
}
相较于@Transactional注解声明式事务,我更建议大家使用,基于TransactionTemplate的编程式事务。主要原因如下:
- 避免由于Spring AOP问题,导致事务失效的问题。
- 能够更小粒度的控制事务的范围,更直观。
提示
建议在项目中少使用
@Transactional注解开启事务。但并不是说一定不能用它,如果项目中有些业务逻辑比较简单,而且不经常变动,使用@Transactional注解开启事务开启事务也无妨,因为它更简单,开发效率更高,但是千万要小心事务失效的问题。
跨域问题
关于跨域问题,前后端的解决方案还是挺多的,这里我重点说说Spring的解决方案,目前有三种:

使用@CrossOrigin注解 和 实现WebMvcConfigurer接口的方案,Spring在底层最终都会调用到DefaultCorsProcessor类的handleInternal方法

最终三种方案殊途同归,都会往header中添加跨域需要参数,只是实现形式不一样而已。
使用@CrossOrigin注解
该方案需要在跨域访问的接口上加
@CrossOrigin注解,访问规则可以通过注解中的参数控制,控制粒度更细。如果需要跨域访问的接口数量较少,可以使用该方案。
@RequestMapping("/user")
@RestController
public class UserController {
@CrossOrigin(origins = "http://localhost:8016")
@RequestMapping("/getUser")
public String getUser(@RequestParam("name") String name) {
System.out.println("name:" + name);
return "success";
}
}
全局配置
实现
WebMvcConfigurer接口,重写addCorsMappings方法,在该方法中定义跨域访问的规则。这是一个全局的配置,可以应用于所有接口。
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")
.allowedOrigins("*")
.allowedMethods("GET", "POST")
.allowCredentials(true)
.maxAge(3600)
.allowedHeaders("*");
}
}
自定义过滤器
通过在请求的
header中增加Access-Control-Allow-Origin等参数解决跨域问题。
@WebFilter("corsFilter")
@Configuration
public class CorsFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
HttpServletResponse httpServletResponse = (HttpServletResponse) response;
httpServletResponse.setHeader("Access-Control-Allow-Origin", "*");
httpServletResponse.setHeader("Access-Control-Allow-Methods", "POST, GET");
httpServletResponse.setHeader("Access-Control-Max-Age", "3600");
httpServletResponse.setHeader("Access-Control-Allow-Headers", "x-requested-with");
chain.doFilter(request, response);
}
@Override
public void destroy() {
}
}
Spring中定义bean的方法
Spring是创建和管理bean的工厂,它提供了多种定义bean的方式,能够满足我们日常工作中的多种业务场景。
一般常见的是下图三种:

xml文件配置bean
这是Spring最早支持的方式。后来,随着Spring Boot越来越受欢迎,该方法目前已经用得很少了,
构造器
如果之前有在bean.xml文件中配置过bean的经历,那么对如下的配置肯定不会陌生:
<bean id="personService" class="com.zixq.cache.service.test7.PersonService">
</bean>
这种方式是以前使用最多的方式,它默认使用了无参构造器创建bean。
当然还可以使用有参的构造器,通过<constructor-arg>标签来完成配置。
<bean id="personService" class="com.zixq.cache.service.test7.PersonService">
<constructor-arg index="0" value="zixq"></constructor-arg>
<constructor-arg index="1" ref="baseInfo"></constructor-arg>
</bean>
其中:
index表示下标,从0开始。value表示常量值ref表示引用另一个bean
setter方法
Spring还提供了另外一种思路:通过setter方法设置bean所需参数,这种方式耦合性相对较低,比有参构造器使用更为广泛。
先定义Person实体:
@Data
public class Person {
private String name;
private int age;
}
它里面包含:成员变量name和age,getter/setter方法。
然后在bean.xml文件中配置bean时,加上<property>标签设置bean所需参数。
<bean id="person" class="com.zixq.cache.service.test7.Person">
<property name="name" value="zixq" />
<property name="age" value="18" />
</bean>
静态工厂
这种方式的关键是需要定义一个工厂类,它里面包含一个创建bean的静态方法
public class ZixqBeanFactory {
public static Person createPerson(String name, int age) {
return new Person(name, age);
}
}
接下来定义Person类如下:
@AllArgsConstructor
@NoArgsConstructor
@Data
public class Person {
private String name;
private int age;
}
它里面包含:成员变量name和age,getter/setter方法,无参构造器和全参构造器。
然后在bean.xml文件中配置bean时,通过factory-method参数指定静态工厂方法,同时通过<constructor-arg>设置相关参数。
<bean class="com.zixq.cache.service.test7.ZixqBeanFactory" factory-method="createPerson">
<constructor-arg index="0" value="zixq"></constructor-arg>
<constructor-arg index="1" value="18"></constructor-arg>
</bean>
实例工厂方法
这种方式也需要定义一个工厂类,但里面包含非静态的创建bean的方法
public class ZixqBeanFactory {
public Person createPerson(String name, int age) {
return new Person(name, age);
}
}
Person类跟上面一样
然后bean.xml文件中配置bean时,需要先配置工厂bean。然后在配置实例bean时,通过factory-bean参数指定该工厂bean的引用。
<bean id="susanBeanFactory" class="com.zixq.cache.service.test7.SusanBeanFactory">
</bean>
<bean factory-bean="ZixqBeanFactory" factory-method="createPerson">
<constructor-arg index="0" value="zixq"></constructor-arg>
<constructor-arg index="1" value="18"></constructor-arg>
</bean>
FactoryBean
上面的实例工厂方法每次都需要创建一个工厂类,不方面统一管理。这时就可以使用FactoryBean接口。
public class UserFactoryBean implements FactoryBean<User> {
/**
* 实现我们自己的逻辑创建对象
*/
@Override
public User getObject() throws Exception {
return new User();
}
/**
* 定义对象的类型
*/
@Override
public Class<?> getObjectType() {
return User.class;
}
}
然后在bean.xml文件中配置bean时,只需像普通的bean一样配置即可。
<bean id="userFactoryBean" class="com.zixq.async.service.UserFactoryBean">
</bean>
注意:
getBean("userFactoryBean");获取的是getObject方法中返回的对象;
getBean("&userFactoryBean");获取的才是真正的UserFactoryBean对象。
通过上面五种方式,在bean.xml文件中把bean配置好之后,Spring就会自动扫描和解析相应的标签,并且帮我们创建和实例化bean,然后放入Spring容器中。
但如果遇到比较复杂的项目,则需要配置大量的bean,而且bean之间的关系错综复杂,这样久而久之会导致xml文件迅速膨胀,非常不利于bean的管理。
@Component 注解
为了解决bean太多时,xml文件过大,从而导致膨胀不好维护的问题。在Spring2.5中开始支持:
@Component、@Repository、@Service、@Controller等注解定义bean。
这四种注解在功能上没有特别的区别,不过在业界有个不成文的约定:
@Controller一般用在控制层@Service一般用在业务层@Repository一般用在数据层@Component一般用在公共组件上
其实@Repository、@Service、@Controller三种注解也是@Component



