袋鼠云产品功能更新报告10期|智能进化,近百项功能升级加速数智化转型
欢迎查阅袋鼠云第10期产品功能更新报告。本期,我们精心推出了72项新增和优化功能,致力于在数字化浪潮中为您提供更高效、更智能的服务。我们相信,这些新特性将为您的业务注入新活力,确保您在数字化转型的每一步都坚实而有力。
以下为袋鼠云产品功能更新报告第10期内容,更多探索,请继续阅读。
离线开发平台
新增功能更新
1.调度周期为自定义调度日期时,支持在任务中灵活设置天、时、分钟三种调度模式
背景:目前任务选择自定义调度周期时,仅可设置天调度实例的执行时间,无法根据自定义调度日历再去设置小时、分钟调度,没办法灵活地满足客户的使用场景。
新增功能说明:当选择的自定义调度周期为天日历时,可以进行实例批次的选择。选择“单批次”代表计划日期内仅可指定一个计划时间运行实例,选择“多批次”代表计划日期内可以指定多个计划时间运行实例。
例如,上传自定义调度日历,2023-12-21,2023-12-22,2023-12-24等日期为自定义调度日期。选择单批次并指定具体时间为00时00分,则代表2023-12-21 00:00 , 2023-12-22 00:00,2023-12-24 00:00为调度计划时间。
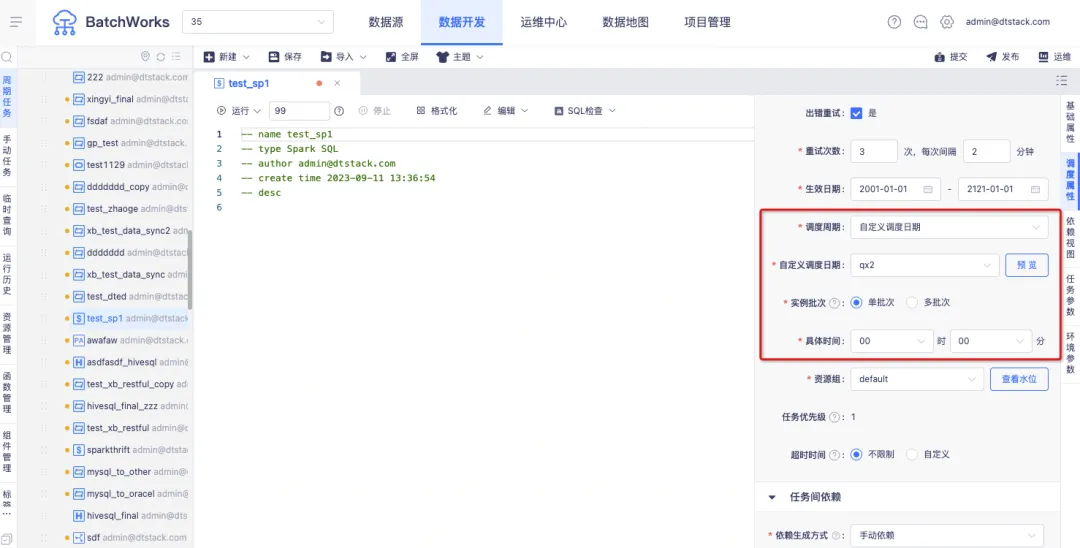
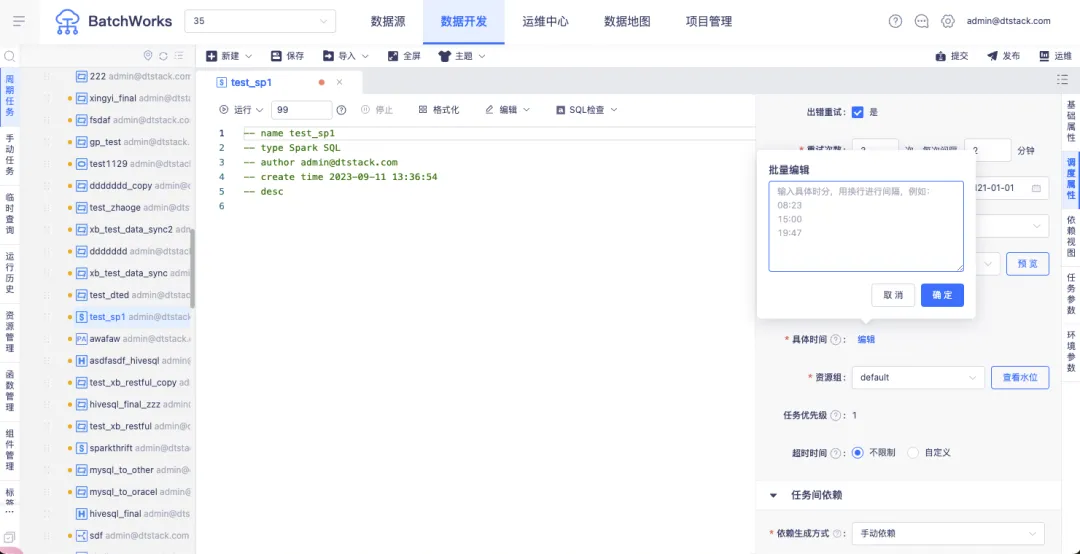
选择多批次并填写时间,08:23,15:00,19:47,则代表2023-12-21 08:23 , 2023-12-21 15:00,2023-12-21 19:47,2023-12-22 08:23,2023-12-22 15:00,2023-12-22 19:47,2023-12-23 08:23, 2023-12-23 15:00,2023-12-23 19:47,为调度计划时间。
2.项目级 Kerberos 生效范围变更
背景:当前的权限管控方法主要是将每个项目作为一个单元进行权限控制,通过项目级 Kerberos 认证去和底层的 Linux 账号做关联。这样项目层面在表查询数据预览是有缺陷的,项目级 Kerberos 认证无法管控到表查询数据预览的内容。
新增功能说明:数据同步、数据预览、SQL 任务运行提交、本地数据上传,以上场景涉及到的 Hadoop meta 数据源,若在项目中和集群中都上传了 Kerberos 票据信息,将会使用项目级 Kerberos 票据信息进行校验。
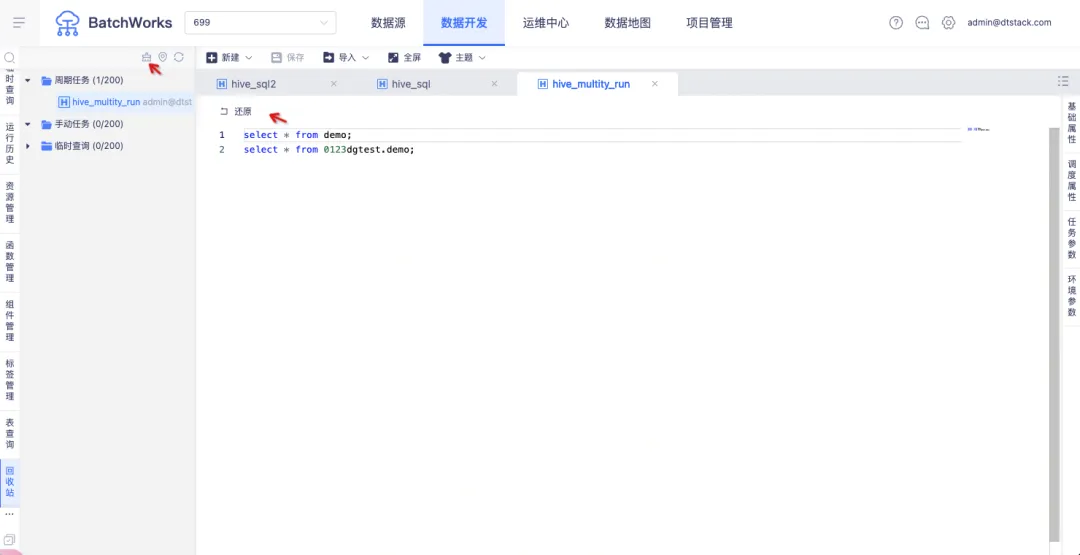
3.支持任务回收站
背景:当前任务被删除后,用户无法恢复,为提升容错机制,产品新增了回收站功能。用户可在回收站中查看已删除的周期任务、手动任务和临时查询,并选择恢复。
新增功能说明:新增【回收站】模块,在删除任务时可以选择「彻底删除」或「移至回收站」。「彻底删除」的任务将直接删除且不在回收站展示,「移至回收站」的任务可以在【回收站】中进行查看。
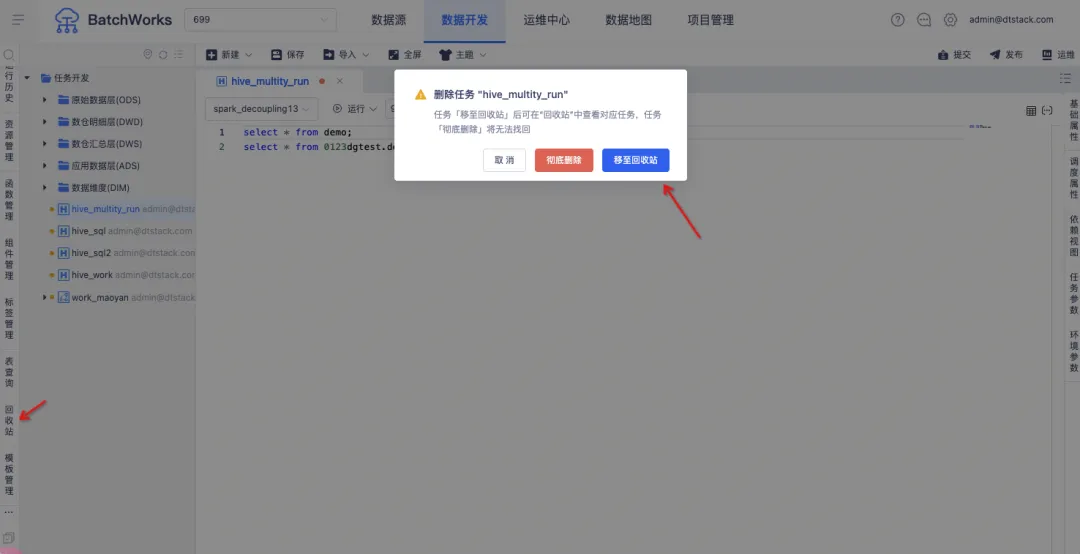
支持对回收站中的任务进行「还原」和「清空」操作。
4.上游任务存在下游依赖时禁止下线
背景:上游任务存在依赖时,不应该被允许下线,会影响下游任务运行。此前需要让用户自己手动取消依赖关系后,再进行下线操作。
新增功能说明:在下线时进行提示,隐藏下线入口。新增「复制」按钮,便于用户粘贴到文本框后依次取消依赖。

