索引优化、优化,你又是一个好MongoDB!!!博学谷狂野架构师
MongoDB索引优化

- 作者: 博学谷狂野架构师
- GitHub:GitHub地址 (有我精心准备的130本电子书PDF)
只分享干货、不吹水,让我们一起加油!😄
索引简介
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
什么是索引
索引最常用的比喻就是书籍的目录,查询索引就像查询一本书的目录。本质上目录是将书中一小部分内容信息(比如题目)和内容的位置信息(页码)共同构成,而由于信息量小(只有题目),所以我们可以很快找到我们想要的信息片段,再根据页码找到相应的内容。同样索引也是只保留某个域的一部分信息(建立了索引的field的信息),以及对应的文档的位置信息。
假设我们有如下文档(每行的数据在MongoDB中是存在于一个Document当中)
| 姓名 | id | 部门 | city | score |
|---|---|---|---|---|
| 张三 | 2 | xxx | Beijing | 90 |
| 李四 | 1 | xxx | Shanghai | 70 |
| 王五 | 3 | xxx | guangzhou | 60 |
索引的作用
假如我们想找id为2的document(即张三的记录),如果没有索引,我们就需要扫描整个数据表,然后找出所有为2的document。当数据表中有大量documents的时候,这个时间就会非常长(从磁盘上查找数据还涉及大量的IO操作)。建立索引后会有什么变化呢?MongoDB会将id数据拿出来建立索引数据,如下
| 索引值 | 位置 |
|---|---|
| 1 | pos2 |
| 2 | pos1 |
| 3 | pos3 |
索引的工作原理
这样我们就可以通过扫描这个小表找到document对应的位置。
查找过程示意图如下:

索引为什么这么快
为什么这样速度会快呢?这主要有几方面的因素
- 索引数据通过B树来存储,从而使得搜索的时间复杂度为O(logdN)级别的(d是B树的度, 通常d的值比较大,比如大于100),比原先O(N)的复杂度大幅下降。这个差距是惊人的,以一个实际例子来看,假设d=100,N=1亿,那么O(logdN) = 8, 而O(N)是1亿。是的,这就是算法的威力。
- 索引本身是在高速缓存当中,相比磁盘IO操作会有大幅的性能提升。(需要注意的是,有的时候数据量非常大的时候,索引数据也会非常大,当大到超出内存容量的时候,会导致部分索引数据存储在磁盘上,这会导致磁盘IO的开销大幅增加,从而影响性能,所以务必要保证有足够的内存能容下所有的索引数据)
当然,事物总有其两面性,在提升查询速度的同时,由于要建立索引,所以写入操作时就需要额外的添加索引的操作,这必然会影响写入的性能,所以当有大量写操作而读操作比较少的时候,且对读操作性能不需要考虑的时候,就不适合建立索引。当然,目前大多数互联网应用都是读操作远大于写操作,因此建立索引很多时候是非常划算和必要的操作。
查看索引
索引是提高查询查询效率最有效的手段。索引是一种特殊的数据结构,索引以易于遍历的形式存储了数据的部分内容(如:一个特定的字段或一组字段值),索引会按一定规则对存储值进行排序,而且索引的存储位置在内存中,所在从索引中检索数据会非常快。如果没有索引,MongoDB必须扫描集合中的每一个文档,这种扫描的效率非常低,尤其是在数据量较大时。
默认主键索引
在创建集合期间,MongoDB 在_id]字段上 创建唯一索引,该索引可防止客户端插入两个具有相同值的文档。您不能将此索引放在字段上。
查看索引
查看集合索引
要返回集合中所有索引的列表可以使用
db.collection.getIndexes()查看现有索引
COPYdb.zips.getIndexes();
查看
zips集合的所有索引,我们看到有一个默认的_id_索引,并且是一个升序索引

查看数据库
若要列出数据库中所有集合的所有索引,则需在 MongoDB 的 Shell 客户端中进行以下操作:
COPYdb.getCollectionNames().forEach(function(collection){
indexes = db[collection].getIndexes();
print("Indexes for [" + collection + "]:" );
printjson(indexes);
});
这样可以列出本数据库的所有集合的索引

索引常用操作
创建索引
MongoDB使用 createIndex() 方法来创建索引。
注意在 3.0.0 版本前创建索引方法为 db.collection.ensureIndex(),之后的版本使用了 db.collection.createIndex() 方法,ensureIndex() 还能用,但只是 createIndex() 的别名。
语法
createIndex()方法基本语法格式如下所示:
COPYdb.collection.createIndex(keys, options)
语法中 Key 值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。
COPYdb.zips.createIndex({"pop":1})
这样就根据
pop字段创建了一个升序索引