提示
通过这种
@Component扫描注解的方式定义bean的前提是:需要先配置扫描路径。
目前常用的配置扫描路径的方式如下:
- 在
applicationContext.xml文件中使用<context:component-scan>标签。例如:
<context:component-scan base-package="com.zixq.cache" />
- 在Spring Boot的启动类上加上
@ComponentScan注解,例如:
@ComponentScan(basePackages = "com.zixq.cache")
@SpringBootApplication
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(WebApplicationType.SERVLET).run(args);
}
}
- 直接在
SpringBootApplication注解上加,它支持ComponentScan功能:
@SpringBootApplication(scanBasePackages = "com.zixq.cache")
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(WebApplicationType.SERVLET).run(args);
}
}
当然,如果你需要扫描的类跟Spring Boot的入口类,在同一级或者子级的包下面,无需指定scanBasePackages参数,Spring默认会从入口类的同一级或者子级的包去找。
@SpringBootApplication
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(WebApplicationType.SERVLET).run(args);
}
}
除了上述四种@Component注解之外,Springboot还增加了@RestController注解,它是一种特殊的@Controller注解,所以也是@Component注解。
@RestController还支持@ResponseBody注解的功能,即将接口响应数据的格式自动转换成JSON。

JavaConfig:@Configuration + @Bean
缺点:只能创建该类中定义的bean实例,不能创建其他类的bean实例
@Component系列注解虽说使用起来非常方便,但是bean的创建过程完全交给Spring容器来完成,我们没办法自己控制。
Spring从3.0以后,开始支持JavaConfig的方式定义bean。它可以看做Spring的配置文件,但并非真正的配置文件,我们需要通过编码Java代码的方式创建bean。例如:
@Configuration
public class MyConfiguration {
@Bean
public Person person() {
return new Person();
}
}
在JavaConfig类上加@Configuration注解,相当于配置了<beans>标签。而在方法上加@Bean注解,相当于配置了<bean>标签。
此外,Spring Boot还引入了一些列的@Conditional注解,用来控制bean的创建,这个注解前面已经说明了。
@Configuration
public class MyConfiguration {
@ConditionalOnClass(Country.class)
@Bean
public Person person() {
return new Person();
}
}
@Import 注解
这个内容前面已经讲了
前面介绍的@Configuration和@Bean相结合的方式,我们可以通过代码定义bean。但也知道它的缺点是:它只能创建该类中定义的bean实例,不能创建其他类的bean实例。如果我们想创建其他类的bean实例该怎么办?答案就是可以使用@Import注解导入
PostProcessor
Spring还提供了专门注册bean的接口:BeanDefinitionRegistryPostProcessor。
该接口的方法postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry)上有这样一段描述:

翻译:修改应用程序上下文的内部bean定义注册表标准初始化。所有常规bean定义都将被加载,但是还没有bean被实例化。这允许进一步添加在下一个后处理阶段开始之前定义bean。
如果用这个接口来定义bean,我们要做的事情就变得非常简单了。只需定义一个类实现BeanDefinitionRegistryPostProcessor接口。重写postProcessBeanDefinitionRegistry方法,在该方法中能够获取BeanDefinitionRegistry对象,它负责bean的注册工作。
@Component
public class MyRegistryPostProcessor implements BeanDefinitionRegistryPostProcessor {
/**
* BeanDefinitionRegistry 对象负责bean的注册工作
*/
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {
RootBeanDefinition roleBeanDefinition = new RootBeanDefinition(Role.class);
registry.registerBeanDefinition("role", roleBeanDefinition);
RootBeanDefinition userBeanDefinition = new RootBeanDefinition(User.class);
userBeanDefinition.setScope(ConfigurableBeanFactory.SCOPE_PROTOTYPE);
registry.registerBeanDefinition("user", userBeanDefinition);
}
/**
* 这个方法是它的父接口:BeanFactoryPostProcessor里的方法,所以可以啥都不做
*/
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
}
}