5.元数据库 DMDB 8 适配 MySQL,WEB 中间件东风通 tongweb 替换 tomcat
信创全流程适配,适应国产替代化浪潮。
6.SQL 基础功能补全
临时运行、系统函数、自定义函数、执行计划等功能各计算引擎补全(除了极少数不常用引擎)。
7.支持物化视图
背景:物化视图是将表连接或者聚合等耗时较多的结果进行预计算并将计算结果保存下来,在对复杂 SQL 进行查询的时候,直接基于上一步预计算的结果进行计算,从而避免耗时的操作,更快的得到结果。
新增功能说明:在 Spark3.2.2 版本创建的 Spark SQL 任务支持物化视图相关语法。
8.数据同步
• 支持 Iceberg0.13 数据同步
• StarRocks 3.x 版本适配,支持作为计算引擎,支持数据同步读写
功能优化
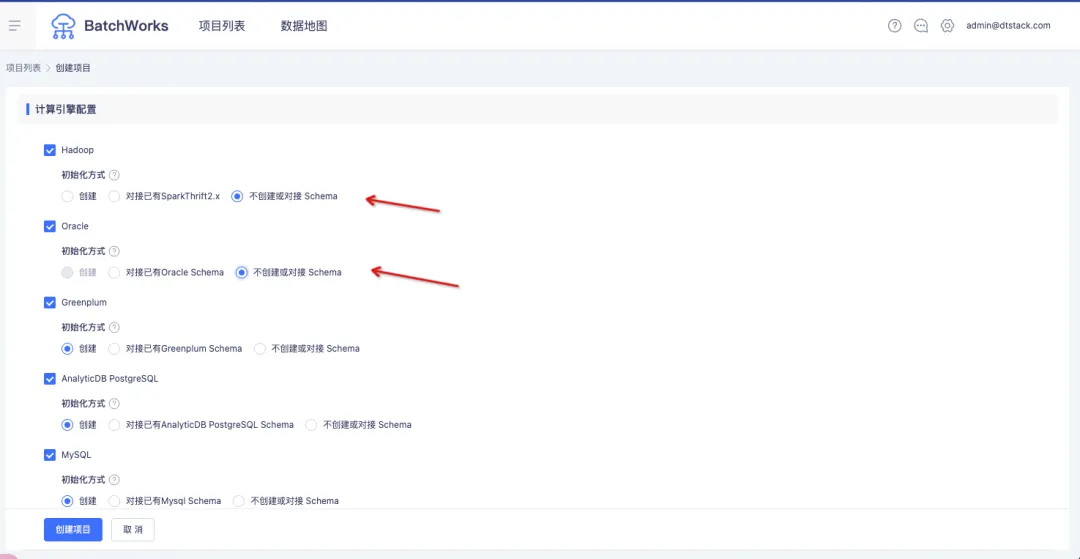
1.创建项目时,项目支持不对接并且不创建 Schema
背景:此前离线创建项目必须对接或者创建一个 schema。但在很多应用场景中,用户的 SQL 开发任务都是在同一个 Schema 下,他们不想在自己的库里去创建很多无意义的 Schema。
体验优化说明:在创建项目时,支持选择「不创建或对接 Schema」。
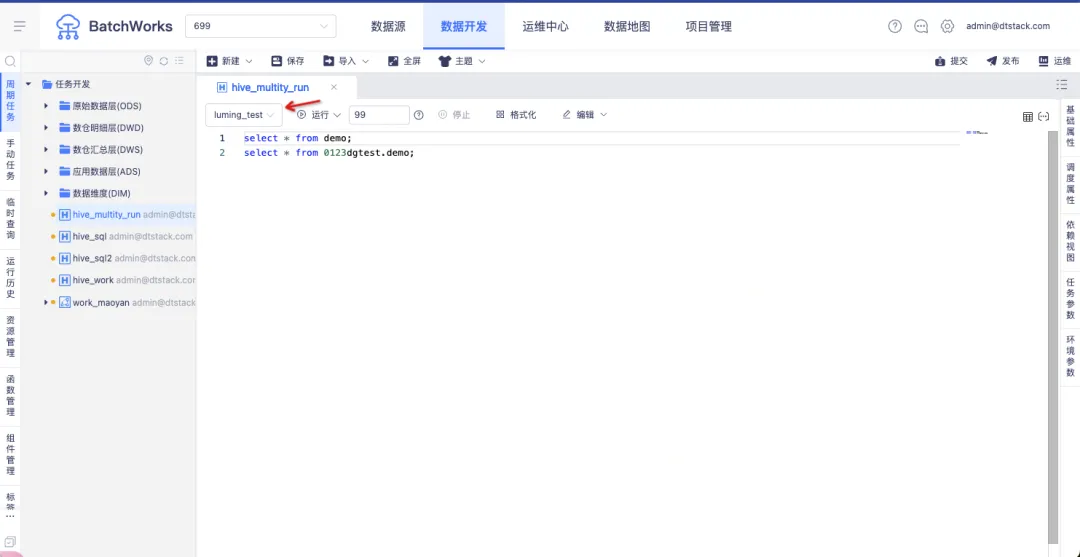
创建项目成功后,在编辑任务时,需要指定 Schema。
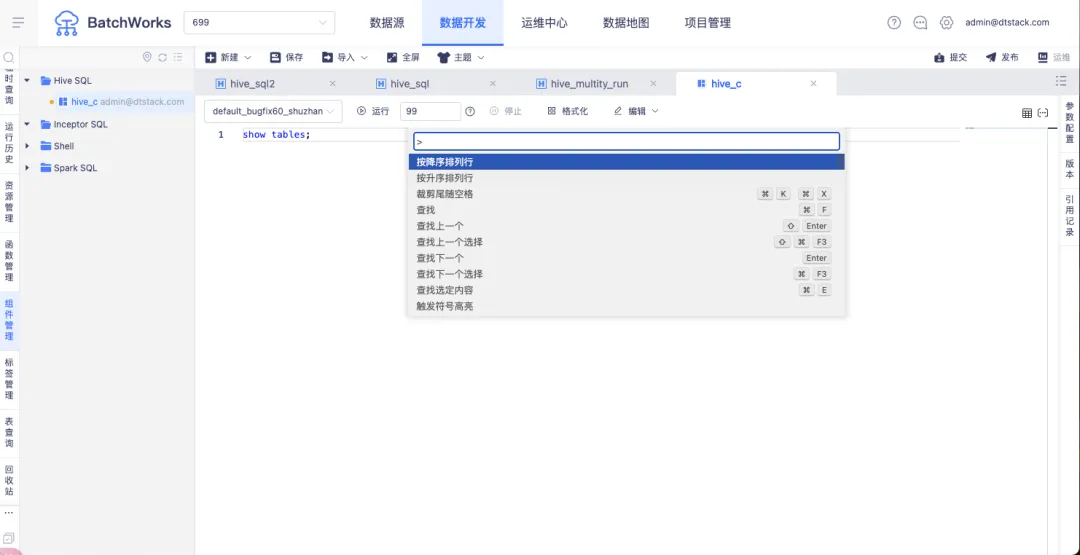
2.快捷键优化
快捷键选择栏支持中文。
3.Hive 脱敏改造,复杂查询生效
原脱敏功能存在问题,复杂查询不生效。现优化调整后,复杂查询的结果也会生效脱敏规则。
4.Flink 任务类型改名为 Flink Batch 任务类型
Flink 任务通常是指实时 Flink 任务,实际上该任务是进行离线批处理,更名后信息更加准确。
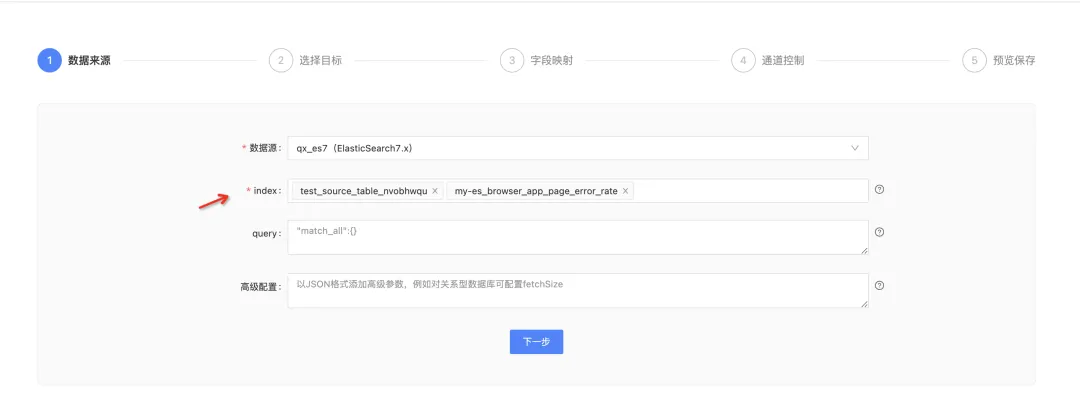
5.ES 数据同步优化
背景:存在多个 Index 同时向目标表进行写入的场景。
体验优化说明:读取 ES 数据源时,支持批量多选 Index,降低了用户的操作成本。支持地理位置字段类型,地理标识字段是 ES 常用的一个字段,在字段映射时支持数据转换。
实时开发平台
新增功能更新
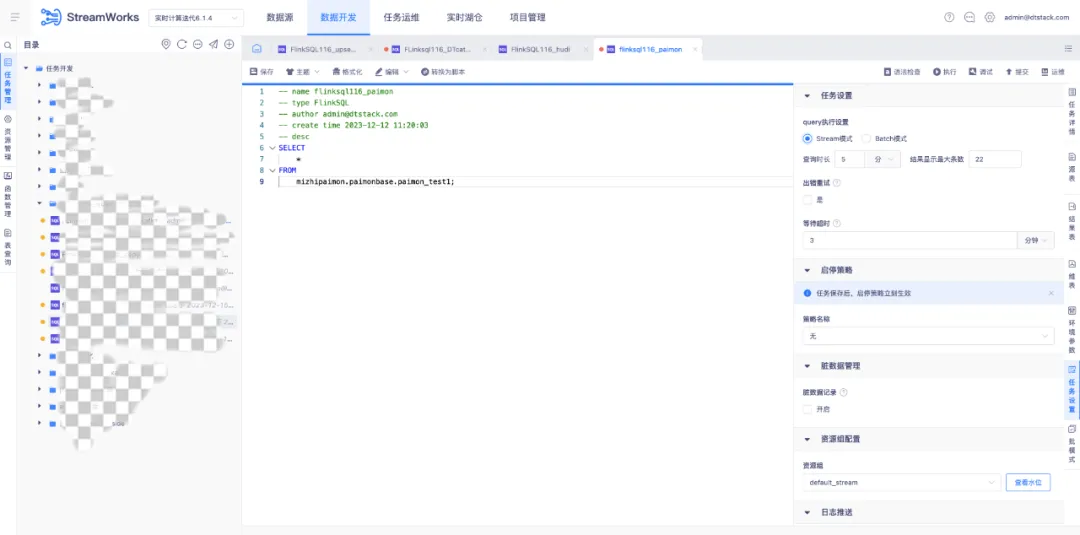
1.数据开发 SQL Query 支持 streaming、batch 模式选择
背景:此前只支持 streaming 模式。
新增功能说明:针对 FlinkSQL 任务(1.16),任务设置中支持 Query 执行设置,可选择执行方式为流模式或者批模式。
• 定义:任务以流模式查数据
• 查询时长:将任务开始在 Flink 引擎上执行,作为计算起点,当查询时间达到此处设置上限时自动停止查询
• 结果最大显示条数:当查询到的数据条数满足设置值时,数据总量不再增加,新的数据覆盖最早的数据
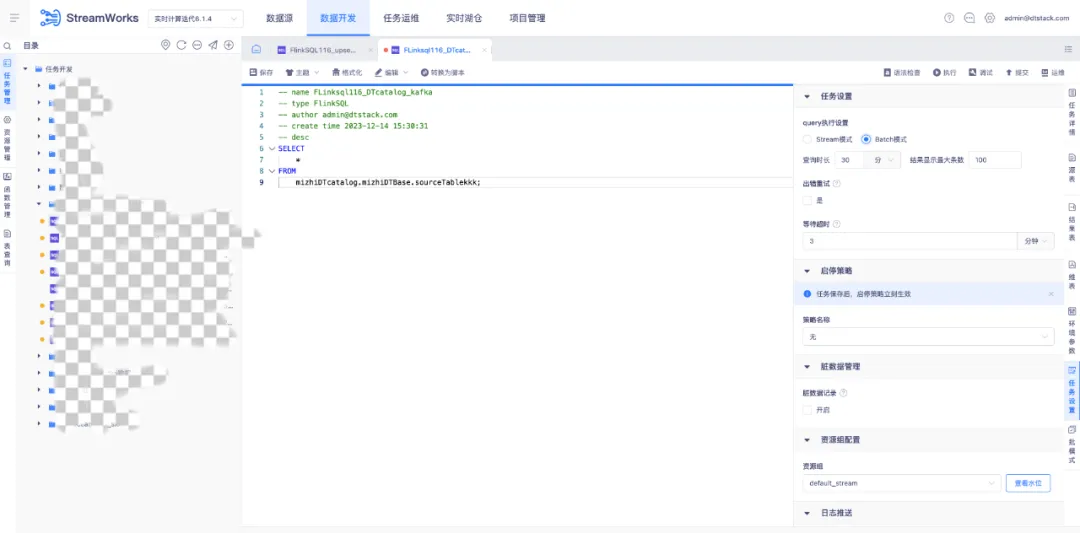
「Batch 模式」
• 定义:任务以批模式查数据,数据查完后暂存,一次性返回至平台展示,支持结果下载,下载功能同 stream 模式
• 查询时长:查询时间达到此处设置上限时自动停止查询,若在此时间内数据返回结束则打印结果,否则结果为空
• 结果最大显示条数:查询/下载结果上限为此处设置的条数
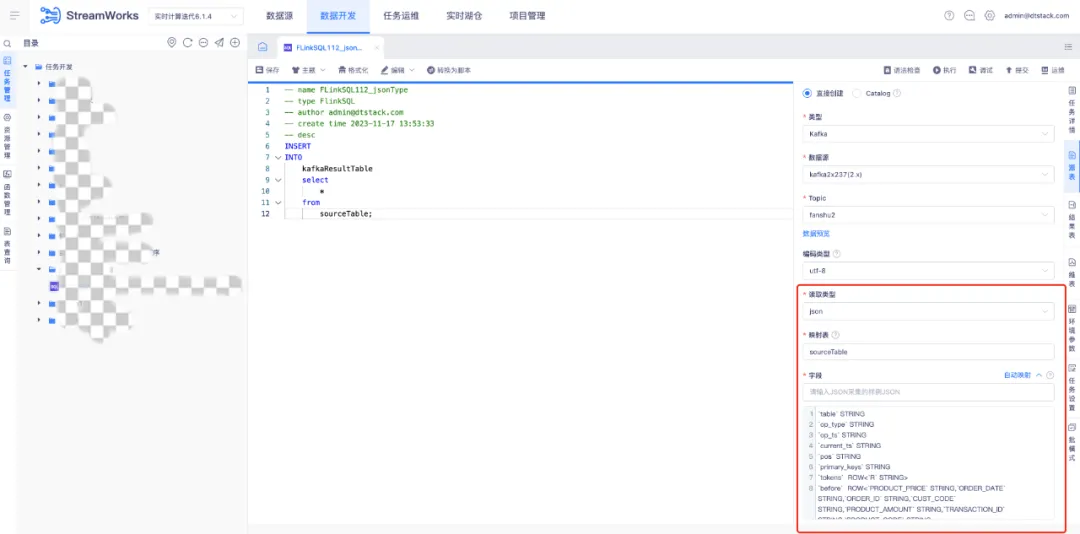
2.数据开发 kafka 格式新增 attunity json
支持基于 Attunity json 的读取类型采集/输入样例数据,自动映射 Flink 表。使用 json 平铺解析的方式可以通过添加自动映射功能来实现,从而满足需求。
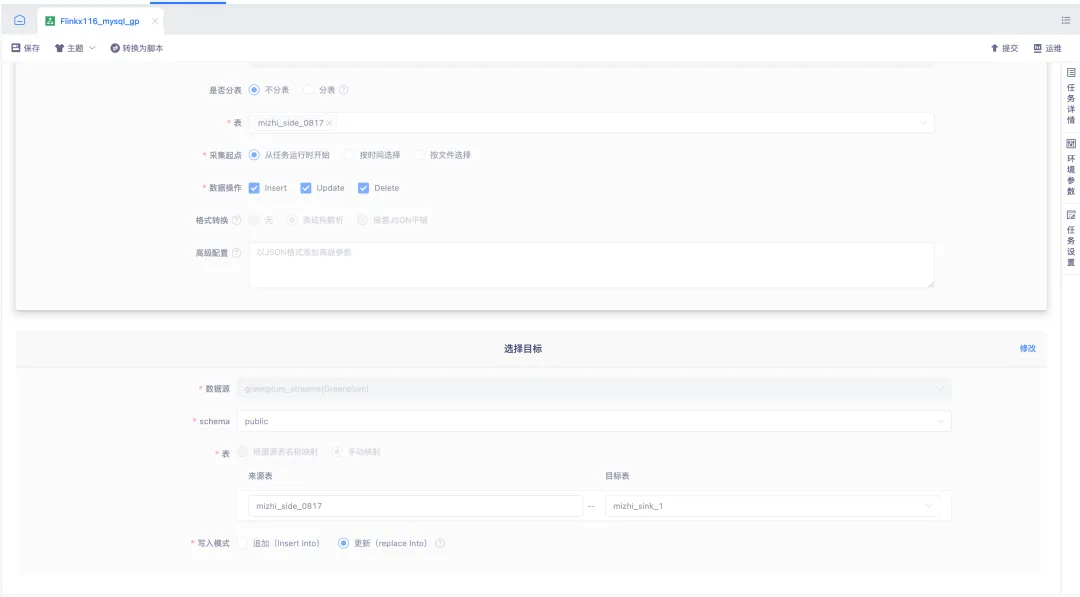
3.实时采集向导模式结果端支持 gp
实时采集1.12&1.16版本支持 Greenplum 目标表写入能力,为用户提供了更加灵活和高效的数据处理能力。
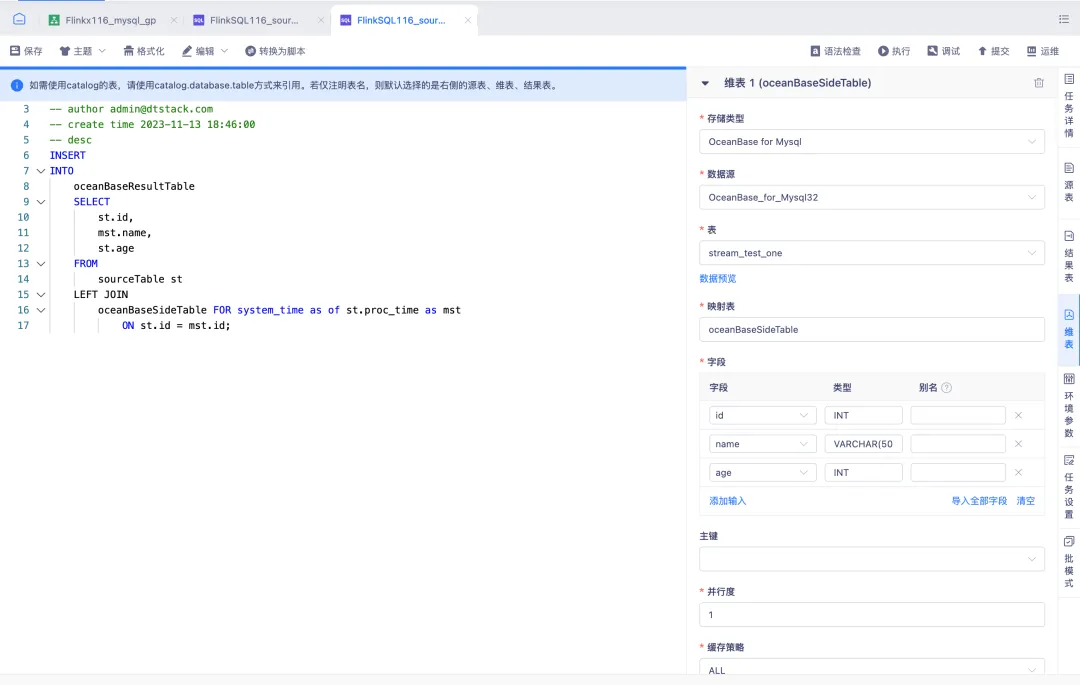
4.FlinkSQL 维表支持 OceanBase
FlinkSQL1.16 版本支持 OceanBase 维表读取能力,为用户提供了更加灵活和高效的数据处理能力。
5.实时湖仓通过后端文件配置控制湖表的展示和其他操作
背景:用户对实时湖仓表管理中表的范围提出需求,此前实时湖仓不支持展示在其他平台或底层创建的表,并需要对表的增删改查操作设置权限限制。
新增功能说明:
• 优化实时湖仓获取 HMScatalog 元数据的方式
• 通过配置项参数,控制 IED 编辑 SQL 和湖仓管理-表展示的范围、控制表操作的范围,当前配置项仅针对 HSMCatalog
• 优化表管理 Catalog 展示性能问题
6.实时湖仓 HMSCatalog 创建增加 Warehouse 参数
背景:当前不支持在创建 HMSCatalog 时配置 Warehouse 地址,只能使用默认的地址,且不做展示。
新增功能说明:增加必填 Warehouse 项,回填 hive-site 文件内 Warehouse 地址,湖仓创建 catalog 时可以指定存储路径而不是按默认的路径进行存储。