索引参数
createIndex() 接收可选参数,可选参数列表如下
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 “background” 可选参数。 “background” 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
示例
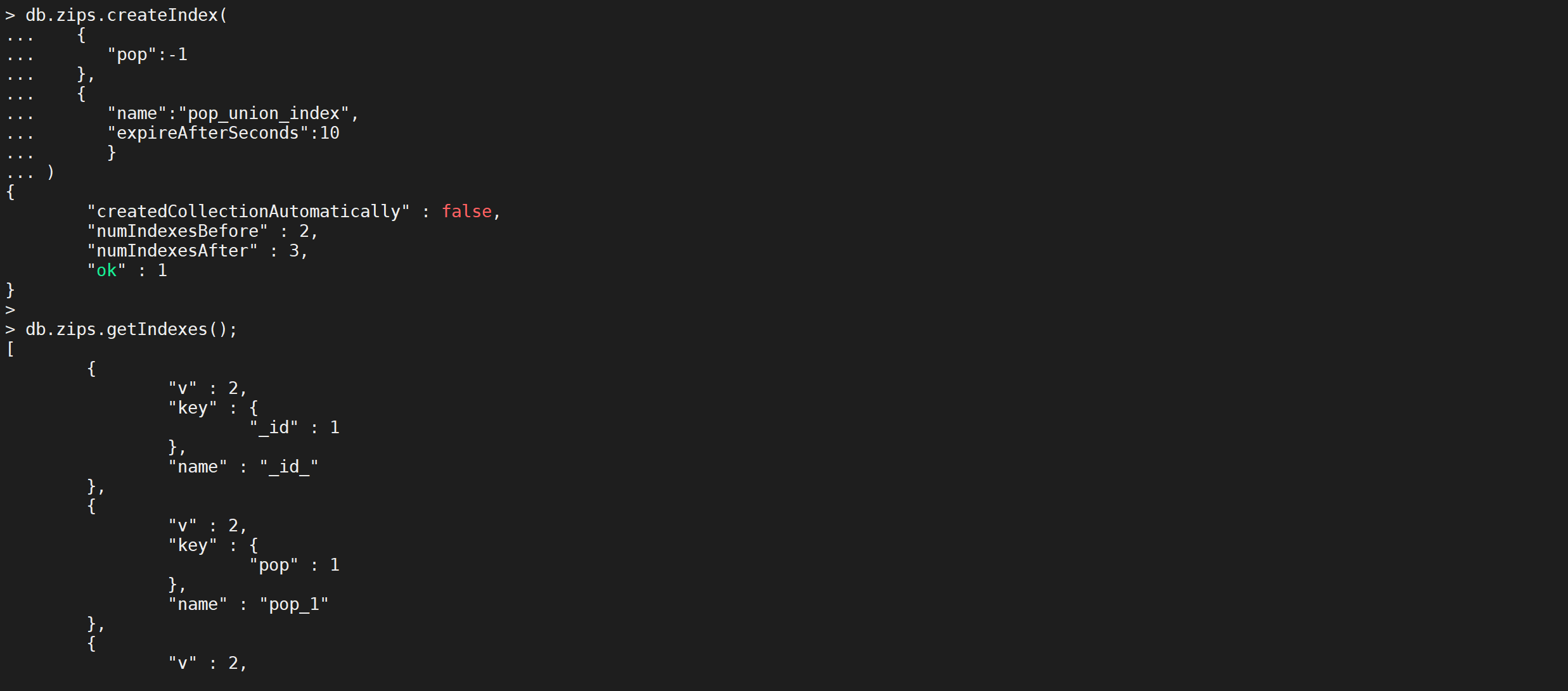
创建一个名称是
pop_union_index的索引,按照pop字段降序,并且在10秒后删除
COPYdb.zips.createIndex(
{
"pop":-1
},
{
"name":"pop_union_index",
"expireAfterSeconds":10
}
)
这样我们就创建了一个索引
删除索引
MongoDB 提供的两种从集合中删除索引的方法如下:
根据name删除
可以根据索引的名字进行索引删除
COPYdb.zips.dropIndex("loc_2d")
这样我们就把一个索引删除了

根据字段删除
还可以根据字段进行删除
COPYdb.zips.dropIndex ({ "pop" : 1 })
删除集合中
pop字段升序的索引,这样就把这个索引删除了