翻译:在应用程序上下文的标准bean工厂之后修改其内部bean工厂初始化。所有bean定义都已加载,但没有bean将被实例化。这允许重写或添加属性甚至可以初始化bean
@Component
public class MyPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
DefaultListableBeanFactory registry = (DefaultListableBeanFactory)beanFactory;
RootBeanDefinition roleBeanDefinition = new RootBeanDefinition(Role.class);
registry.registerBeanDefinition("role", roleBeanDefinition);
RootBeanDefinition userBeanDefinition = new RootBeanDefinition(User.class);
userBeanDefinition.setScope(ConfigurableBeanFactory.SCOPE_PROTOTYPE);
registry.registerBeanDefinition("user", userBeanDefinition);
}
}
问题:BeanDefinitionRegistryPostProcessor 接口 和 BeanFactoryPostProcessor 接口都能注册bean,那它们有什么区别?
- BeanDefinitionRegistryPostProcessor 更侧重于bean的注册
- BeanFactoryPostProcessor 虽然也可以注册bean,但更侧重于对已经注册的bean的属性进行修改。
问题:既然拿到BeanDefinitionRegistry对象就能注册bean,那通过BeanFactoryAware的方式是不是也能注册bean?
DefaultListableBeanFactory就实现了BeanDefinitionRegistry接口

这样一来,我们如果能够获取DefaultListableBeanFactory对象的实例,然后调用它的注册方法,不就可以注册bean了?
那就试试:定义一个类实现BeanFactoryAware接口,重写setBeanFactory方法,在该方法中能够获取BeanFactory对象,它能够强制转换成DefaultListableBeanFactory对象,然后通过该对象的实例注册bean。
@Component
public class BeanFactoryRegistry implements BeanFactoryAware {
/**
* 获取BeanFactory对象,它能够强制转换成DefaultListableBeanFactory对象,然后通过该对象的实例注册bean
*/
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
DefaultListableBeanFactory registry = (DefaultListableBeanFactory) beanFactory;
RootBeanDefinition rootBeanDefinition = new RootBeanDefinition(User.class);
registry.registerBeanDefinition("user", rootBeanDefinition);
RootBeanDefinition userBeanDefinition = new RootBeanDefinition(User.class);
userBeanDefinition.setScope(ConfigurableBeanFactory.SCOPE_PROTOTYPE);
registry.registerBeanDefinition("user", userBeanDefinition);
}
}
激动的心,颤抖的手,启动项目就一个错误怼在脸上

Why?这跟Spring中bean的创建过程顺序有关,大致如下:

BeanFactoryAware接口是在bean创建成功,并且完成依赖注入之后,在真正初始化之前才被调用的。在这个时候去注册bean意义不大,因为这个接口是给我们获取bean的,并不建议去注册bean,会引发很多问题。
提示
ApplicationContextRegistry 和 ApplicationListener接口也有类似的问题,我们可以用他们获取bean,但不建议用它们注册bean。
@Autowired 注解
@Autowired的默认装配
主要针对相同类型的对象只有一个的情况,此时对象类型是唯一的,可以找到正确的对象。
在Spring中@Autowired注解,是用来自动装配对象的。通常,我们在项目中是这样用的:
import org.springframework.stereotype.Service;
@Service
public class TestService1 {
public void test1() {
}
}
@Service
public class TestService2 {
@Autowired
private TestService1 testService1;
public void test2() {
}
}
没错,这样是能够装配成功的,因为默认情况下Spring是按照类型装配的,也就是我们所说的byType方式。
此外,@Autowired注解的required参数默认是true,表示开启自动装配,有些时候我们不想使用自动装配功能,可以将该参数设置成false。
相同类型的对象不只一个时
上面byType方式主要针对相同类型的对象只有一个的情况,此时对象类型是唯一的,可以找到正确的对象。
但如果相同类型的对象不只一个时,会发生什么?
建个同名的类TestService1:
import org.springframework.stereotype.Service;
@Service
public class TestService1 {
public void test1() {
}
}
重新启动项目时:
Caused by: org.springframework.context.annotation.ConflictingBeanDefinitionException: Annotation-specified bean name 'testService1' for bean class [com.sue.cache.service.test.TestService1] conflicts with existing, non-compatible bean definition of same name and class [com.sue.cache.service.TestService1]
结果报错了,报类类名称有冲突,直接导致项目启动不来。
注意
这种情况不是相同类型的对象在Autowired时有两个导致的,非常容易产生混淆。这种情况是因为Spring的
@Service方法不允许出现相同的类名,因为Spring会将类名的第一个字母转换成小写,作为bean的名称,比如:testService1,而默认情况下bean名称必须是唯一的。
下面看看什么情况会产生两个相同的类型bean:
public class TestService1 {
public void test1() {
}
}
@Service
public class TestService2 {
@Autowired
private TestService1 testService1;
public void test2() {
}
}
@Configuration
public class TestConfig {
@Bean("test1")
public TestService1 test1() {
return new TestService1();
}
@Bean("test2")
public TestService1 test2() {
return new TestService1();
}
}
在TestConfig类中手动创建TestService1实例,并且去掉TestService1类上原有的@Service注解。
重新启动项目:

果然报错了,提示testService1是单例的,却找到两个对象。
其实还有一个情况会产生两个相同的类型bean:
public interface IUser {
void say();
}
@Service
public class User1 implements IUser{
@Override
public void say() {
}
}
@Service
public class User2 implements IUser{
@Override
public void say() {
}
}
@Service
public class UserService {
@Autowired
private IUser user;
}
项目重新启动时:

报错了,提示跟上面一样,testService1是单例的,却找到两个对象。
第二种情况在实际的项目中出现得更多一些,后面的例子,我们主要针对第二种情况。
@Qualifier 和 @Primary
在Spring中,按照Autowired默认的装配方式:byType,是无法解决上面的问题的,这时可以改用按名称装配:byName。
在代码上加上@Qualifier注解即可:
@Service
public class UserService {
@Autowired
@Qualifier("user1")
private IUser user;
}
只需这样调整之后,项目就能正常启动了。
Qualifier意思是合格者,一般跟Autowired配合使用,需要指定一个bean的名称,通过bean名称就能找到需要装配的bean。
除了上面的@Qualifier注解之外,还能使用@Primary注解解决上面的问题。在User1上面加上@Primary注解:
@Primary
@Service
public class User1 implements IUser{
@Override
public void say() {
}
}
去掉UserService上的@Qualifier注解:
@Service
public class UserService {
@Autowired
private IUser user;
}
重新启动项目,一样能正常运行。
当我们使用自动配置的方式装配Bean时,如果这个Bean有多个候选者,假如其中一个候选者具有
@Primary注解修饰,该候选者会被选中,作为自动配置的值。
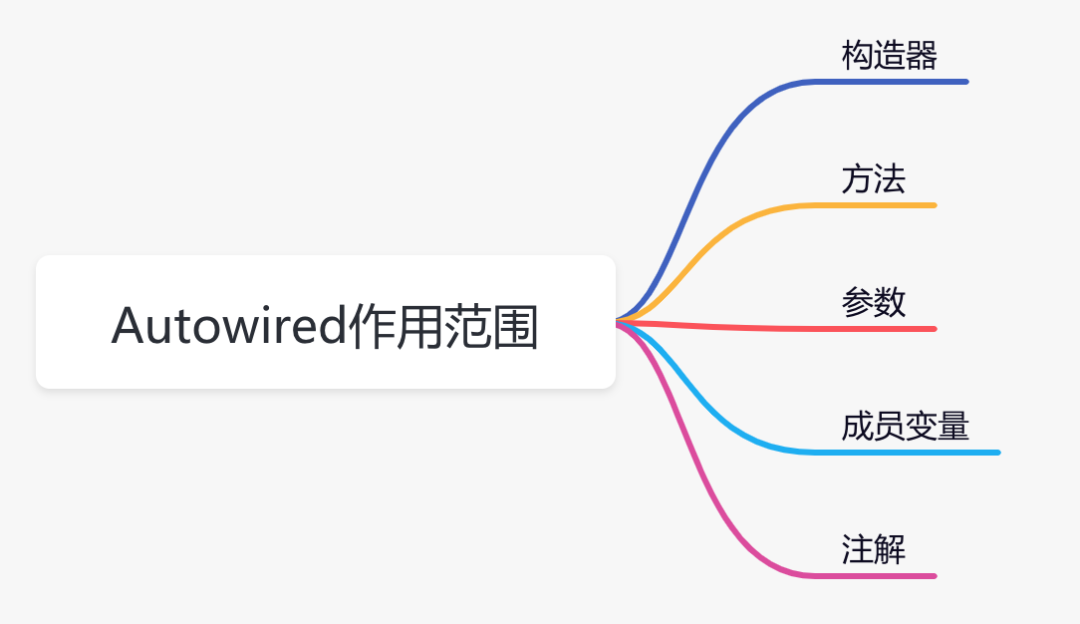
@Autowired的使用范围
上面的实例中@Autowired注解,都是使用在成员变量上,但@Autowired的强大之处,远非如此。
先看看@Autowired注解的定义:

从图中可以看出该注解能够使用在5种目标类型上,用一张图总结一下:
该注解我们平常使用最多的地方可能是在成员变量上。接下来,看看在其他地方该怎么用
成员变量上使用@Autowired
@Service
public class UserService {
@Autowired
private IUser user;
}
这种方式是平时用得最多的。
构造器上使用@Autowired
@Service
public class UserService {
private IUser user;
@Autowired
public UserService(IUser user) {
this.user = user;
System.out.println("user:" + user);
}
}
注意
在构造器上加
@Autowired注解,实际上还是使用了Autowired装配方式,并非构造器装配。
方法上使用@Autowired
@Service
public class UserService {
@Autowired
public void test(IUser user) {
user.say();
}
}
Spring会在项目启动的过程中,自动调用一次加了
@Autowired注解的方法,我们可以在该方法做一些初始化的工作。
也可以在setter方法上@Autowired注解:
@Service
public class UserService {
private IUser user;
@Autowired
public void setUser(IUser user) {
this.user = user;
}
}
参数上使用@Autowired
@Service
public class UserService {
private IUser user;
public UserService(@Autowired IUser user) {
this.user = user;
System.out.println("user:" + user);
}
}
也可以在非静态方法的入参上加@Autowired注解:
@Service
public class UserService {
public void test(@Autowired IUser user) {
user.say();
}
}
注解上使用@Autowired
想啥呢,看一眼就够了,你还想更进一步?
这种方式用得不多,不用了解。
@Autowired的高端玩法
面举的例子都是通过@Autowired自动装配单个实例,@Autowired也能自动装配多个实例
将UserService方法调整一下,用一个List集合接收IUser类型的参数:
@Service
public class UserService {
@Autowired
private List<IUser> userList;
@Autowired
private Set<IUser> userSet;
@Autowired
private Map<String, IUser> userMap;
public void test() {
System.out.println("userList:" + userList);
System.out.println("userSet:" + userSet);
System.out.println("userMap:" + userMap);
}
}
增加一个controller:
@RequestMapping("/u")
@RestController
public class UController {
@Autowired
private UserService userService;
@RequestMapping("/test")
public String test() {
userService.test();
return "success";
}
}
调用该接口后:

从图中看出:userList、userSet和userMap都打印出了两个元素,说明@Autowired会自动把相同类型的IUser对象收集到集合中。

@Autowired一定能装配成功?
有些情况下,即使使用了@Autowired装配的对象还是null,到底是什么原因?
没有加@Service注解
在类上面忘了加
@Controller、@Service、@Component、@Repository等注解,Spring就无法完成自动装配的功能
public class UserService {
@Autowired
private IUser user;
public void test() {
user.say();
}
}
这种情况应该是最常见的错误了,别以为你长得帅,就不会犯这种低级的错误
注入Filter 或 Listener
web应用启动的顺序是:listener->filter->servlet
public class UserFilter implements Filter {
@Autowired
private IUser user;
@Override
public void init(FilterConfig filterConfig) throws ServletException {
user.say();
}
@Override
public void doFilter(ServletRequest request,
ServletResponse response,
FilterChain chain) throws IOException, ServletException {
}
@Override
public void destroy() {
}
}
@Configuration
public class FilterConfig {
@Bean
public FilterRegistrationBean filterRegistrationBean() {
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new UserFilter());
bean.addUrlPatterns("/*");
return bean;
}
}
程序启动会报错:

tomcat无法正常启动。Why?
众所周知,Spring MVC的启动是在DisptachServlet里面做的,而它是在listener和filter之后执行。如果我们想在listener和filter里面@Autowired某个bean,肯定是不行的,因为filter初始化的时候,此时bean还没有初始化,无法自动装配。
如果工作当中真的需要这样做,我们该如何解决这个问题?
答案是使用WebApplicationContextUtils.getWebApplicationContext获取当前的ApplicationContext,再通过它获取到bean实例
public class UserFilter implements Filter {
private IUser user;
@Override
public void init(FilterConfig filterConfig) throws ServletException {
// 获取当前的ApplicationContext
ApplicationContext applicationContext = WebApplicationContextUtils.getWebApplicationContext(filterConfig.getServletContext());
this.user = ((IUser)(applicationContext.getBean("user1")));
user.say();
}
@Override
public void doFilter(ServletRequest request,
ServletResponse response,
FilterChain chain) throws IOException, ServletException {
}
@Override
public void destroy() {
}
}
注解未被@ComponentScan扫描
通常情况下,@Controller、@Service、@Component、@Repository、@Configuration等注解,是需要通过@ComponentScan注解扫描,收集元数据的
但是,如果没有加@ComponentScan注解,或者@ComponentScan注解扫描的路径不对,或者路径范围太小,会导致有些注解无法收集,到后面无法使用@Autowired完成自动装配的功能。
号外号外
在Spring Boot项目中,如果使用了
@SpringBootApplication注解,它里面内置了@ComponentScan注解的功能
循环依赖问题
循环依赖:就是一个或多个对象实例之间存在直接或间接的依赖关系,这种依赖关系构成了构成一个环形调用。
第一种情况:自己依赖自己的直接依赖。

第二种情况:两个对象之间的直接依赖。

第三种情况:多个对象之间的间接依赖。

前面两种情况的直接循环依赖比较直观,非常好识别,但是第三种间接循环依赖的情况有时候因为业务代码调用层级很深,不容易识别出来。

Spring的bean默认是单例的,如果单例bean使用@Autowired自动装配,大多数情况,能解决循环依赖问题。
但是如果bean是多例的,会出现循环依赖问题,导致bean自动装配不了。
还有有些情况下,如果创建了代理对象,即使bean是单例的,依然会出现循环依赖问题。
@Autowired 和 @Resouce的区别
@Autowired功能虽说非常强大,但是也有些不足之处。比如:比如它跟Spring强耦合了,如果换成了JFinal等其他框架,功能就会失效。而@Resource是JSR-250提供的,它是Java标准,绝大部分框架都支持。
除此之外,有些场景使用@Autowired无法满足的要求,改成@Resource却能解决问题。接下来看看@Autowired 和 @Resource的区别:
@Autowired默认按byType自动装配,而@Resource默认byName自动装配。@Autowired只包含一个参数:required,表示是否开启自动准入,默认是true。而@Resource包含七个参数,其中最重要的两个参数是:name 和 type。@Autowired如果要使用byName,需要使用@Qualifier一起配合。而@Resource如果指定了name,则用byName自动装配,如果指定了type,则用byType自动装配。@Autowired能够用在:构造器、方法、参数、成员变量和注解上,而@Resource能用在:类、成员变量和方法上。@Autowired是Spring定义的注解,而@Resource是JSR-250定义的注解。
此外,它们的装配顺序不同。
@Autowired的装配顺序如下:

@Resource的装配顺序如下:
1.、如果同时指定了name和type:

2、如果指定了name:
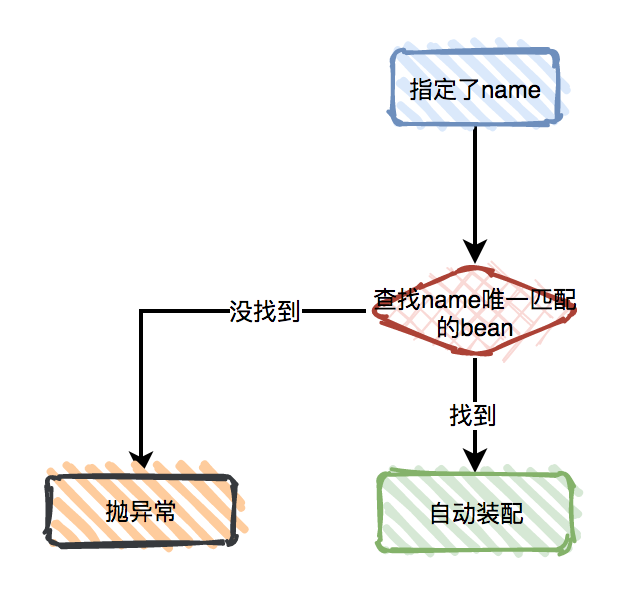
3、如果指定了type:

4、如果既没有指定name,也没有指定type:

@Value 注解
由一个例子开始
假如在UserService类中,需要注入系统属性到userName变量中。通常情况下,我们会写出如下的代码:
@Service
public class UserService {
@Value("${zixq.test.userName}")
private String userName;
public String test() {
System.out.println(userName);
return userName;
}
}
不过,上面功能的重点是要在applicationContext.properties配置文件中配置同名的系统属性:
# 张三
zixq.test.userName=\u5f20\u4e09
那么,名称真的必须完全相同吗?
关于属性名
这时候,有个吊毛会说啦:在@ConfigurationProperties配置类中,定义的参数名可以跟配置文件中的系统属性名不同。
如:在配置类MyConfig类中定义的参数名是userName
@Configuration
@ConfigurationProperties(prefix = "zixq.test")
@Data
public class MyConfig {
private String userName;
}
而配置文件中配置的系统属性名是:
zixq.test.user-name=\u5f20\u4e09
两个参数名不一样,测试之后,发现该功能能够正常运行。
配置文件中的系统属性名用
驼峰标识或小写字母加中划线的组合,Spring都能找到配置类中的属性名进行赋值。
由此可见,配置文件中的系统属性名,可以跟配置类中的属性名不一样。
吊毛啊,你说的这些是有个前提的:前缀(zixq.test)必须相同。
那么,@Value注解中定义的系统属性名也可以不一样?
答案:不能。如果不一样,启动项目时会直接报错
Caused bt:java.lang.IllegatArgumentEcveption:Could not resolve placeholder“zixq.test.userName” in value “${zixq.test.UserName}”
此外,如果只在@Value注解中指定了系统属性名,但实际在配置文件中没有配置它,也会报跟上面一样的错。
所以,@Value注解中指定的系统属性名,必须跟配置文件中的相同。
乱码问题
前面我配置的属性值:张三,其实是转义过的
zixq.test.userName=\u5f20\u4e09
为什么要做这个转义?
假如在配置文件中配置中文的张三:
zixq.test.userName=张三
最后获取数据时,你会发现userName竟然出现了乱码:
å¼ ä¸
王德发?为什么?
答:在Spring Boot的CharacterReader类中,默认的编码格式是ISO-8859-1,该类负责.properties文件中系统属性的读取。如果系统属性包含中文字符,就会出现乱码

如何解决乱码问题?
目前主要有如下三种方案:
- 手动将ISO-8859-1格式的属性值,转换成UTF-8格式。
- 设置encoding参数,不过这个只对
@PropertySource注解有用。 - 将中文字符用unicode编码转义。
显然@Value不支持encoding参数,所以方案2不行。
假如使用方案1,具体实现代码如下:
@Service
public class UserService {
@Value(value = "${zixq.test.userName}")
private String userName;
public String test() {
String userName1 = new String(userName.getBytes(StandardCharsets.ISO_8859_1), StandardCharsets.UTF_8);
System.out.println();
return userName1;
}
}
确实可以解决乱码问题。
但如果项目中包含大量中文系统属性值,每次都需要加这样一段特殊转换代码。出现大量重复代码,有没有觉得有点恶心?
反正我被恶心到了
那么,如何解决代码重复问题?
答:将属性值的中文内容转换成unicode
zixq.test.userName=\u5f20\u4e09
这种方式同样能解决乱码问题,不会出现恶心的重复代码。但需要做一点额外的转换工作,不过这个转换非常容易,因为有现成的在线转换工具。
推荐使用这个工具转换:http://www.jsons.cn/unicode/
Duang Duang~去洗脚城的那个吊毛叼着歌过来了:太阳出来嘛爬山坡,爬到啦山顶嘛想唱guo(歌),真是给爷整笑了。你是真会吹牛掰啊,我使用.yml或.yaml格式的配置文件时,咋不会出现中文乱码问题?
一边凉快去,这玩意儿能一样吗。.yml 或 .yaml格式的配置文件,最终会使用UnicodeReader类进行解析,它的init方法中,首先读取BOM文件头信息,如果头信息中有UTF8、UTF16BE、UTF16LE,就采用对应的编码,如果没有,则采用默认UTF8编码。