7.版本适配和支持
• 实时湖仓 Hive 适配 CDH6.2.1 对应的 Hive 2.1 版本
•实时湖仓 FLinkSQL1.12 支持运行 DTCatalog 和 IcebergCatalog
• 实时计算平台支持 Hbase2.x 数据源作为 FLinkSQL 维表且版本支持1.16

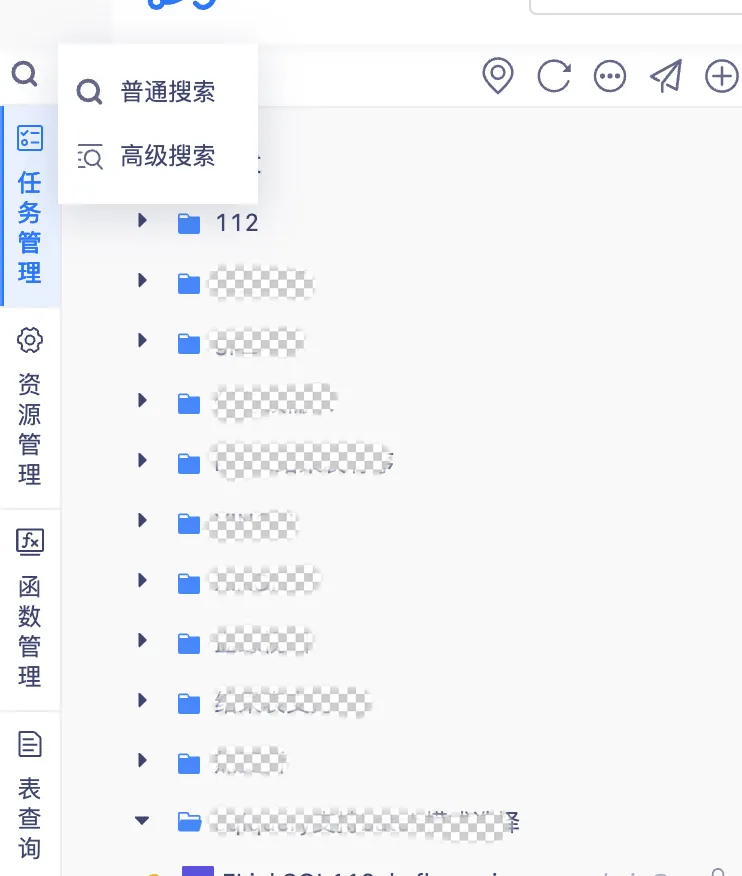
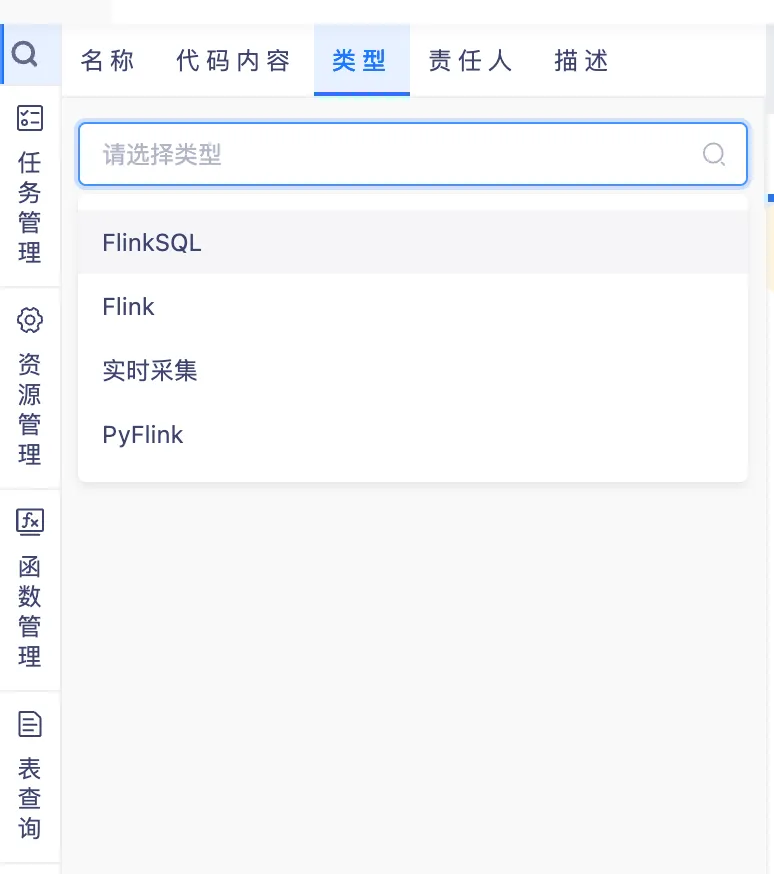
8.数据开发页面支持高级检索方式
背景:此前的搜索不区分具体的查询类型,导致查询效率低下。
新增功能说明:数据开发页面新增支持高级检索方式,如支持代码检索等功能,同时增加支持根据代码内容搜索相对应的任务,提高搜索的实用性。
9.FlinkSQL&实时采集向导模式增加脚本预览功能
FlinkSQL&实时采集向导模式增加脚本预览功能,前端支持功能包含:搜索、复制、read-only、下载。

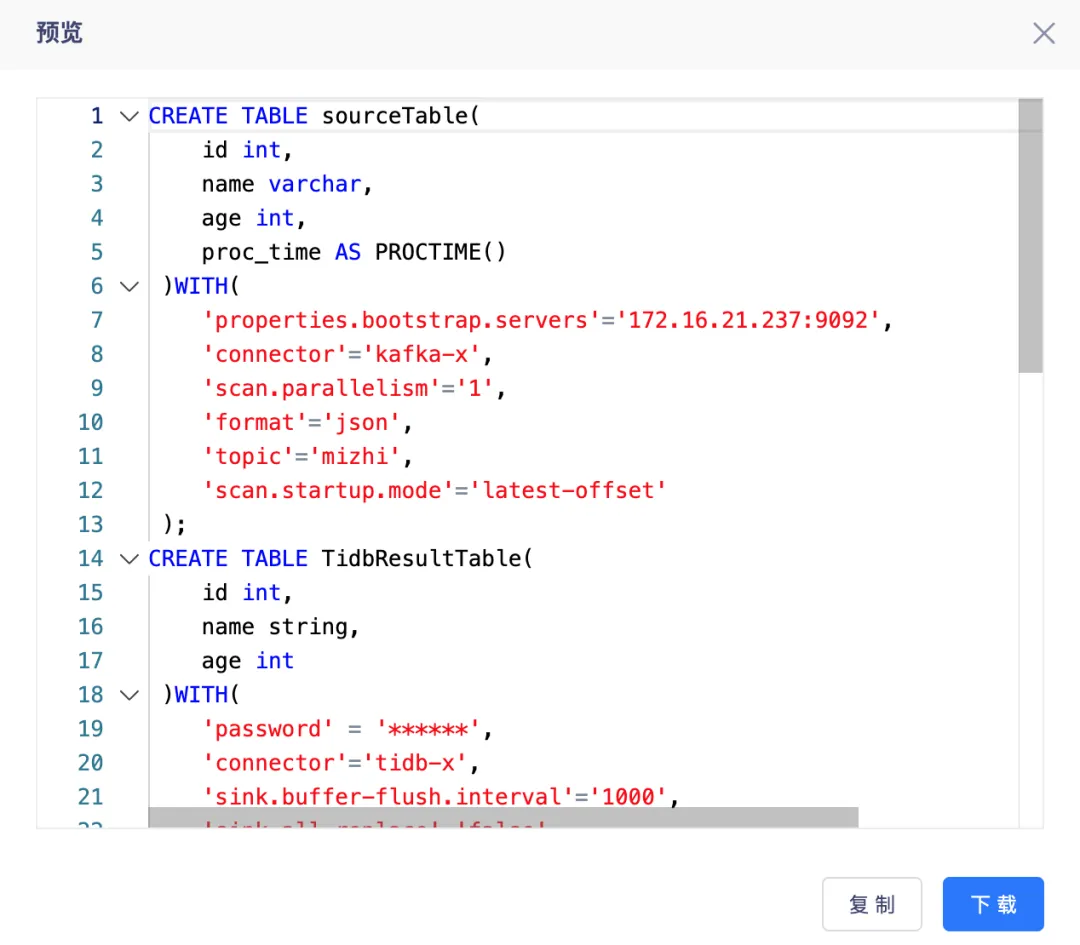
10.字段自动补全功能
背景:数据开发在编写 FlinkSQL 时,从当前的拓扑图编写中无法得到具体的一些字段信息。
新增功能说明:
• 实时计算数据开发众的 FlinkSQL,支持源表、维表、结果表字段在 SQL 编辑器 IED 编辑时的字段自动补全功能,提高开发 SQL 的效率
• 支持向导模式和脚本模式
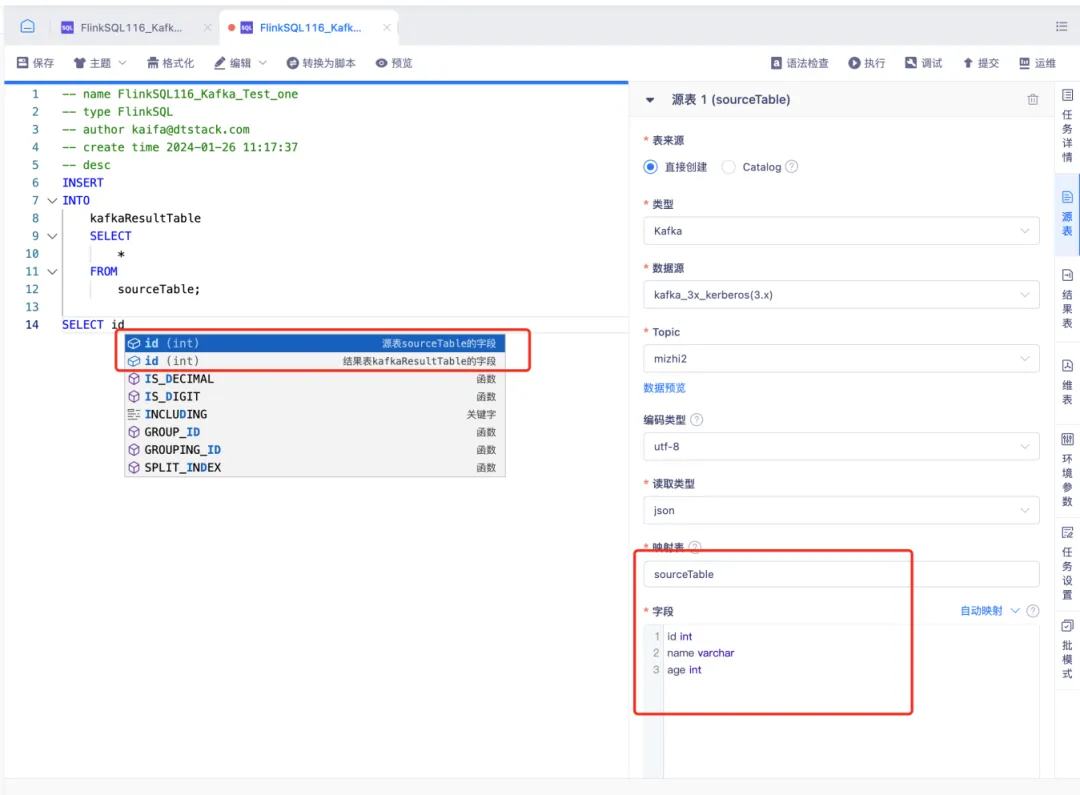
11.适配 kafka3 且支持 kerberos 认证
• 支持 FlinkSQL1.16 版本作为源表、结果表
• 支持实时采集1.16版本作为来源表、目标表
• 支持开启 kerberos 认证方式
• 支持实时湖仓 DTCatalog 作为源表、结果表
• 支持调试运行

功能优化
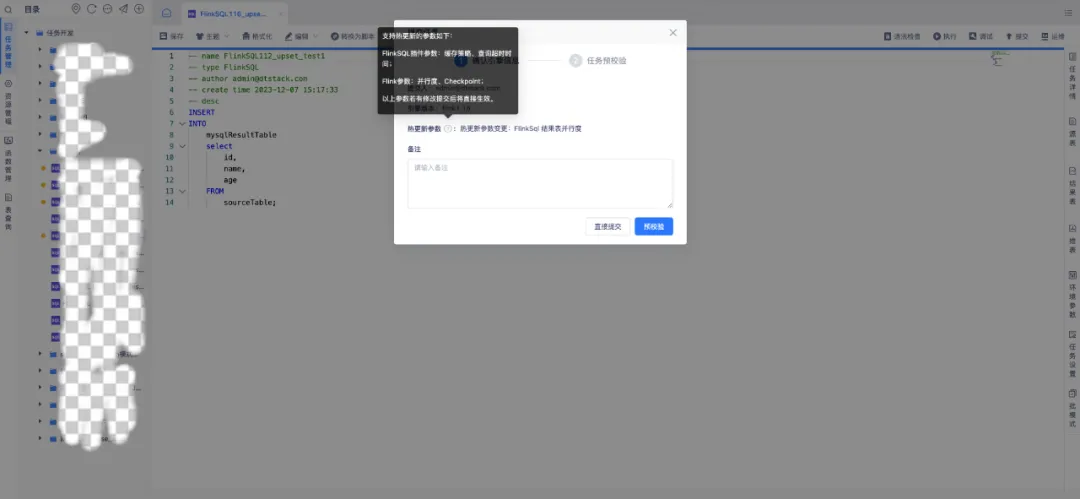
1.任务运维实时任务并行度修改的热更新
背景:在修改环境参数中的任务并行度参数后,为保证尽快生效,平台会自动停止任务后重启,这让实时任务有了一个停止时间,重启耗时会比较久。
体验优化说明:在修改任务并行度参数后,不需要停止任务,提交后可直接生效,需要引擎出方案修改。支持热更新的参数如下:
• FlinkSQL 插件参数:维表 all 改为 lru、查询超时时间
• Flink参数:并行度、checkPoint 参数
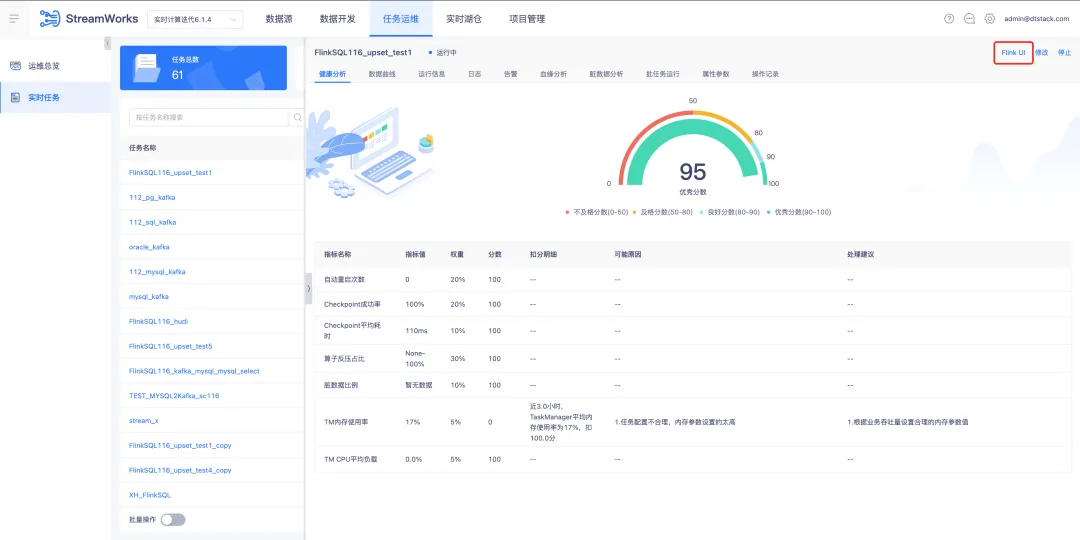
2.任务运维任务支持跳转 FlinkUI
背景:Flink Dashboard 展示了一些平台没有展示的运行及日志等信息,对有经验的数据开发来说更方便排查问题。
体验优化说明:实时计算所有“运行中”状态(实际非 application 运行中,需要 job 运行中才能跳转成功)的任务的运维页面在下图位置显示 FlinkUI 跳转入口。
3.数据开发任务锁覆盖逻辑优化
背景:目前同一用户在两个窗口同时编辑任务时,A窗口先保存,B窗口再次保存时,覆盖逻辑默认A覆盖B,会导致后保存版本内容丢失。
体验优化说明:任务锁覆盖逻辑优化
• 版本记录增加保存版本,平台异常登出时自动保存任务
• 多人编辑同个任务/同一用户在多个窗口编辑同个任务并出现保存冲突时,可让用户选择保存版本