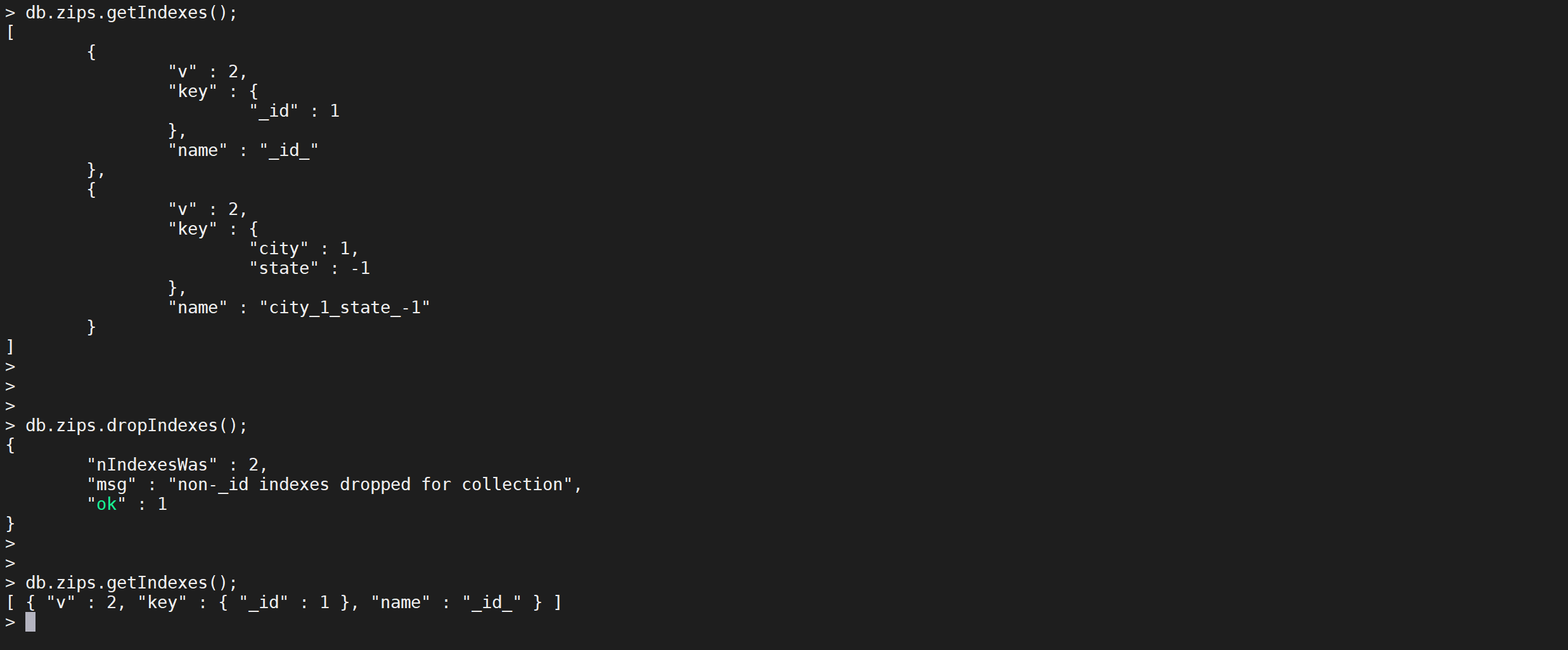
删除所有索引
db.collection.dropIndexes()可以把集合所有索引删除
COPYdb.zips.dropIndexes()`
这样就把非默认的主键索引意外的索引索引删除了
MongoDB索引类型
单键索引
MongoDB为文档集合中任何字段上的索引提供了完整的支持 。默认情况下,所有集合在
_id字段上都有一个索引,应用程序和用户可以添加其他索引来支持重要的查询和操作。