提示
乱码问题一般出现在本地环境,因为本地直接读取的.properties配置文件。在dev、test、生产等环境,如果从zookeeper、apollo、nacos等配置中心中获取系统参数值,走的是另外的逻辑,并不会出现乱码问题。
默认值
有时候,默认值是我们非常头疼的问题
因为很多时候使用Java的默认值,并不能满足我们的日常工作需求。
比如有这样一个需求:如果配置了系统属性,userName就用配置的属性值;如果没有配置,则userName用默认值zixq。
可能认为可以这样做:
@Value(value = "${zixq.test.userName}")
private String userName = "zixq";
这招是行不通滴。因为设置userName默认值的时机,比@Value注解依赖注入属性值要早,也就是说userName初始化好了默认值,后面还是会被覆盖。
正确的姿势是:使用:。
@Value(value = "${zixq.test.userName:zixq}")
private String userName;
建议平时在使用
@Value时,尽量都设置一个默认值。如果不需要默认值,宁可设置一个空
@Value(value = "${zixq.test.userName:}")
private String userName;
为什么这么说?
假如有这种场景:在business层中包含了UserService类,business层被api服务和job服务都引用了。但UserService类中
@Value的userName只在api服务中有用,在job服务中根本用不到该属性。对于job服务来说,如果不在
.properties文件中配置同名的系统属性,则服务启动时就会报错。
static变量
通过前面的内容已经知道:使用@Value注解,可以给类的成员变量注入系统属性值
那么静态变量可以自动注入系统属性值不?
@Value("${zixq.test.userName}")
private static String userName;
程序可以正常启动,但是获取到userName的值却是null。
由此可见,被static修饰的变量通过@Value会注入失败
犄角旮旯传出一个声音:那如何才能给静态变量注入系统属性值?
嘿嘿嘿~那你要骚一点才行啊
@Service
public class UserService {
private static String userName;
@Value("${zixq.test.userName}")
public void setUserName(String userName) {
UserService.userName = userName;
}
public String test() {
return userName;
}
}
提供一个静态参数的setter方法,在该方法上使用@Value注入属性值,并且同时在该方法中给静态变量赋值。
哎哟~我去,@Value注解在这里竟然使用在setUserName方法上了,也就是对应的setter方法,而不是在变量上。嗯,骚,确实是骚!
不过,通常情况下,我们一般会在pojo实体类上,使用lombok的@Data、@Setter、@Getter等注解,在编译时动态增加setter或getter方法,所以@Value用在方法上的场景其实不多。
变量类型
上面的内容,都是用的字符串类型的变量进行举例的。其实,@Value注解还支持其他多种类型的系统属性值的注入。
基本类型
@Value注解对8种基本类型和相应的包装类,有非常良好的支持
@Value("${zixq.test.a:1}")
private byte a;
@Value("${zixq.test.b:100}")
private short b;
@Value("${zixq.test.c:3000}")
private int c;
@Value("${zixq.test.d:4000000}")
private long d;
@Value("${zixq.test.e:5.2}")
private float e;
@Value("${zixq.test.f:6.1}")
private double f;
@Value("${zixq.test.g:false}")
private boolean g;
@Value("${zixq.test.h:h}")
private char h;
@Value("${zixq.test.a:1}")
private byte a1;
@Value("${zixq.test.b:100}")
private Short b1;
@Value("${zixq.test.c:3000}")
private Integer c1;
@Value("${zixq.test.d:4000000}")
private Long d1;
@Value("${zixq.test.e:5.2}")
private Float e1;
@Value("${zixq.test.f:6.1}")
private Double f1;
@Value("${zixq.test.g:false}")
private Boolean g1;
@Value("${zixq.test.h:h}")
private Character h1;
数组
@Value("${zixq.test.array:1,2,3,4,5}")
private int[] array;
Spring默认使用逗号分隔参数值
如果用空格分隔,例如:
@Value("${zixq.test.array:1 2 3 4 5}")
private int[] array;
Spring会自动把空格去掉,导致数据中只有一个值:12345,所以注意千万别搞错了
多提一嘴:
如果我们把数组定义成:short、int、long、char、string类型,Spring是可以正常注入属性值的。
但如果把数组定义成:float、double类型,启动项目时就会直接报错

真是裂开了呀!按理说,1,2,3,4,5用float、double是能够表示的呀,为什么会报错?
如果使用int的包装类,比如:
@Value("${zixq.test.array:1,2,3,4,5}")
private Integer[] array;
启动项目时同样会报上面的异常。
此外,定义数组时一定要注意属性值的类型,必须完全一致才可以,如果出现下面这种情况:
@Value("${zixq.test.array:1.0,abc,3,4,5}")
private int[] array;
属性值中包含了1.0和abc,显然都无法将该字符串转换成int。
集合类
有了基本类型和数组,的确让我们更加方便了。但对数据的处理,只用数组这一种数据结构是远远不够的
List
List是数组的变种,它的长度是可变的,而数组的长度是固定的
@Value("${zixq.test.list}")
private List<String> list;
最关键的是看配置文件:
zixq.test.list[0]=10
zixq.test.list[1]=11
zixq.test.list[2]=12
zixq.test.list[3]=13
当你满怀希望的启动项目,准备使用这个功能的时候,却发现竟然报错了。
Caused bt:java.lang.IllegatArgumentEcveption:Could not resolve placeholder“zixq.test.list” in value “${zixq.test.list}”
看来@Value不支持这种直接的List注入
那么,如何解决这个问题?
嗯。。。。。。。你没猜错,曾经有个长得不咋滴的吊毛趴在我椅子上说:真是麻雀上插秧,搔首弄姿。用@ConfigurationProperties不就完了吗
@Data
@Configuration
@ConfigurationProperties(prefix = "zixq.test")
public class MyConfig {
private List<String> list;
}
然后在调用的地方这样写:
@Service
public class UserService {
@Autowired
private MyConfig myConfig;
public String test() {
System.out.println(myConfig.getList());
return null;
}
}
理所应当的,哪个欠怼的吊毛收到了一句话:啊哈。。。。。。。。还挺聪明啊,这种方法确实能够完成List注入。简直是猪鼻子上插大葱,真可谓裤裆里弹琴,扯卵弹(谈),这只能说明@ConfigurationProperties注解的强大,跟@Value有半毛钱的关系?
那么问题来了,用@Value如何实现这个功能?
答:使用Spring的EL表达式(使用#号加大括号的EL表达式)
List的定义改成:
@Value("#{'${zixq.test.list}'.split(',')}")
private List<String> list;
然后配置文件改成跟定义数组时的配置文件一样:
zixq.test.list=10,11,12,13
Set
Set也是一种保存数据的集合,它比较特殊,里面保存的数据不会重复
Set跟List的用法极为相似
@Value("#{'${zixq.test.set}'.split(',')}")
private Set<String> set;
配置文件是这样的:
zixq.test.set=10,11,12,13
但怎么能少了骚操作呢
问题:如何给List 或 Set设置默认值空?
直接在@Value的$表达式后面加个:号可行?
@Value("#{'${zixq.test.set:}'.split(',')}")
private Set<String> set;
结果却跟想象中不太一样:

Set集合怎么不是空的,而是包含了一个空字符串的集合?
嗯。。。。。那我在:号后加null,总可以了吧?
@Value("#{'${zixq.test.set:null}'.split(',')}")
private Set<String> set;
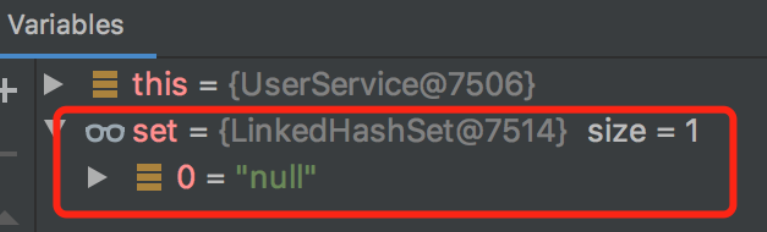
Set集合也不是空的,而是包含了一个"null"字符串的集合
这也不行,那也不行,该如何是好?
答:使用EL表达式的empty方法
@Value("#{'${zixq.test.set:}'.empty ? null : '${zixq.test.set:}'.split(',')}")
private Set<String> set;
其实List也有类似的问题,也能使用该方法解决问题
提示
该判断的表达式比较复杂,自己手写非常容易写错,建议复制粘贴之后根据实际需求改改
Map
还有一种比较常用的集合是map,它支持key/value键值对的形式保存数据,并且不会出现相同key的数据。
@Value("#{${zixq.test.map}}")
private Map<String, String> map;
配置文件是这样的:
zixq.test.map={"name":"苏三", "age":"18"}
设置默认值的代码如下:
@Value("#{'${zixq.test.map:}'.empty ? null : '${zixq.test.map:}'}")
private Map<String, String> map;
EL高端玩法
前面已经见识过spring EL表达式的用法了,在设置空的默认值时特别有用
其实,empty方法只是它很普通的用法,还有更高端的用法
注入bean
以前我们注入bean,一般都是用的@Autowired或者@Resource注解
但@Value注解也可以注入bean,它是这么做的:
@Value("#{roleService}") // 注入id为roleService的bean
private RoleService roleService;
bean的变量和方法
通过EL表达式,@Value注解已经可以注入bean了。既然能够拿到bean实例,接下来,可以再进一步。
在RoleService类中定义了:成员变量、常量、方法、静态方法。
@Service
public class RoleService {
public static final int DEFAULT_AGE = 18;
public int id = 1000;
public String getRoleName() {
return "管理员";
}
public static int getParentId() {
return 2000;
}
}
在调用的地方这样写:
@Service
public class UserService {
@Value("#{roleService.DEFAULT_AGE}")
private int myAge;
@Value("#{roleService.id}")
private int id;
@Value("#{roleService.getRoleName()}")
private String myRoleName;
@Value("#{roleService.getParentId()}")
private String myParentId;
public String test() {
System.out.println(myAge);
System.out.println(id);
System.out.println(myRoleName);
System.out.println(myParentId);
return null;
}
}
在UserService类中通过@Value可以注入:成员变量、常量、方法、静态方法获取到的值,到相应的成员变量中
静态类
前面的内容都是基于bean的,但有时我们需要调用静态类,比如:Math、xxxUtil等静态工具类的方法,该怎么办?
答:用T + 括号。
- 可以注入系统的路径分隔符到path中
@Value("#{T(java.io.File).separator}")
private String path;
- 可以注入一个随机数到randomValue中
@Value("#{T(java.lang.Math).random()}")
private double randomValue;
逻辑运算
通过上面介绍的内容,我们可以获取到绝大多数类的变量和方法的值了。但有了这些值,还不够,我们能不能在EL表达式中加点逻辑?
- 拼接字符串
@Value("#{roleService.roleName + '' + roleService.DEFAULT_AGE}")
private String value;
- 逻辑判断
@Value("#{roleService.DEFAULT_AGE > 16 and roleService.roleName.equals('苏三')}")
private String operation;
- 三目运算
@Value("#{roleService.DEFAULT_AGE > 16 ? roleService.roleName: '苏三' }")
private String realRoleName;
${} 和 #{}的区别
上面巴拉巴拉说了这么多@Value的牛逼用法,归根揭底就是${}和#{}的用法
${}
主要用于获取配置文件中的系统属性值
@Value(value = "${zixq.test.userName:susan}")
private String userName;
通过:可以设置默认值。如果在配置文件中找不到zixq.test.userName的配置,则注入时用默认值。
如果在配置文件中找不到zixq.test.userName的配置,也没有设置默认值,则启动项目时会报错。
#{}
主要用于通过Spring的EL表达式,获取bean的属性,或者调用bean的某个方法。还有调用类的静态常量和静态方法
@Value("#{roleService.DEFAULT_AGE}")
private int myAge;
@Value("#{roleService.id}")
private int id;
@Value("#{roleService.getRoleName()}")
private String myRoleName;
@Value("#{T(java.lang.Math).random()}")
private double randomValue;
提示
果是调用类的静态方法,则需要加T(包名 + 方法名称),如:
T(java.lang.Math)