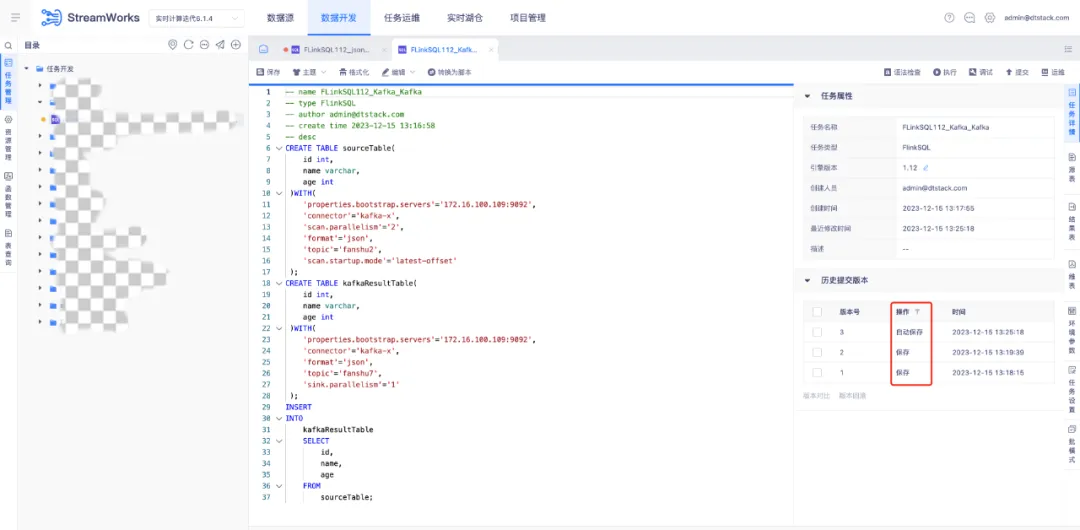
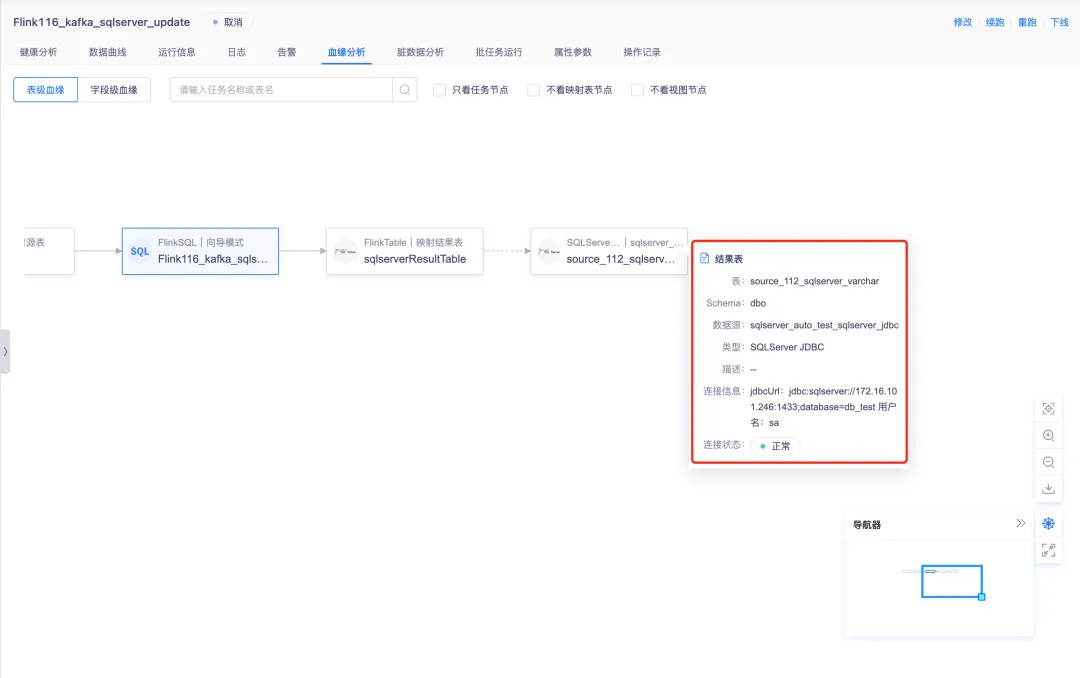
4.任务运维血缘节点信息优化
针对 FlinkSQL 和实时采集任务,表级血缘图中的源表、维表与结果表的节点,点击时显示数据源信息,对交互与任务的详细浮窗不一致问题进行优化。
5.实时开发选择资源时,直接根据任务类型限制能选择的资源类型范围
背景:需要通过资源创建的任务类型,在创建时应有校验资源类型是否选择正确的功能,而不是在选择资源时直接根据当前任务类型进行可选资源范围过滤,导致错误提示滞后,增加用户误操作成本。
体验优化说明:选择资源时直接根据任务类型限制可选范围,其余不可选的资源类型在下拉时置灰无法选中
• Flink 可选范围为 jar
• PyFlink 可选范围为 py 文件
6.任务信息清理
背景:
• 某个任务由于业务变更需要修改逻辑或在较长的一段时间内不需要执行时,在任务运维列表中还持续存在会造成信息干扰,需要进行下线操作,和提交形成逆向的操作闭环
• 任务下线后可能隔断时间会重新提交,也可能很长一段时间内不会再次提交,目前所有任务的 cp sp 信息都保留会导致无用文件的堆积,任务删除时任务相关的信息更需要完整删除
• on k8s 的任务在 jobgraph 创建之前被取消或异常失败不会被清理,只有在正常结束或者 jobgraph 调度之后再被取消才会正常清理;on yarn 的任务,如果任务 cancel 会删除数据,但是如果直接 kill application 则不会删除 zk 数据,同样会导致无用文件的堆积
体验优化说明:
• 实时开发任务下线后可选择清理 check point、save point 信息,任务异常状态时清理 zk 信息
• 任务下线时可选择清理运维记录及日志数据,任务删除时自动删除运维记录及日志数据
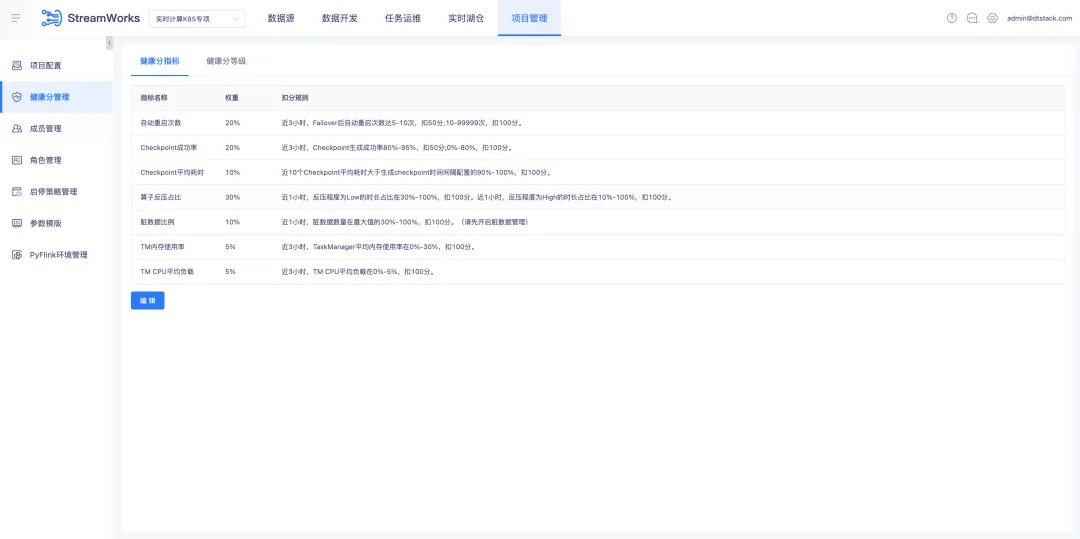
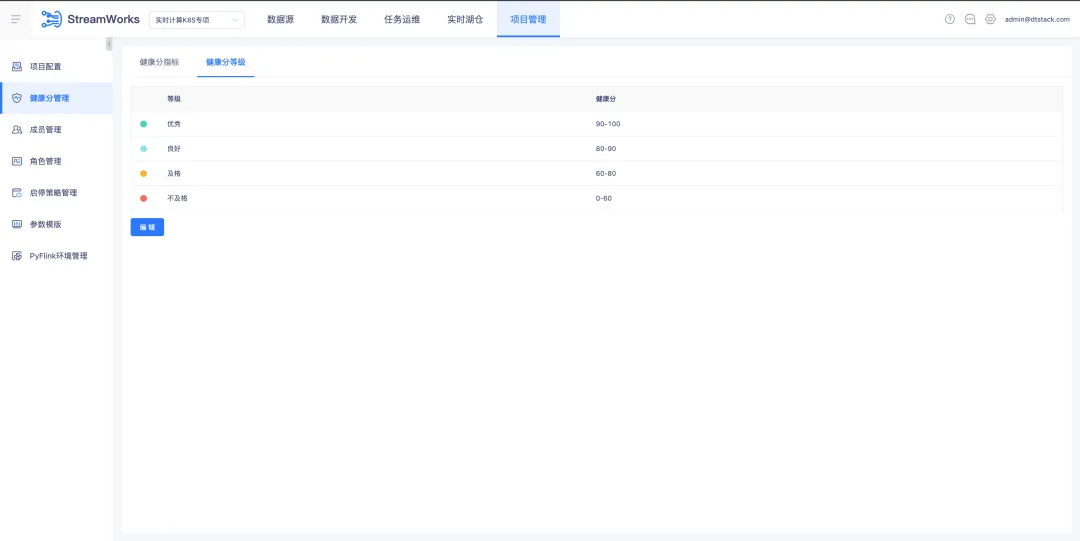
7.健康分优化
项目管理导航栏下新增【健康分管理】子页面,里面分为【健康分指标】(默认展示)和【健康分等级】两个 tab。
8.前端改造
• 将 React Router 从 v3.x 升级到 v6.x
• 对前端易用性性能进行改造,改进首屏性能,通过易测做量化,改进 FPS 场景任务
9.向导模式下 AS 别名隐藏
历史版本的1.10支持维表 AS 别名,后续在1.12及以上使用 Flink 语法则不支持。为防止使用上出现问题,将向导模式下别名隐藏,修改后字段和类型的显示跟结果表保持一致。
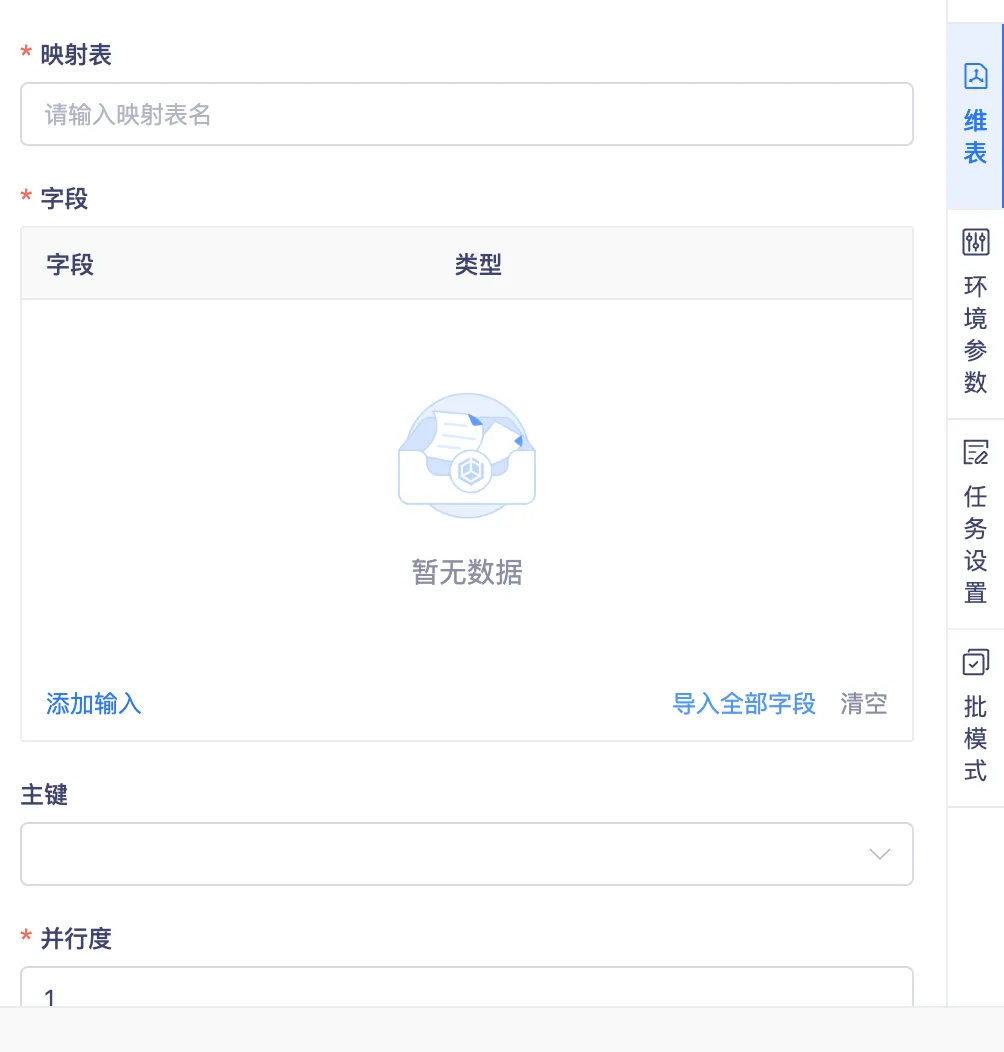
10.实时开发任务热更新优化
背景:此前版本对热更新未做状态限制,存在正在热更新的任务重复提交热更新的操作。
体验优化说明:
• 通过后端对任务热更新状态的判断,正在热更新的任务无法重复的提交热更新操作,将给出提示:当前任务正在进行热更新操作,请等待热更新结束后再执行操作
• 调度增加任务运行状态,可以通过状态进行判断
11.自定义模版创建任务时取消引擎版本限制
背景:此前的自定义模版,只支持 Flink1.16 版本使用,限制了模版的使用版本,6.0的用户存在低版本未升级到1.16的情况,就无法使用此功能。
体验优化说明:自定义模版创建任务取消引擎版本的限制,同步支持了低版本也能使用此功能。