这个是最简单最常用的索引类型,比如我们上边的例子,为id建立一个单独的索引就是此种类型。
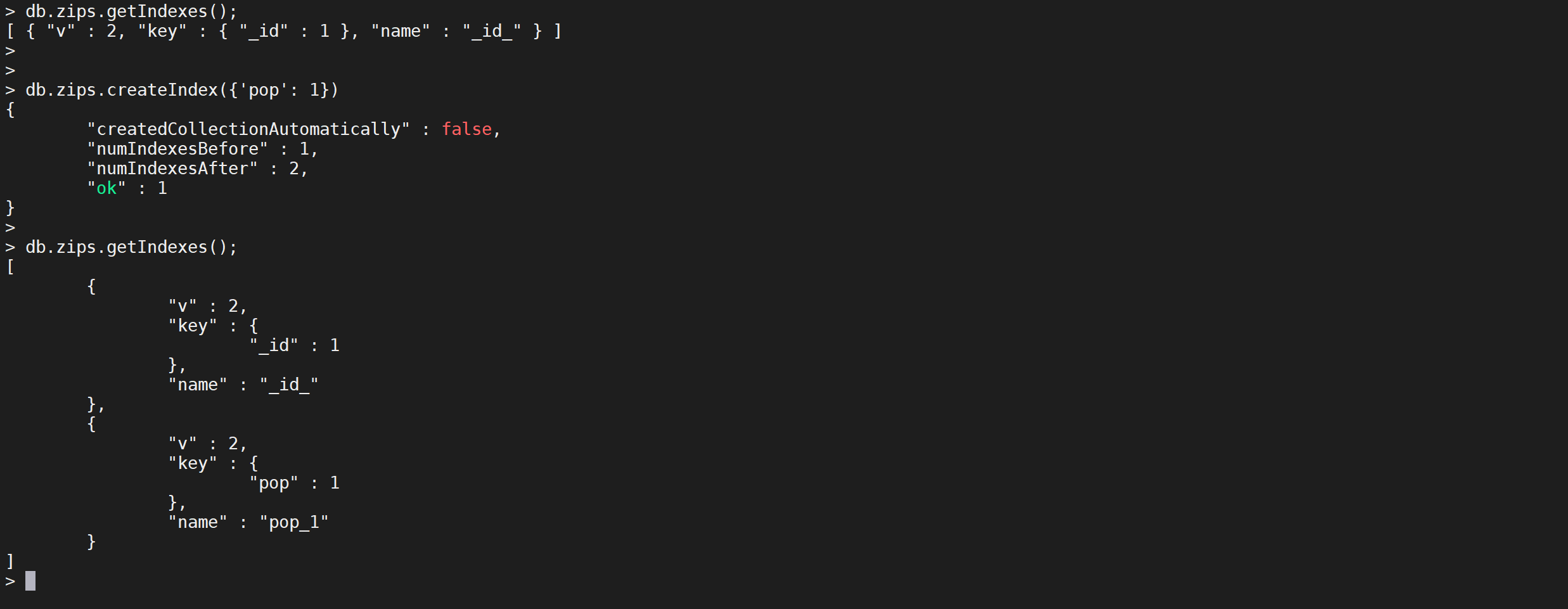
创建索引
我们创建一个
pop人数升序的索引
COPYdb.zips.createIndex({'pop': 1})
其中
{'pop': 1}中的1表示升序,如果想设置倒序索引的话使用{'pop': -1}可
查看执行计划
可以在查询中使用执行计划查看索引是否生效
COPYdb.zips.find({"pop":{$gt:10000}}).explain();
我们发现索引已经生效了

复合索引
复合索引(Compound Indexes)指一个索引包含多个字段,用法和单键索引基本一致。使用复合索引时要注意字段的顺序,如下添加一个name和age的复合索引,name正序,age倒序,document首先按照name正序排序,然后name相同的document按age进行倒序排序。mongoDB中一个复合索引最多可以包含32个字段。符合索引的原理如下图所示:
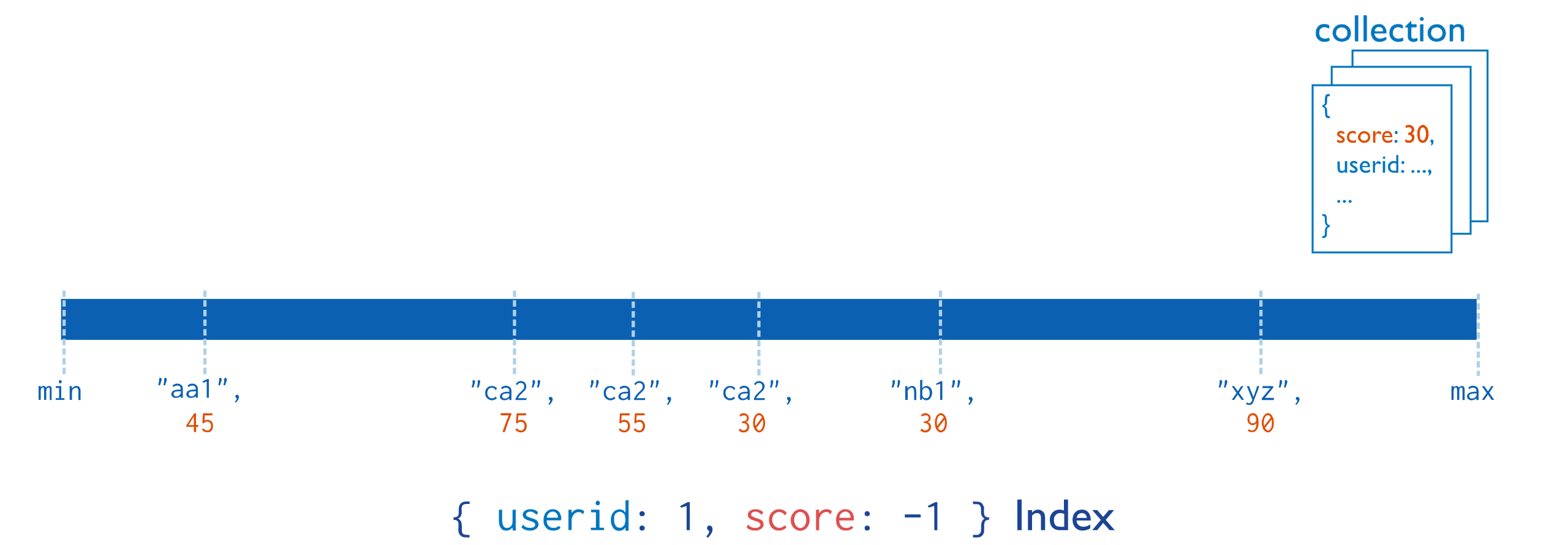
上图查询索引的时候会先查询userid,再查询score,然后就可以找到对应的文档。
创建索引
我们创建一个以
CUSHMAN升序,state降序的符合索引
COPYdb.zips.createIndex({"city": 1,"state":-1})
这样我们就把索引创建了