12.任务开发页面优化
背景:任务开发时,点击保存,页面会自动跳回至顶部,打乱开发节奏,无法定位上一次编辑的位置。
体验优化说明:数据开发在使用任务开发页面编辑 SQL 脚本不需要从顶部开始往下滑动,可以直接停留在保存的位置。
数据资产平台
新增功能更新
1.平台层数据权限管理,包含表级、行级、列级权限的授予与申请
• 支持进行数据权限的配置,可配置数据权限范围、生效用户
• 支持按照库、表、行、列维度进行数据权限的配置
• 支持表级权限的申请(扩充行、列权限的申请),申请通过后,在权限配置的页面,自动为此用户所在的用户组,添加这条权限信息

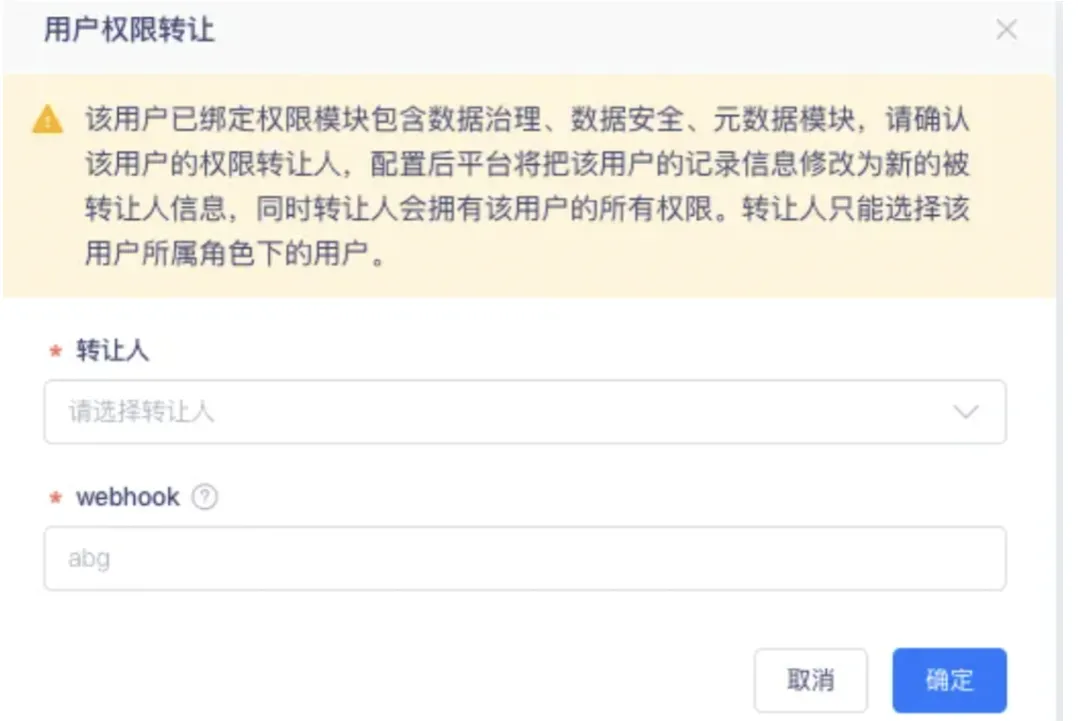
2.移除用户时需进行用户权限转让
背景:当人员离职时,需支持自动交接;在移除产品操作时需要进行用户信息校验;若已经负责了数据治理模块的具体项目,有关联的待处理问题、通知信息配置,需要进行提示,并要在进行权限转让后再移除产品。
新增功能说明:在用户被移除的时候,增加权限交接功能,包括告警配置、权限信息等信息的交接。
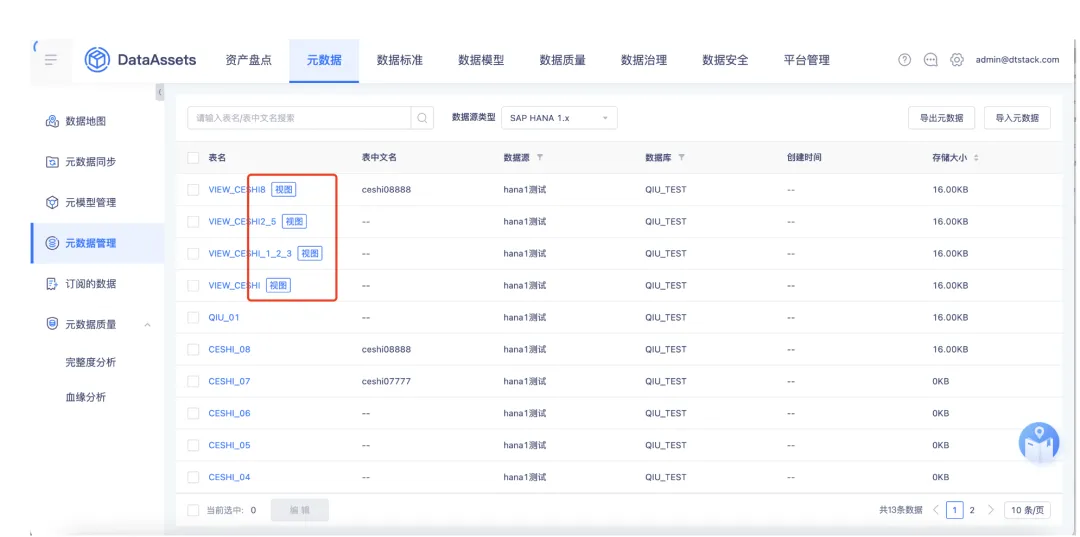
3.oushudb/oracle 类型数据源支持视图同步
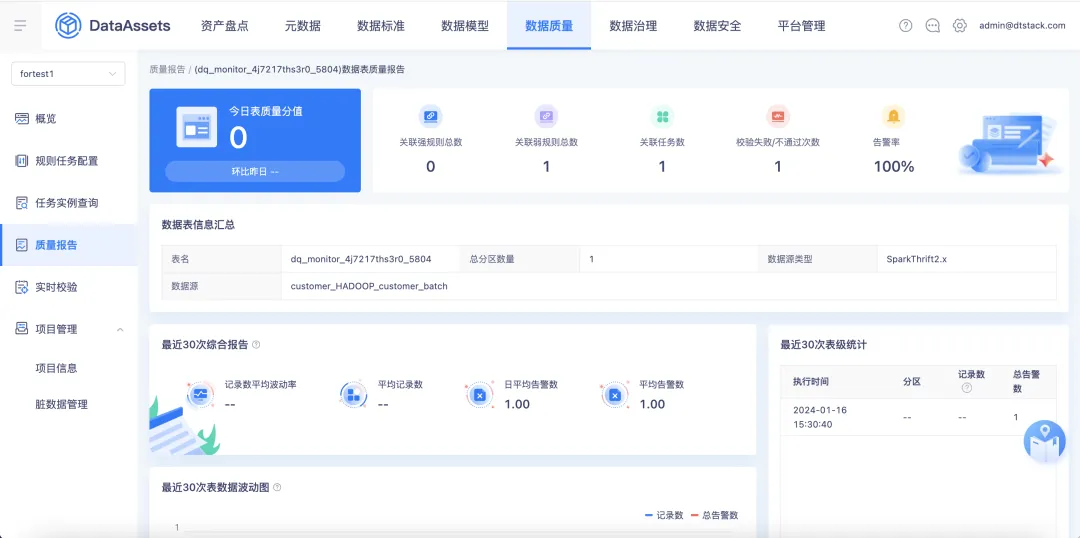
4.数据表质量校验支持质量评分
支持针对单表校验的表级质量报告分析,包含表质量评分、质量分值变化趋势、质量评估概览、近期规则校验异常明细、近期校验结果;质量概览页面新增针对单表校验下各个数据表的表级质量分排名。
5.对接数据标准自动创建质量规则
背景:当出现数据质量的规范性校验和数据标准设定规则基本一致时,优化数据质量的规范性校验规则设计逻辑,支持与数据标准对接。
新增功能说明:在创建数据质量的规范性校验规则时,支持自动对接数据标准来生成质量规则。当【数据质量规则】的【规范性规则】创建时,若识别到选择的字段为绑定了标准的字段,支持选择是否引用标准规则。若选择引用标准规则,则会根据标准中定义的长度、精度、枚举个数、是否空值、是否重复,自动生成质量校验规则。

6.元数据周期同步增加数据库过滤条件
• 元数据周期同步增加数据库过滤条件
• 新增、编辑周期任务按钮优化,调整为支持「新增」以及「新增并立即执行」两个操作按钮
• 元数据周期同步列表增加数据库、数据表的展示
7.支持 tbds_hive 类型数据源
新增支持 tbds_hive 类型数据源,支持范围包括元数据同步、血缘分析、数据地图、元模型、元数据管理、元数据质量、资产盘点、数据安全(数据权限)。
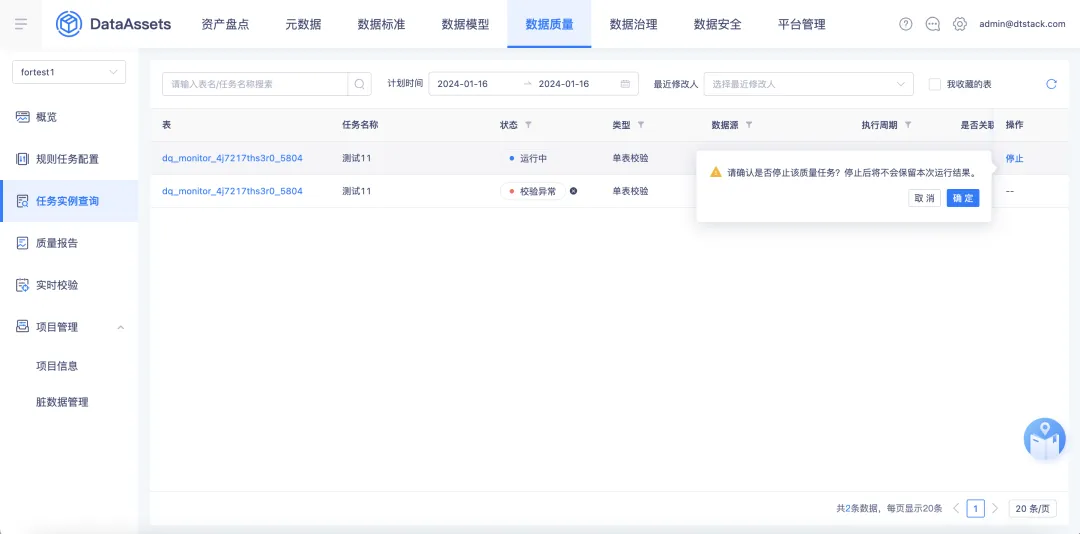
8.质量任务定时执行可以关联自定义调度周期
背景:在配置质量规则时,无法关联自定义调度周期进行质量任务的运行,导致需要个性化配置运行周期时无法满足;在质量任务运行过程中,存在一个质量任务运行时间过长的情况,中途无法停止导致无法释放资源。
新增功能说明:
• 质量规则创建时,在配置调度信息时支持关联自定义调度周期,修改模块包含新建/编辑单表校验规则、多表校验规则、规则集、查看规则详情
• 质量规则创建后,在质量任务运行过程中支持中途停止操作

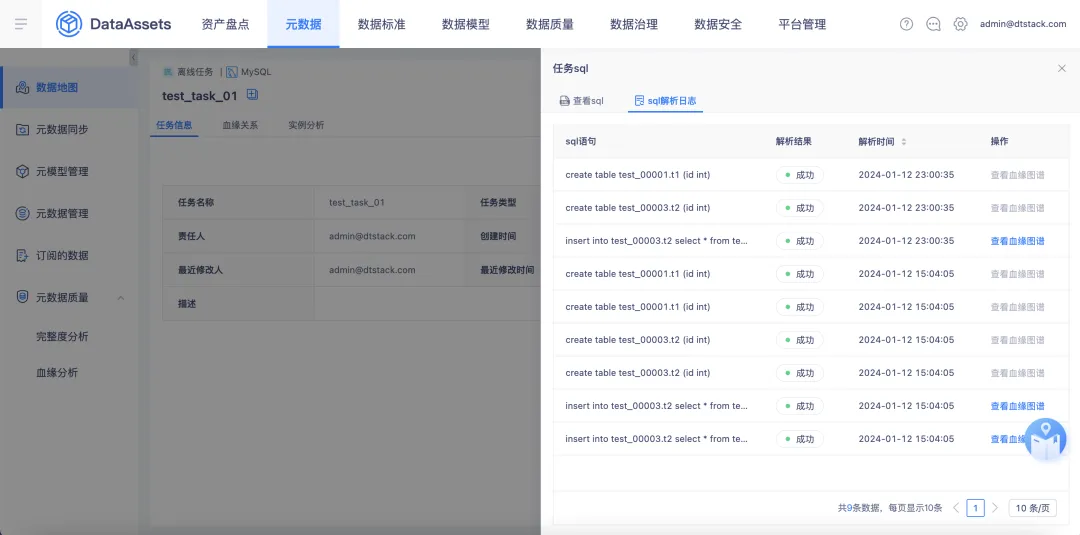
9.支持记录每条 SQL 解析出的血缘关系
在【数据地图】的【离线任务详情】页面,支持对解析 SQL 结果进行记录,包含 SQL 语句、解析结果(成功/失败)、解析时间。针对解析成功的可查看此条 SQL 对应的血缘关系图谱(只展示表级图谱),针对解析失败的可查看日志。
10.数据脱敏支持对识别规则的优先级配置
• 在配置【脱敏规则】的【识别规则】时,支持扩充匹配符的选择,新增「正则」、「包含」选项
• 在配置脱敏规则时,支持定义识别规则的优先级,优先级高的进行优先匹配,若优先级冲突,默认按照最新配置的识别规则进行脱敏应用
• 支持进行脱敏白名单的配置,存在于脱敏白名单内的数据表默认不进行脱敏操作