查看执行计划
COPYdb.zips.find({"city":"CUSHMAN","state":"NY"}).explain();
我们看到我们的查询走了索引

对于复合索引需要注意以下几点:
最左前缀法则
在MySQL中走前缀法则生效,在mongodb中查询同样生效
COPYdb.zips.find({"city":"CUSHMAN"}).explain();
我们只查询最走侧索引列的时候,索引是生效的

但是如果我们查询不加入最左侧索引列
COPYdb.zips.find({"state":"NY"}).explain();
我们发现索引未生效,走了全表扫描

地理索引
地理索引包含两种地理类型,如果需要计算的地理数据表示为类似于地球的球形表面上的坐标,则可以使用 2dsphere 索引。
通常可以按照坐标轴、经度、纬度的方式把位置数据存储为 GeoJSON 对象。GeoJSON 的坐标参考系使用的是 wgs84 数据。如果需要计算距离(在一个欧几里得平面上),通常可以按照正常坐标对的形式存储位置数据,可使用 2d 索引。
创建平面地理索引
如果查找的地方是小范围的可以使用平面索引
COPYdb.zips.createIndex({"loc":"2d"})

创建球面地理索引
如果是大范围的,需要考虑地球弧度的情况下如果使用平面坐标可能不准确,就需要使用球面索引
COPYdb.zips.createIndex({"loc":"2dsphere"})

常用索引属性
唯一索引
唯一索引(unique indexes)用于为collection添加唯一约束,即强制要求collection中的索引字段没有重复值。添加唯一索引的语法:
COPYdb.zips.createIndex({"_id":1,"city":1},{unique:true,name:"id_union_index"})
这样我们就创建了一个根据ID以及city的唯一索引

局部索引
局部索引(Partial Indexes)顾名思义,只对collection的一部分添加索引。创建索引的时候,根据过滤条件判断是否对document添加索引,对于没有添加索引的文档查找时采用的全表扫描,对添加了索引的文档查找时使用索引。
创建索引
COPYdb.zips.createIndex(
{
pop:1
},
{
partialFilterExpression:
{
pop:
{
$gt: 10000
}
}
}
)
这样就创建了局部索引

查看执行计划
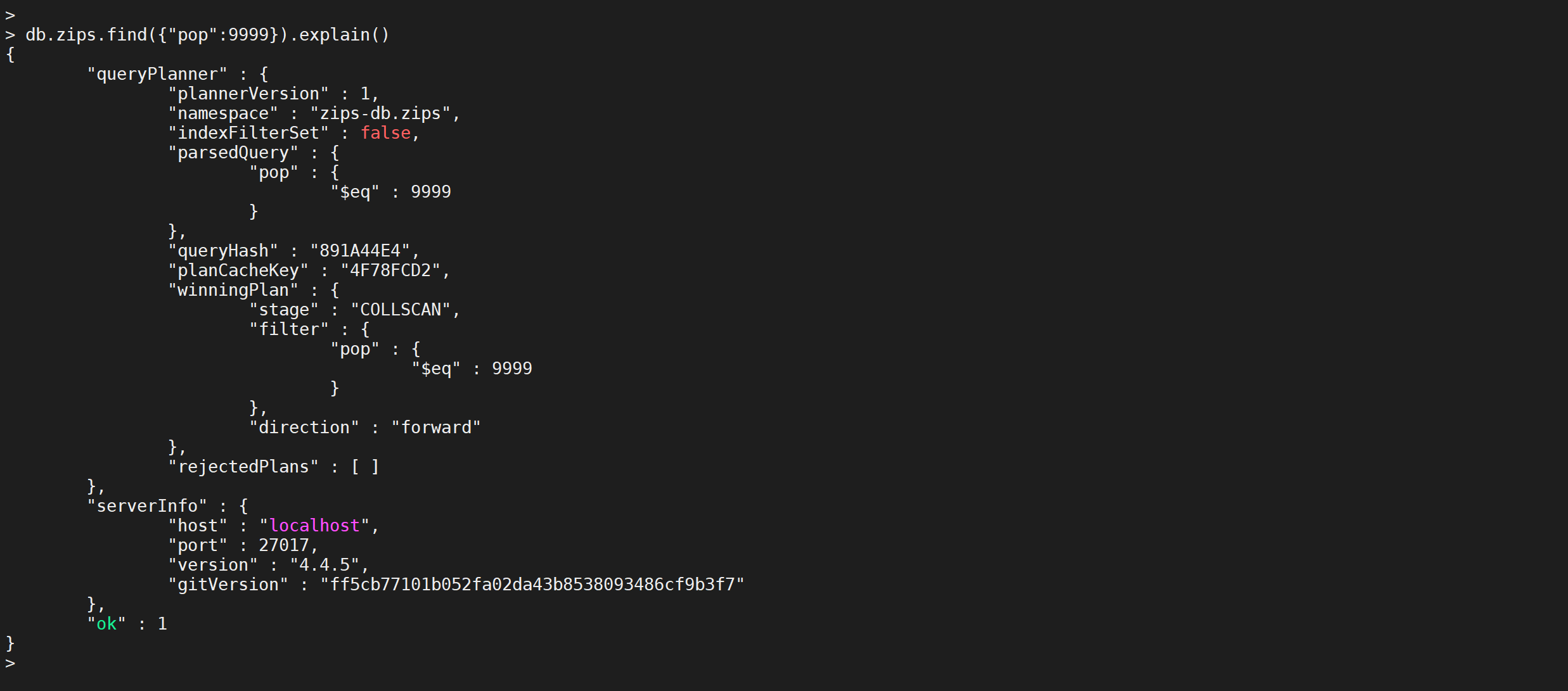
根据索引特性 ,我们知道,只有查找的人数大于10000,才会走索引
COPYdb.zips.find({"pop":9999}).explain()
我们看到,查询10000以内的数据不走索引
如果查找的条件大于10000就会走索引
COPYdb.zips.find({"pop":99999}).explain()

执行计划
MongoDB中的
explain()函数可以帮助我们查看查询相关的信息,这有助于我们快速查找到搜索瓶颈进而解决它,本文我们就来看看explain()的一些用法及其查询结果的含义。整体来说,
explain()的用法和sort()、limit()用法差不多,不同的是explain()必须放在最后面。
基本用法
先来看一个基本用法:
COPYdb.zips.find({"pop":99999}).explain()
直接跟在
find()函数后面,表示查看find()函数的执行计划,结果如下:
COPY{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "zips-db.zips",
"indexFilterSet" : false,
"parsedQuery" : {
"pop" : {
"$eq" : 99999
}
},
"queryHash" : "891A44E4",
"planCacheKey" : "2D13A19E",
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"pop" : 1
},
"indexName" : "pop_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"pop" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : true,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"pop" : [
"[99999.0, 99999.0]"
]
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "localhost",
"port" : 27017,
"version" : "4.4.5",
"gitVersion" : "ff5cb77101b052fa02da43b8538093486cf9b3f7"
},
"ok" : 1
}
返回结果包含两大块信息,一个是 queryPlanner,即查询计划,还有一个是 serverInfo,即MongoDB服务的一些信息。
参数解释
那么这里涉及到的参数比较多,我们来一一看一下:
| 参数 | 含义 |
|---|---|
| plannerVersion | 查询计划版本 |
| namespace | 要查询的集合 |
| indexFilterSet | 是否使用索引 |
| parsedQuery | 查询条件,此处为x=1 |
| winningPlan | 最佳执行计划 |
| stage | 查询方式,常见的有COLLSCAN/全表扫描、IXSCAN/索引扫描、FETCH/根据索引去检索文档、SHARD_MERGE/合并分片结果、IDHACK/针对_id进行查询 |
| filter | 过滤条件 |
| direction | 搜索方向 |
| rejectedPlans | 拒绝的执行计划 |
| serverInfo | MongoDB服务器信息 |
添加不同参数
explain()也接收不同的参数,通过设置不同参数我们可以查看更详细的查询计划。
queryPlanner
是默认参数,添加queryPlanner参数的查询结果就是我们上文看到的查询结果,so,这里不再赘述。
executionStats
会返回最佳执行计划的一些统计信息,如下:
COPYdb.zips.find({"pop":99999}).explain("executionStats")
我们发现增加了一个
executionStats的字段列的信息
COPY{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "zips-db.zips",
"indexFilterSet" : false,
"parsedQuery" : {
"pop" : {
"$eq" : 99999
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"pop" : 1
},
"indexName" : "pop_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"pop" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : true,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"pop" : [
"[99999.0, 99999.0]"
]
}
}
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 0,
"executionTimeMillis" : 1,
"totalKeysExamined" : 0,
"totalDocsExamined" : 0,
"executionStages" : {
"stage" : "FETCH",
"nReturned" : 0,
"executionTimeMillisEstimate" : 0,
"works" : 1,
"advanced" : 0,
"needTime" : 0,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"docsExamined" : 0,
"alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 0,
"executionTimeMillisEstimate" : 0,
"works" : 1,
"advanced" : 0,
"needTime" : 0,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"keyPattern" : {
"pop" : 1
},
"indexName" : "pop_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"pop" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : true,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"pop" : [
"[99999.0, 99999.0]"
]
},
"keysExamined" : 0,
"seeks" : 1,
"dupsTested" : 0,
"dupsDropped" : 0
}
}
},
"serverInfo" : {
"host" : "localhost",
"port" : 27017,
"version" : "4.4.5",
"gitVersion" : "ff5cb77101b052fa02da43b8538093486cf9b3f7"
},
"ok" : 1
}
这里除了我们上文介绍到的一些参数之外,还多了executionStats参数,含义如下:
| 参数 | 含义 |
|---|---|
| executionSuccess | 是否执行成功 |
| nReturned | 返回的结果数 |
| executionTimeMillis | 执行耗时 |
| totalKeysExamined | 索引扫描次数 |
| totalDocsExamined | 文档扫描次数 |
| executionStages | 这个分类下描述执行的状态 |
| stage | 扫描方式,具体可选值与上文的相同 |
| nReturned | 查询结果数量 |
| executionTimeMillisEstimate | 预估耗时 |
| works | 工作单元数,一个查询会分解成小的工作单元 |
| advanced | 优先返回的结果数 |
| docsExamined | 文档检查数目,与totalDocsExamined一致 |
allPlansExecution:用来获取所有执行计划,结果参数基本与上文相同,这里就不再细说了。
慢查询
在MySQL中,慢查询日志是经常作为我们优化查询的依据,那在MongoDB中是否有类似的功能呢?答案是肯定的,那就是开启Profiling功能。该工具在运行的实例上收集有关MongoDB的写操作,游标,数据库命令等,可以在数据库级别开启该工具,也可以在实例级别开启。该工具会把收集到的所有都写入到system.profile集合中,该集合是一个capped collection。
慢查询分析流程
慢查询日志一般作为优化步骤里的第一步。通过慢查询日志,定位每一条语句的查询时间。比如超过了200ms,那么查询超过200ms的语句需要优化。然后它通过 .explain() 解析影响行数是不是过大,所以导致查询语句超过200ms。
所以优化步骤一般就是:
- 用慢查询日志(system.profile)找到超过200ms的语句
- 然后再通过.explain()解析影响行数,分析为什么超过200ms
- 决定是不是需要添加索引
开启慢查询
Profiling级别说明
COPY0:关闭,不收集任何数据。
1:收集慢查询数据,默认是100毫秒。
2:收集所有数据
针对数据库设置
登录需要开启慢查询的数据库
COPYuse zips-db
查看慢查询状态
COPYdb.getProfilingStatus()
设置慢查询级别
COPYdb.setProfilingLevel(2)