11.针对单表每个字段可以批量生成校验规则
数据质量管理模块,可以批量配置规则。增加 or 或 and 筛选框,支持用户配置检验规则,新增效果检验规则。
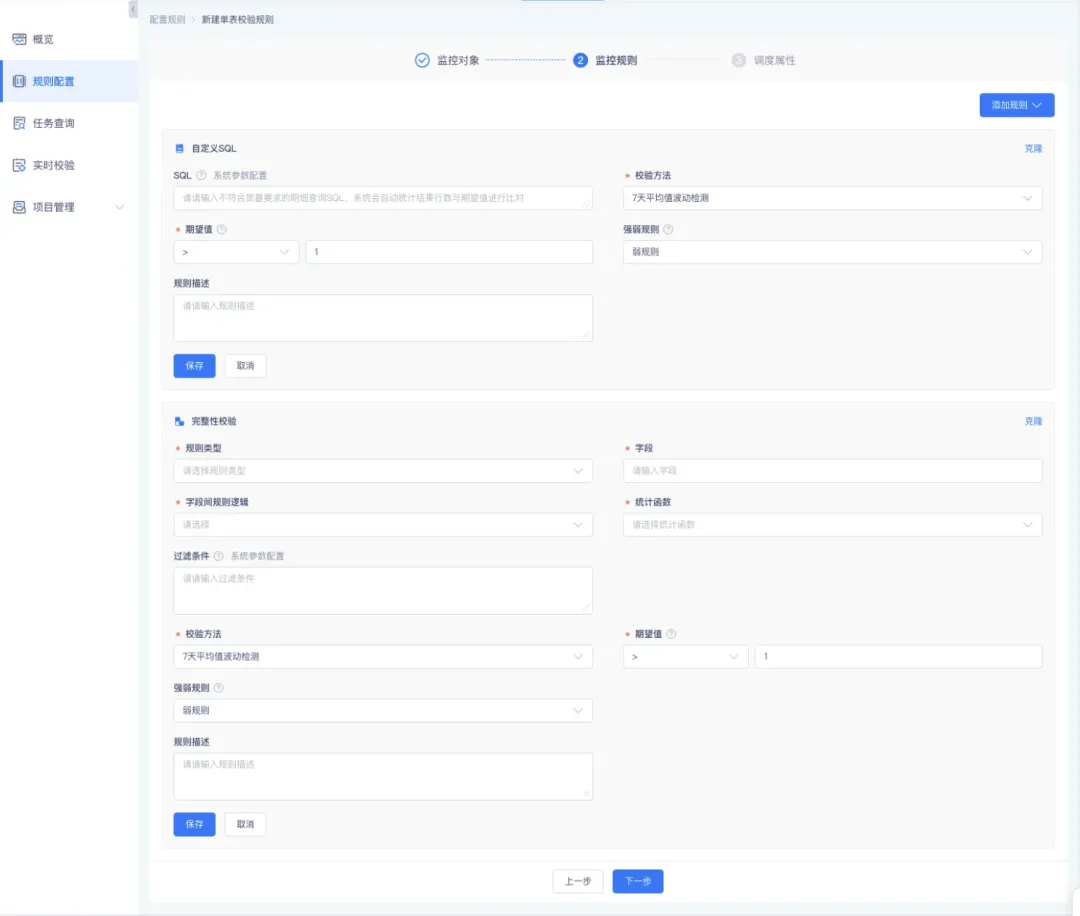
12.新增元数据的展示信息
• 在【数据地图】的【表详情】页面,新增支持在数据表名下方展示表质量评分(若该表无质量评分则不展示),支持点击数据质量评分后跳转至【该数据表的质量报告】

• 表信息新增热度统计按钮,并新增订阅数、使用次数、查看次数、影响表数
• 针对操作记录板块新增 DML 操作记录
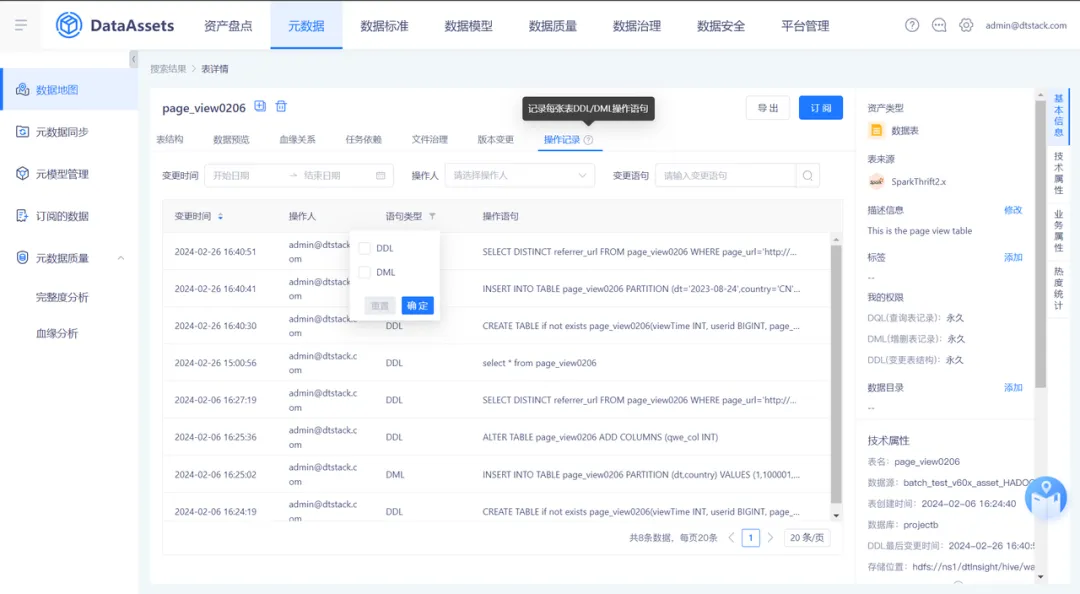
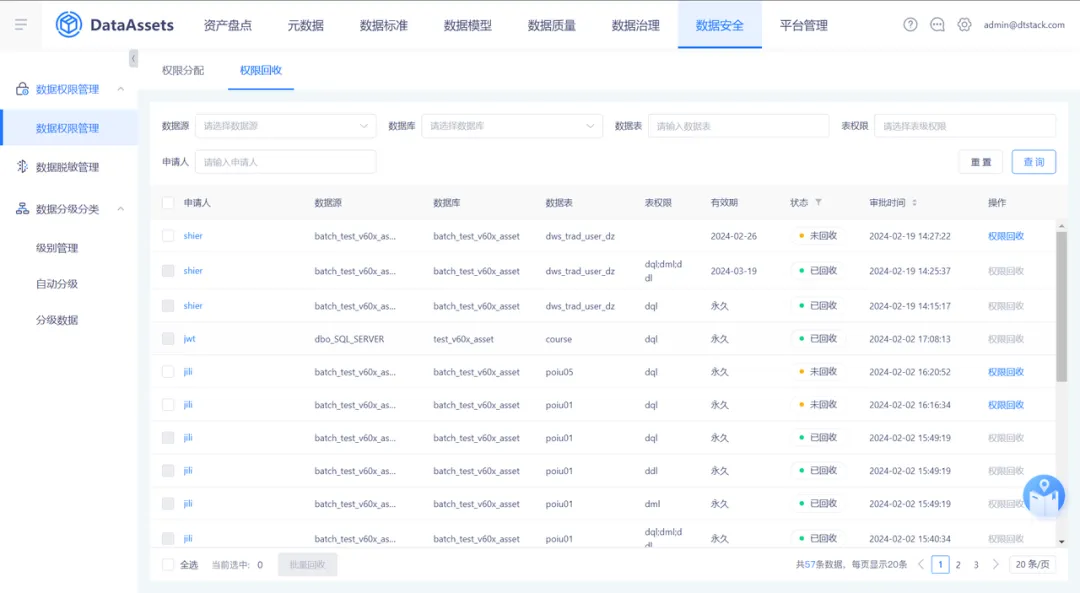
13.数据权限管理新增权限回收功能
在数据权限管理页面新增一个名为【权限回收】的标签页,列表展示每个用户自己申请且已经通过的权限列表。管理员可以通过此功能删除用户的权限信息,默认情况下,只有管理员具备权限回收的权限。
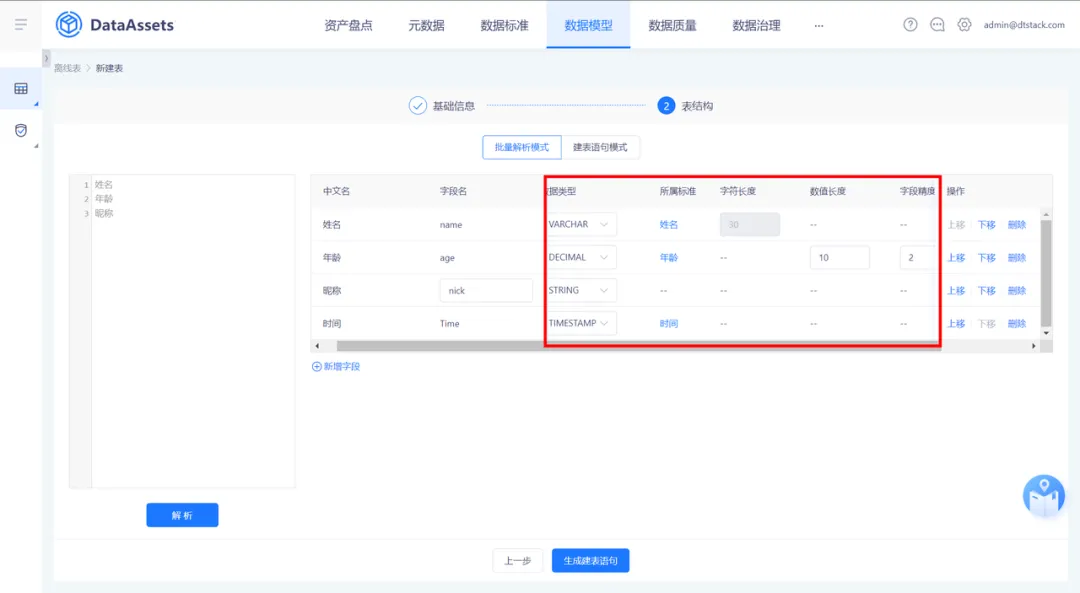
14.规范建表的向导模式配置内容扩充
• 向导模式配置内容扩充:
(1)针对 adb 类型建表支持配置字段是否为主键、是否为空、精度值
(2)针对 inceptor、hive、spark 类型建表支持配置精度值
(3)inceptor 支持配置事务表/非事务表,支持指定 hdfs 存储路径
• 当数据标准中配置了长度、精度信息时,引用标准可自动同步
• 支持 hive3.x(Apache) 类型数据源的建表,建表逻辑和 hive2.x 保持一致
功能优化
1.支持配置表生命周期
背景:此前没有基于数据源、数据库维度批量配置数据表生命周期的入口。
体验优化说明:【元数据管理】页面展示维度修改为「数据源」「数据库」「数据表维度」,支持基于数据源、数据库、数据表维度进行生命周期的批量配置。

2.表行数、存储大小支持显示更新时间
背景:若表行数、存储大小为0,无法区分此表是空表还是没有同步表行数/存储大小,且有可能存在第一次同步了表行数/存储大小,第二次没有同步的情况,故需要记录下最近的更新时间。
体验优化说明:【数据地图】的【数据表详情】中针对表行数、存储大小支持显示更新时间。
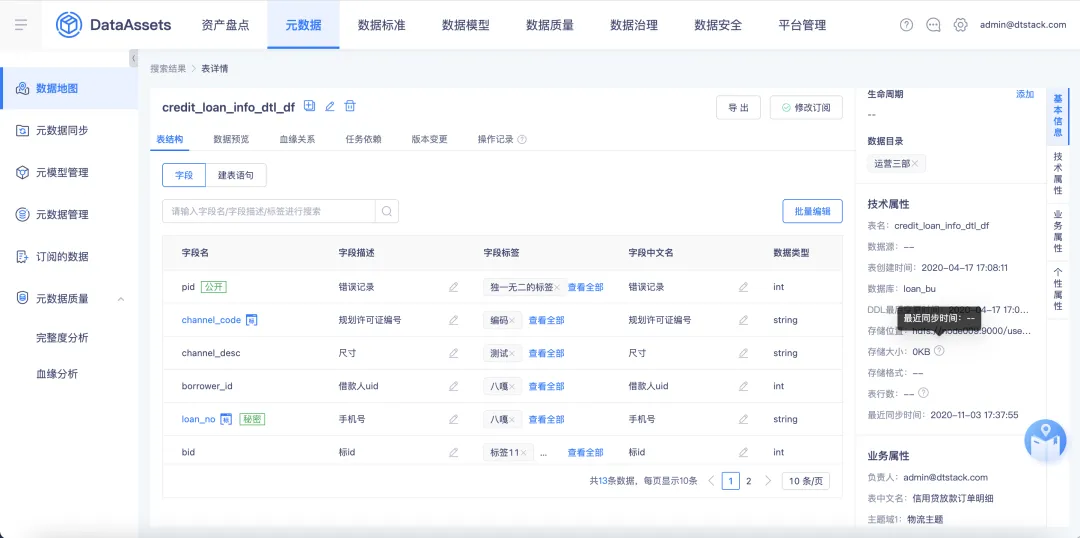
3.字段中文名支持修改
背景:目前数据地图中字段中文名、字段描述的取值逻辑是拿的建表语句中的 comment 字段,字段描述可修改,字段中文名也需要对应得调整为可修改。
体验优化说明:【数据地图】中的【表详情】页面针对字段中文名支持修改操作,支持单个修改/批量操作。
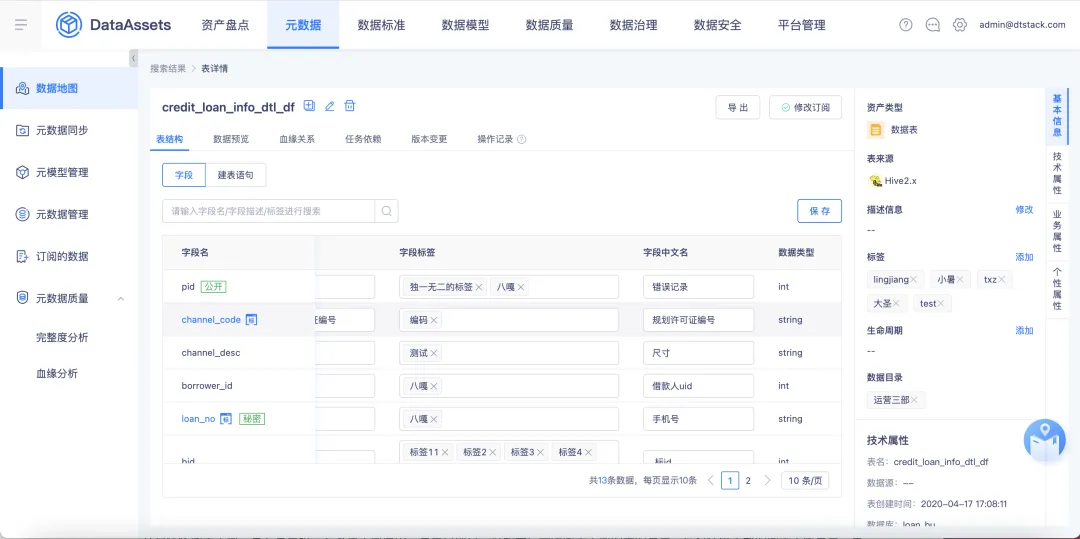
4.在编辑表的业务属性时需提示最大字符长度限制
背景:针对表的业务属性为 string 类型的默认长度为100,目前在编辑表的业务属性的时候没有长度提示,且默认长度较小,会存在某些业务场景长度超限的情况。
体验优化说明:针对业务属性为 string 类型的,默认值的最大长度为255字符,并且在编辑业务属性页面进行最大长度提示。
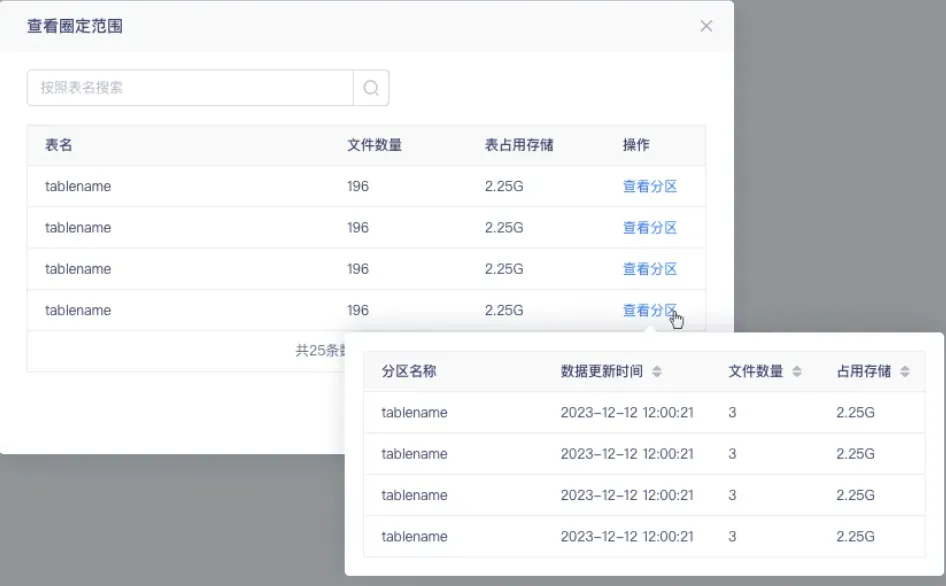
5.「小文件治理」 周期治理规则配置优化
对周期治理规则的规则配置页面进行优化,针对分区表,设置【查看分区】操作,点击展示每个分区表对应的文件数量。
6.元数据同步(日志)优化
· 同步失败的表,不仅展示表名,还展示这个表所属数据库
· 元数据同步时,针对每个同步实例,同步表数量、全部表数量的计算优化
• 日志在同步表记录列表中可以查看每个同步失败的表的日志
7.字段类型设置 varchar 支持自定义字符长度
字段类型 varchar 支持自定义字符长度。在数仓层级设置中,数仓层级为非必选字段。如果用户未选择数仓层级,表名的前缀无信息。
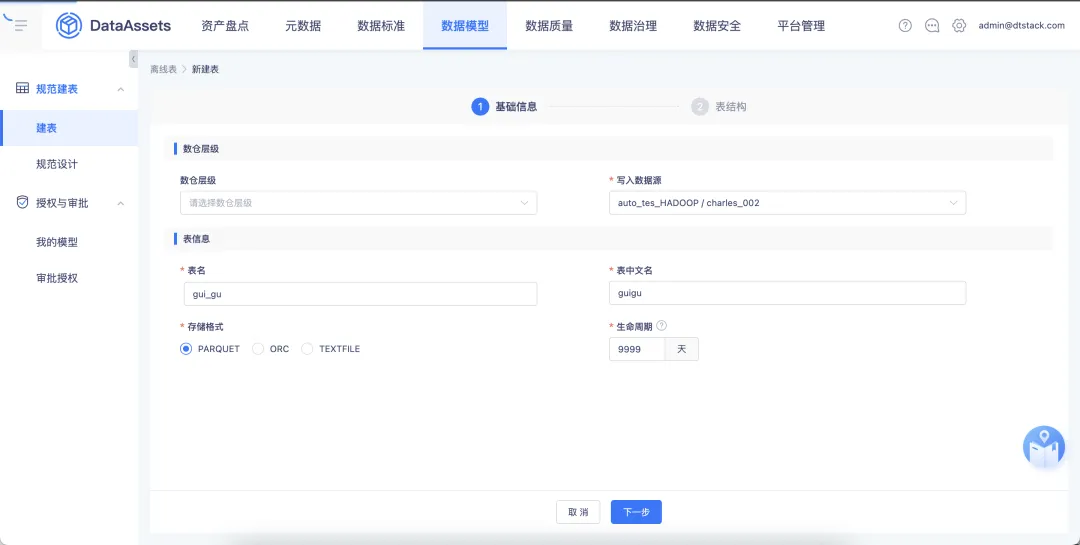
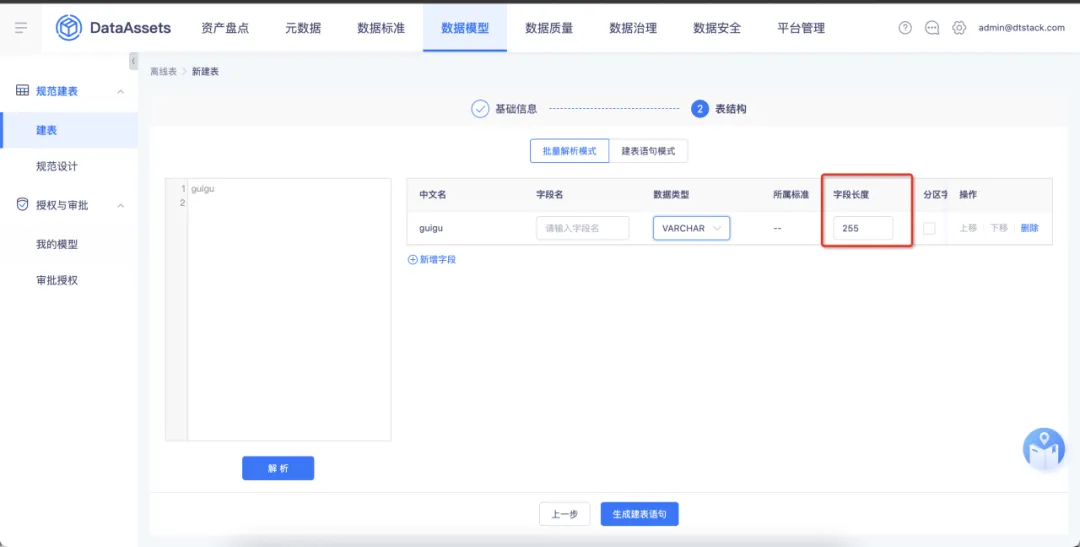
8.数据模型建表时支持配置分区范围
性能优化,方便用户在创建时能自定义分区范围,减少操作流程,完善用户体验。
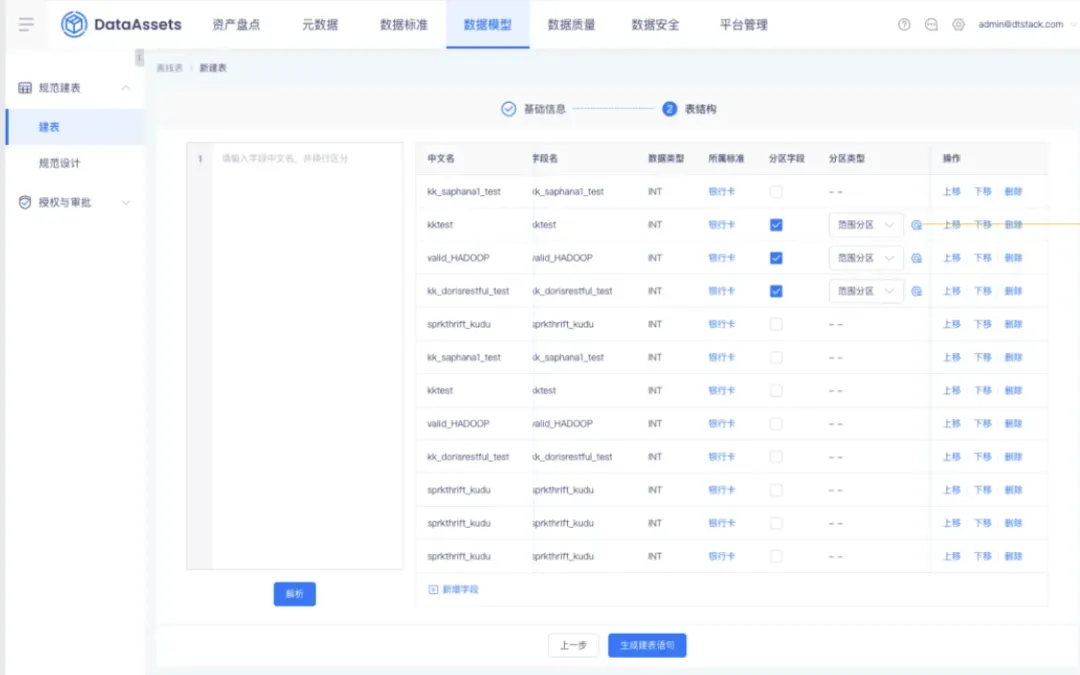
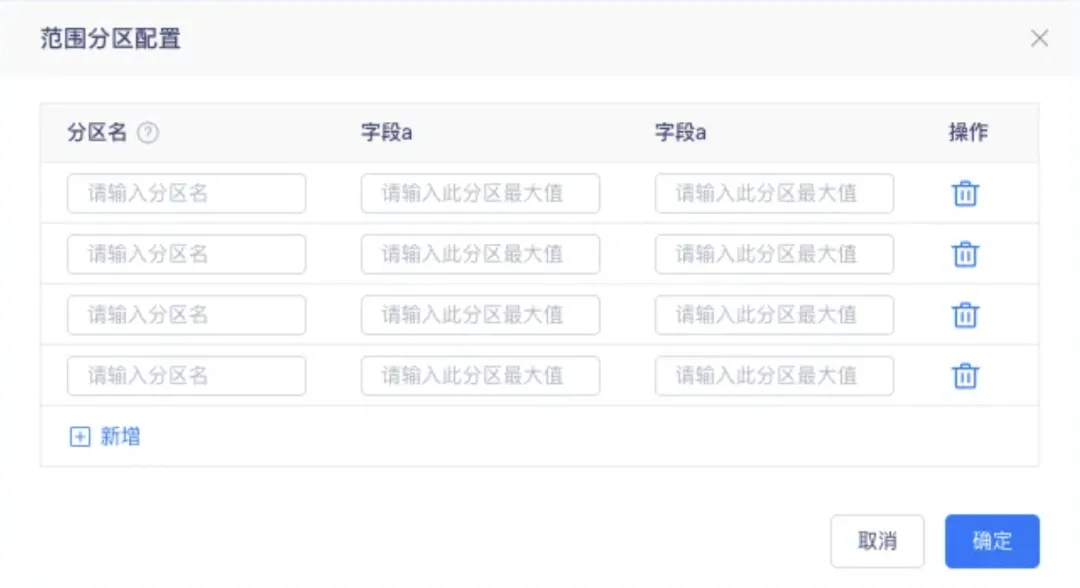
9.支持 meta 数据源的自动引入
数据资产平台针对所有的子产品(离线、指标、标签)都支持 meta 数据源的自动引入。同时针对指标、标签,支持指标标签生成的 trino 类型 meta 数据源的自动引入。
10.可定义资产概览中展示的默认数据源
可定义默认展示数据源(按照数据源、数据库、数据表数量排序)最多的数据源类型。例如如果用户 spark 数据源下面的数据源数量最多,默认的就展示 spark 类型,涉及到的展示模块包含资产盘点页面以及元数据管理页面。
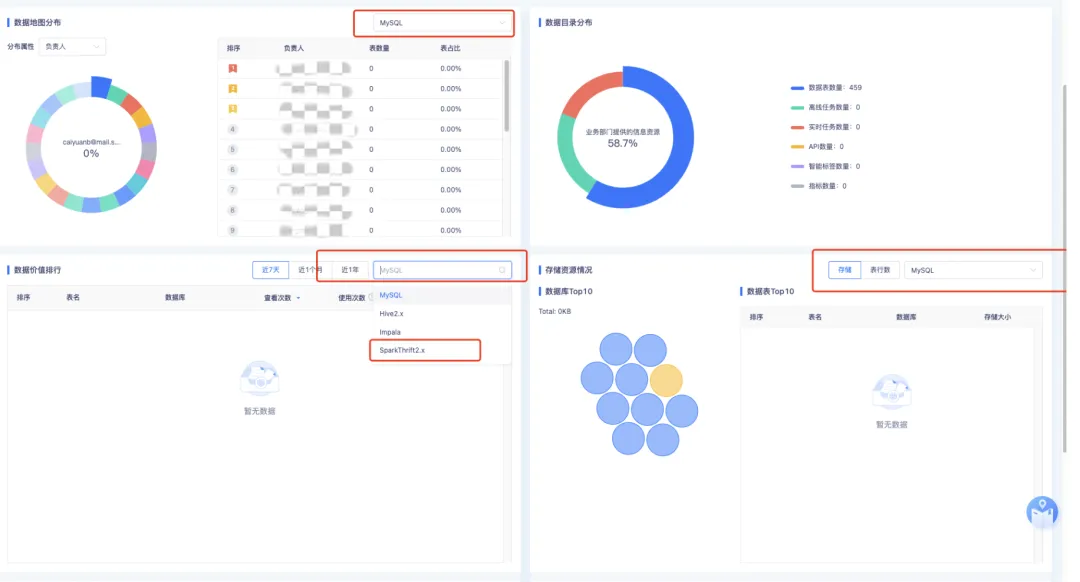
11.【资产盘点】数据价值排行逻辑优化
背景:数据价值排行最大可统计最近一年的数据,由于后端存储的是全量数据,随着时间的推移,数据量将不断增加,影响查询性能。
体验优化说明:对【资产盘点】页面的数据价值排行进行逻辑优化,后端仅保留最近一年的数据,以优化性能。
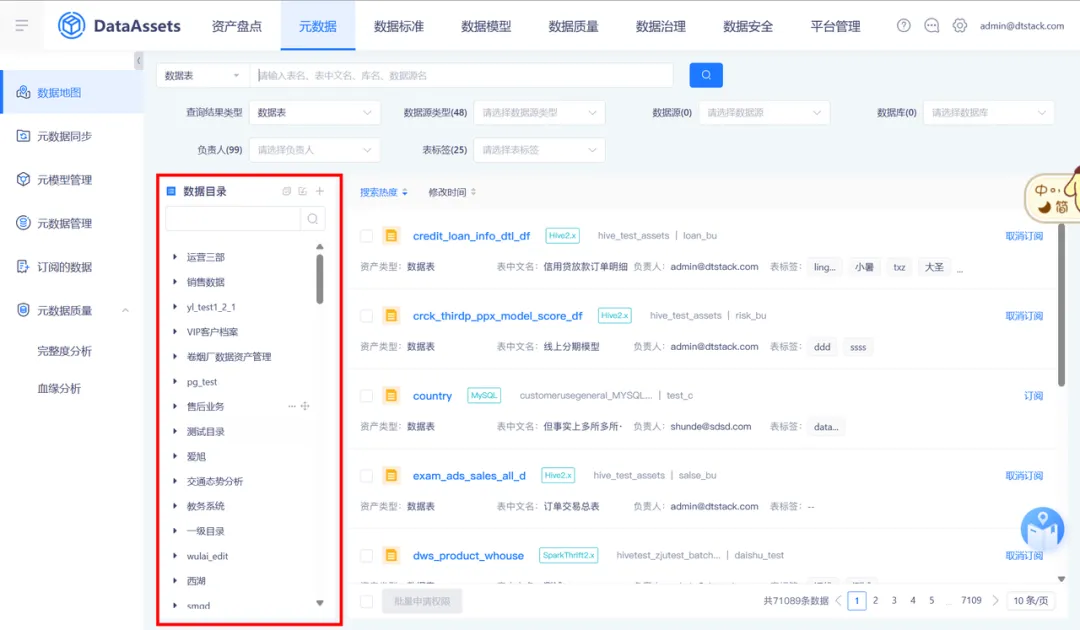
12.数据目录显示和拖动优化
背景:【数据目录】因左侧栏固定宽度,导致目录显示不全。
体验优化说明:【数据地图】的【数据目录】、【数据标准】的【码表管理】、【数据标准】的标准管理(包括标准定义和标准映射)、【数据安全】的【自动分级】的【数据目录】支持左右拉伸,支持选择该层级的整个范围进行拖动。
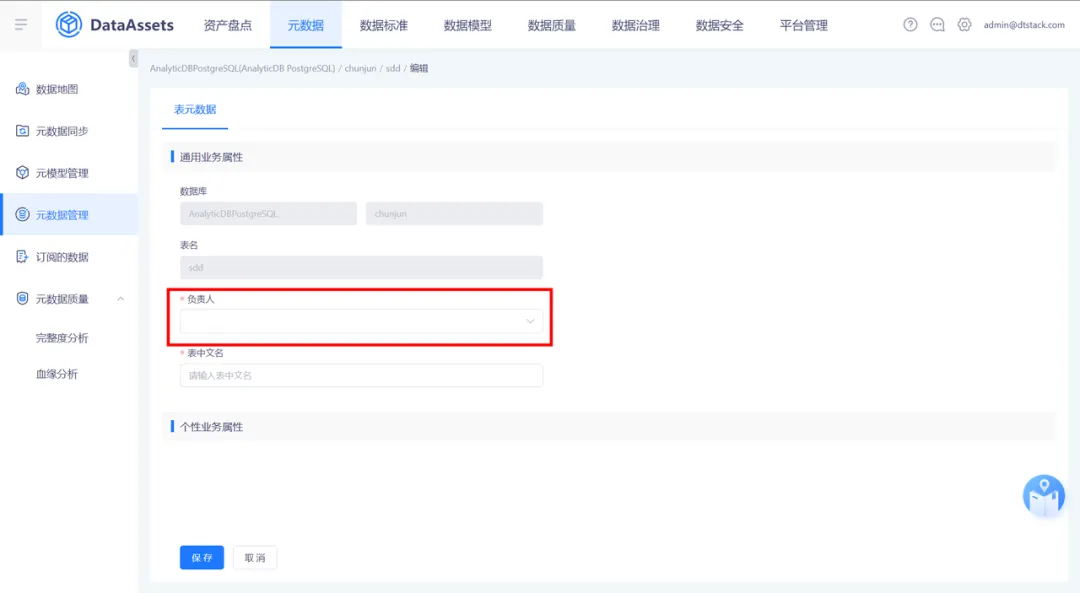
13.支持对表负责人的权限点管理
表负责人变更为非必填属性,针对没有表负责人修改权限的用户,点击编辑业务属性页面时,无编辑“表负责人”选择框
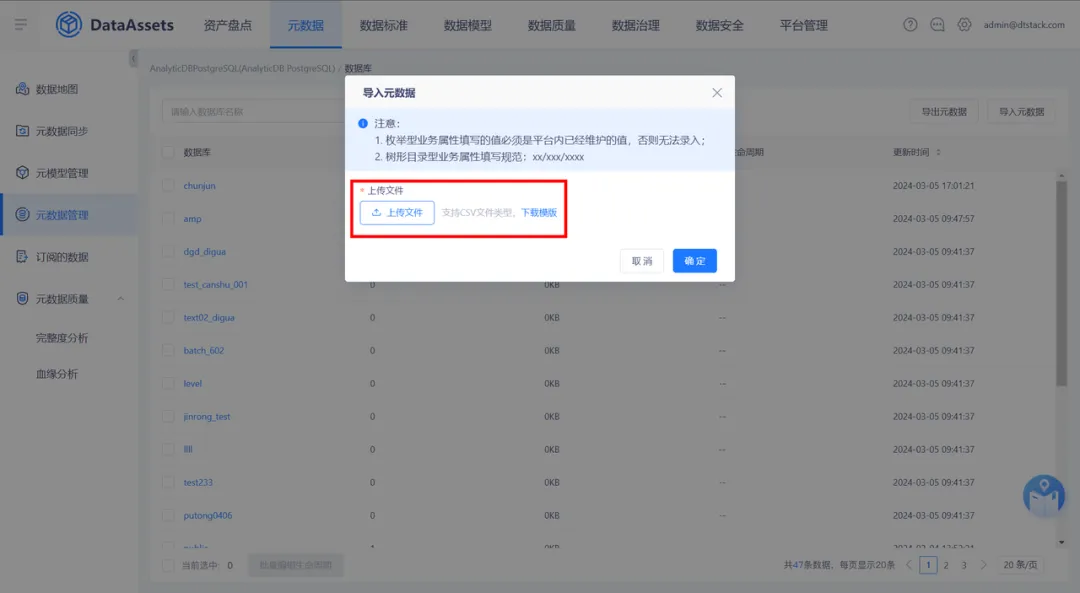
针对没有表负责人修改权限的用户,上传文件后需要校验上传用户是否有表负责人的编辑权限,若无编辑权限,则导入的表负责人不生效(数据开发和访客角色默认无表负责人修改权限)
14.单表校验波动检测结果取值调整为取最新值
针对单表校验中波动检测结果取值,表行数的1天波动性检、表行数的7天波动检测、月度波动检测取值修改为取最新值。
15.告警通道配置校验优化
背景:当控制台未设置邮件默认告警通道,在进行质量配置告警/其他通知时不会提示,会导致发告警失败。
体验优化说明:在配置通知时,将校验邮件、短信是否已配置告警通道,若未配置,会提示用户“短信/邮件未配置告警通道,请先确认告警通道配置完成后再进行通知信息配置。”(涉及模块包含:元数据周期同步告警;元数据实时同步告警;数据质量单表校验、多表校验、规则集告警;数据治理治理任务配置通知、指派人通知;表订阅通知)