如果不需要收集所有慢日志,只需要收集小于100ms的慢日志可以使用如下命令
COPYdb.setProfilingLevel(1,200)
注意:
- 以上要操作要是在test集合下面的话,只对该集合里的操作有效,要是需要对整个实例有效,则需要在所有的集合下设置或则在开启的时候开启参数
- 每次设置之后返回给你的结果是修改之前的状态(包括级别、时间参数)。
全局设置
在mongoDB启动的时候加入如下参数
COPYmongod --profile=1 --slowms=200
或则在配置文件里添加2行:
COPYprofile = 1
slowms = 200
这样就可以针对所有数据库进行监控慢日志了
关闭Profiling
使用如下命令可以关闭慢日志
COPYdb.setProfilingLevel(0)

Profile 效率
Profiling功能肯定是会影响效率的,但是不太严重,原因是他使用的是system.profile 来记录,而system.profile 是一个capped collection, 这种collection 在操作上有一些限制和特点,但是效率更高。
慢查询分析
通过 db.system.profile.find() 查看当前所有的慢查询日志
COPYdb.system.profile.find()

参数含义
COPY{
"op" : "query", #操作类型,有insert、query、update、remove、getmore、command
"ns" : "onroad.route_model", #操作的集合
"query" : {
"$query" : {
"user_id" : 314436841,
"data_time" : {
"$gte" : 1436198400
}
},
"$orderby" : {
"data_time" : 1
}
},
"ntoskip" : 0, #指定跳过skip()方法 的文档的数量。
"nscanned" : 2, #为了执行该操作,MongoDB在 index 中浏览的文档数。 一般来说,如果 nscanned 值高于 nreturned 的值,说明数据库为了找到目标文档扫描了很多文档。这时可以考虑创建索引来提高效率。
"nscannedObjects" : 1, #为了执行该操作,MongoDB在 collection中浏览的文档数。
"keyUpdates" : 0, #索引更新的数量,改变一个索引键带有一个小的性能开销,因为数据库必须删除旧的key,并插入一个新的key到B-树索引
"numYield" : 1, #该操作为了使其他操作完成而放弃的次数。通常来说,当他们需要访问还没有完全读入内存中的数据时,操作将放弃。这使得在MongoDB为了放弃操作进行数据读取的同时,还有数据在内存中的其他操作可以完成
"lockStats" : { #锁信息,R:全局读锁;W:全局写锁;r:特定数据库的读锁;w:特定数据库的写锁
"timeLockedMicros" : { #该操作获取一个级锁花费的时间。对于请求多个锁的操作,比如对 local 数据库锁来更新 oplog ,该值比该操作的总长要长(即 millis )
"r" : NumberLong(1089485),
"w" : NumberLong(0)
},
"timeAcquiringMicros" : { #该操作等待获取一个级锁花费的时间。
"r" : NumberLong(102),
"w" : NumberLong(2)
}
},
"nreturned" : 1, // 返回的文档数量
"responseLength" : 1669, // 返回字节长度,如果这个数字很大,考虑值返回所需字段
"millis" : 544, #消耗的时间(毫秒)
"execStats" : { #一个文档,其中包含执行 查询 的操作,对于其他操作,这个值是一个空文件, system.profile.execStats 显示了就像树一样的统计结构,每个节点提供了在执行阶段的查询操作情况。
"type" : "LIMIT", ##使用limit限制返回数
"works" : 2,
"yields" : 1,
"unyields" : 1,
"invalidates" : 0,
"advanced" : 1,
"needTime" : 0,
"needFetch" : 0,
"isEOF" : 1, #是否为文件结束符
"children" : [
{
"type" : "FETCH", #根据索引去检索指定document
"works" : 1,
"yields" : 1,
"unyields" : 1,
"invalidates" : 0,
"advanced" : 1,
"needTime" : 0,
"needFetch" : 0,
"isEOF" : 0,
"alreadyHasObj" : 0,
"forcedFetches" : 0,
"matchTested" : 0,
"children" : [
{
"type" : "IXSCAN", #扫描索引键
"works" : 1,
"yields" : 1,
"unyields" : 1,
"invalidates" : 0,
"advanced" : 1,
"needTime" : 0,
"needFetch" : 0,
"isEOF" : 0,
"keyPattern" : "{ user_id: 1.0, data_time: -1.0 }",
"boundsVerbose" : "field #0['user_id']: [314436841, 314436841], field #1['data_time']: [1436198400, inf.0]",
"isMultiKey" : 0,
"yieldMovedCursor" : 0,
"dupsTested" : 0,
"dupsDropped" : 0,
"seenInvalidated" : 0,
"matchTested" : 0,
"keysExamined" : 2,
"children" : [ ]
}
]
}
]
},
"ts" : ISODate("2015-10-15T07:41:03.061Z"), #该命令在何时执行
"client" : "10.10.86.171", #链接ip或则主机
"allUsers" : [
{
"user" : "martin_v8",
"db" : "onroad"
}
],
"user" : "martin_v8@onroad"
}
分析
如果发现 millis 值比较大,那么就需要作优化。
- 如果nscanned数很大,或者接近记录总数(文档数),那么可能没有用到索引查询,而是全表扫描。
- 如果 nscanned 值高于 nreturned 的值,说明数据库为了找到目标文档扫描了很多文档。这时可以考虑创建索引来提高效率。
system.profile补充
‘type’的返回参数说明
COPYCOLLSCAN #全表扫描
IXSCAN #索引扫描
FETCH #根据索引去检索指定document
SHARD_MERGE #将各个分片返回数据进行merge
SORT #表明在内存中进行了排序(与老版本的scanAndOrder:true一致)
LIMIT #使用limit限制返回数
SKIP #使用skip进行跳过
IDHACK #针对_id进行查询
SHARDING_FILTER #通过mongos对分片数据进行查询
COUNT #利用db.coll.explain().count()之类进行count运算
COUNTSCAN #count不使用Index进行count时的stage返回
COUNT_SCAN #count使用了Index进行count时的stage返回
SUBPLA #未使用到索引的$or查询的stage返回
TEXT #使用全文索引进行查询时候的stage返回
PROJECTION #限定返回字段时候stage的返回
对于普通查询,我们最希望看到的组合有这些
COPYFetch+IDHACK
Fetch+ixscan
Limit+(Fetch+ixscan)
PROJECTION+ixscan
SHARDING_FILTER+ixscan
等
不希望看到包含如下的type
COPYCOLLSCAN(全表扫),SORT(使用sort但是无index),不合理的SKIP,SUBPLA(未用到index的$or)
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙扫描下发二维码关注一下,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
本文由
传智教育博学谷狂野架构师教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!