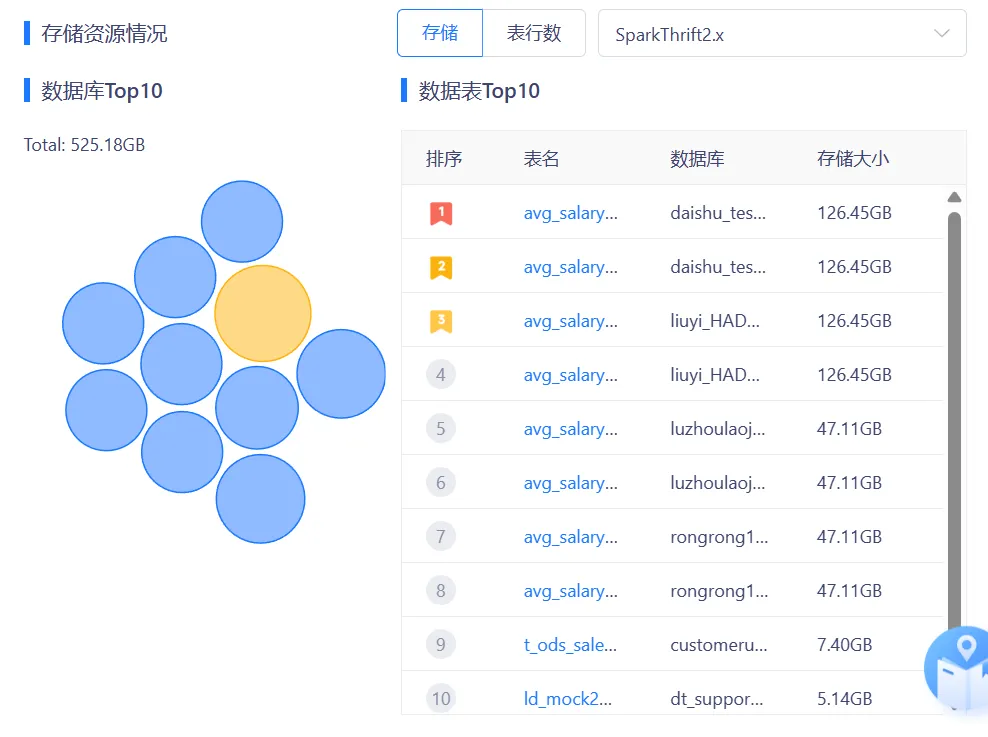
16.存储资源情况筛选框保留数据源选择状态
若选择框中已经选择数据源,不论是存储切换为表行数,还是表行数切换为存储,数据源的选择状态都保持不变。
数据服务平台
新增功能更新
1.数据源中心增加逻辑
背景:为确保数据源中心与数据服务的同步开发,每次开发新数据源时,都需要与数据服务并行进行。为了避免数据源中心提前开发完成而数据服务尚未对接,导致新数据源无法上线的问题,API 需要增加新的逻辑来预防这种情况的发生。
新增功能说明:对数据源管理增加过滤逻辑,对于数据服务未支持的数据源做过滤,在数据服务对接该数据源后,再添加进数据源管理。
功能优化
1.da_invoke_log 表相关优化
• 对同一用户,在一段时间内因登陆失败写入数据库的数据做最大条数的限制,最大程度上保障数据的安全
• 对 da_apply_invoke 表 SQL 查询进行优化
2.发布内容优化
背景:当前发布内容,仅可发布API,这样会造成当从测试环境发布至生产环境后,关联的行级权限、告警配置等无法生效,致使数据安全出现问题。
体验优化说明:对发布内容进行了改进,现在可以单独发布行级权限、API、告警策略和熔断策略等,也可以将它们组合打包发布。这样做可以确保生产环境中的 API 保持稳定,用户可以更安全、高效地使用。
指标管理平台
新增功能更新
1.指标发布/下线对接审批中心
背景:指标发布/下线都是重要操作,需要增加审批流程以提高操作的安全性。由于数栈中已经有审批功能模块,所以直接对接现有审批流程。
新增功能说明:
超级管理员可在【公共管理】-【审批中心】-【流程管理】中设置审批流程。指标发布和下线都有对应的内置流程,分别是「指标发布审批」和「指标下线审批」,默认应用于所有租户,只有一个审批节点,审批人为申请发生的租户下的项目管理员、项目所有者、租户管理员和租户所有者。
确认当前租户开启了对应的审批流程之后,加入了【指标管理】的项目的用户可在【指标中心】界面对指标进行发布/下线的申请操作。
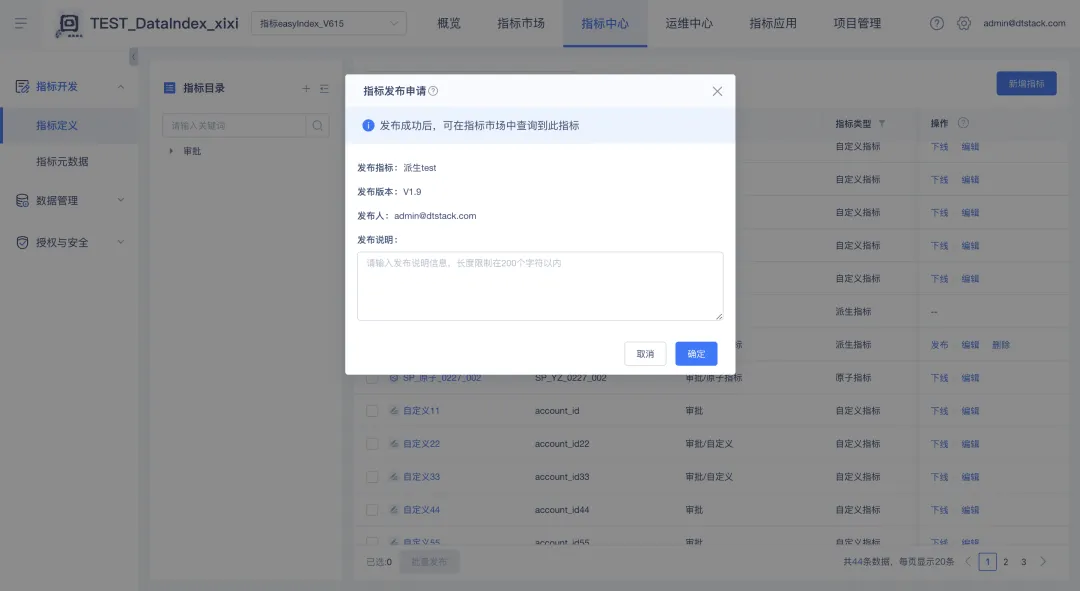
用户可在【审批中心】-【我的申请】-【审批中】中查看自己已经提交的申请的审批进度,也可以取消审批流程未完成的申请,取消申请后将终止审批流程。

审批人可在【审批中心】-【审批授权】界面中审批已经提交的申请。审批节点上的任一审批人通过之后,则该申请通过该审批节点。申请通过所有审批节点后,则该申请变为「已通过」状态,该指标发布/下线申请生效,指标的发布状态随之更改为「已发布」或「已下线」状态。
2.指标属性自定义
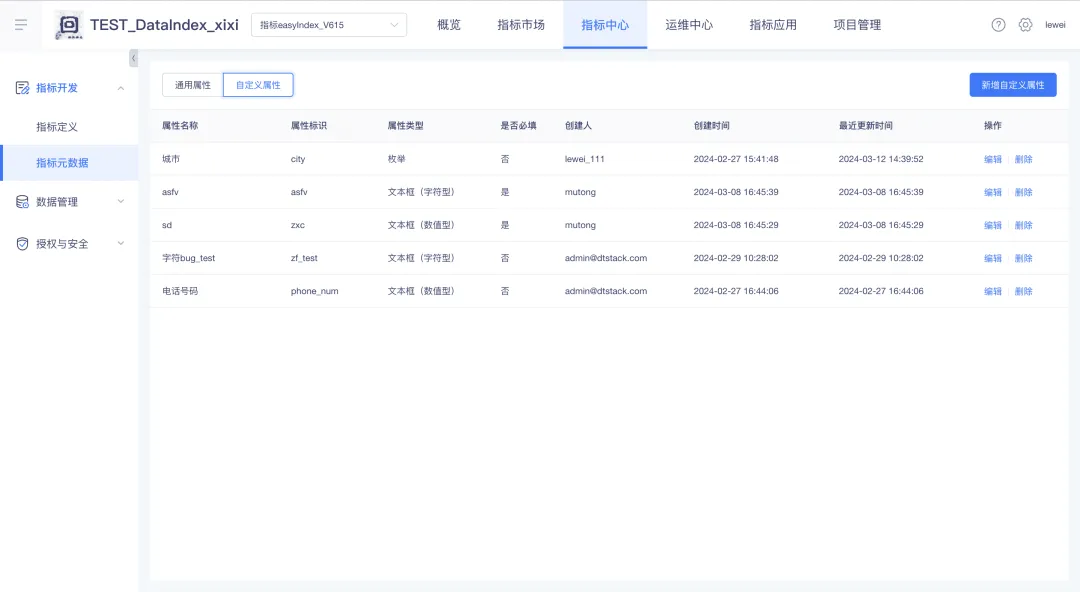
背景:目前指标基本信息中的属性都是平台内置属性,实际使用中客户会存在需要使用自定义属性的场景,比如指标等级、指标负责部门等,所以需要支持指标属性自定义的功能,方便客户自定义指标属性,并在加工指标的时候进行填写,提升指标使用体验。
新增功能说明:在【指标开发】中新增【指标元数据】功能,用户可以在【指标元数据】界面中查看通用属性(即平台内置属性),查看和管理自定义属性。

功能优化
1.行级权限根据动态值选择匹配字段时,可选到用户管理中的所有字段
之前仅支持选到用户管理中的固有属性字段,现在增加支持选到自定义属性字段。
《行业指标体系白皮书》下载地址:https://www.dtstack.com/resources/1057?src=szsm
《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
热门相关:梁医生又在偷偷套路我 终极高手 呆萌配腹黑:欢喜小冤家 逍遥小镇长 逆流纯真年代