构建无服务器数仓(三 )EMR Serverless 操作要点、优化以及开放集成测试
引言
在数据驱动的世界中,企业正在寻求可靠且高性能的解决方案来管理其不断增长的数据需求。本系列博客从一个重视数据安全和合规性的 B2C 金融科技客户的角度来讨论云上云下混合部署的情况下如何利用亚马逊云科技云原生服务、开源社区产品以及第三方工具构建无服务器数据仓库的解耦方法。

本篇博客着重探讨 EMR Serverless 的操作要点、优化以及开放集成测试。如有兴趣,各位看官请看前几篇文章回顾一下:
搜索关键词:
构建无服务器数仓(二)Apache DolphinScheduler 集成以及 LOB 粒度资源消费分析
利用Amazon EMR Serverless、Athena与Dolphinscheduler构建云上云下数据同步方案
架构设计图
EMR Serverless Job 操作要点
理解 Application 和 Job 的概念
EMR Serverless Application 是一个资源池的概念。应用程序拥有一定的计算能力, 内存以及供在其上运行的作业使用的存储资源。资源容量也可以通过命令行和 Web 控制台进行配置。
作为一个资源池,EMR 无服务器应用程序的创建通常是一次性操作。一旦设置了引擎(spark/hive),就创建了一个应用程序,初始容量和最大容量已经规划好。由于应用程序的创建并不频繁,因此通过 Web 控制台创建应用程序是一种可行的方式。
以下亚马逊云科技 CLI 示例命令显示了如何创建 EMR 无服务器应用程序:
aws emr-serverless create-application \
--type HIVE \
--name <specific application name> \
--release-label "emr-6.6.0" \
--initial-capacity '{
"DRIVER": {
"workerCount": 1,
"workerConfiguration": {
"cpu": "2vCPU",
"memory": "4GB",
"disk": "30gb"
}
},
"TEZ_TASK": {
"workerCount": 10,
"workerConfiguration": {
"cpu": "4vCPU",
"memory": "8GB",
"disk": "30gb"
}
}
}' \
--maximum-capacity '{
"cpu": "400vCPU",
"memory": "1024GB",
"disk": "1000GB"
}'
以下 snapshot 显示了如何通过亚马逊云科技 Web 控制台配置 EMR 无服务器应用程序的资源容量:

EMR Serverless Job 是实际处理计算任务的工作单元。为了使作业正常运行,需要设置 EMR Serverless Application ID、执行 IAM 角色(稍后将介绍如何配置角色)、具体的应用程序配置(例如作业正在规划的资源)使用)需要设置。
虽然 EMR Serverless 作业可以通过 Web 控制台创建,但由于作业的生命周期比应用程序要短得多,因此建议通过命令行完成作业生命周期管理。
以下是将 EMR 无服务器作业提交到 EMR 无服务器引擎的示例亚马逊云科技 CLI 命令。
aws emr-serverless start-job-run \
--application-id $applicationId \
--execution-role-arn $JOB_ROLE_ARN \
--job-driver '{
"hive": {
"initQueryFile": "s3://<bucket name>/<specific prefix>/create_fdm_table.sql", #DDL SQL for instance
"query": "s3://<bucket name>/<specific prefix>/ingest_fdm_data.sql", #DML SQL for instance
"parameters": "--hiveconf hive.exec.scratchdir=s3://<bucket name>/hive/scratch --hiveconf hive.metastore.warehouse.dir=s3://<bucket name>/hive/warehouse"
}
}' \
--configuration-overrides '{
"applicationConfiguration": [
{
"classification": "hive-site",
"properties": {
"hive.driver.cores": "2",
"hive.driver.memory": "4g",
"hive.tez.container.size": "8192",
"hive.tez.cpu.vcores": "4"
}
}
],
"monitoringConfiguration": {
"s3MonitoringConfiguration": {
"logUri": "s3://<bucket name>/hive-logs/"
}
}
}'
EMR 无服务器工作角色创建
作业角色需要有权访问特定的 S3 存储桶以读取作业脚本并可能写入结果,同时需要有权访问 Glue 以读取存储所有表元数据的 Glue Catalog。
- 创建 IAM 角色
aws iam create-role --role-name emr-serverless-job-role --assume-role-policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "emr-serverless.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}'
- 将角色附加到策略以启用 S3 存储桶访问
aws iam put-role-policy --role-name emr-serverless-job-role --policy-name S3Access --policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ReadFromOutputAndInputBuckets",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<specific bucket name>",
"arn:aws:s3:::<specific bucket name>/*"
]
},
{
"Sid": "WriteToOutputDataBucket",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::<specific bucket name>/*"
]
}
]
}'
- 将角色附加到策略以启用 Glue 权限
aws iam put-role-policy --role-name emr-serverless-job-role --policy-name GlueAccess --policy-document '{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "GlueCreateAndReadDataCatalog",
"Effect": "Allow",
"Action": [
"glue:GetDatabase",
"glue:GetDataBases",
"glue:CreateTable",
"glue:GetTable",
"glue:GetTables",
"glue:GetPartition",
"glue:GetPartitions",
"glue:UpdateTable",
"glue:CreatePartition",
"glue:BatchCreatePartition",
"glue:GetUserDefinedFunctions"
],
"Resource": ["*"]
}
]
}'
EMR Serverless Job 状态监控
applicationId=$(redis cli GET applicationId_LOB1)
app_state{
response2=$(aws emr-serverless get-application --application-id $applicationId)
application=$(echo $response1 | jq -r '.application')
state=$(echo $application | jq -r '.state')
return state
}
state=app_state()
while [ $state!="CREATED" ]; do
state=app_state()
done
response2=$(emr-serverless start-application --application-id $applicationId)
state=app_state()
while [ $state!="STARTED" ]; do
state=app_state()
done
response3=$(aws emr-serverless start-job-run \
--application-id $applicationId \
--execution-role-arn $JOB_ROLE_ARN \
--job-driver '{
"hive": {
"initQueryFile": "s3://shiyang-noaa-gsod-pds/create_table_1.sql",
"query": "s3://shiyang-noaa-gsod-pds/extreme_weather_1.sql",
"parameters": "--hiveconf hive.exec.scratchdir=s3://<bucket name>/hive/scratch --hiveconf hive.metastore.warehouse.dir=s3://<bucket name>/hive/warehouse"
}
}' \
--configuration-overrides '{
"applicationConfiguration": [
{
"classification": "hive-site",
"properties": {
"hive.driver.cores": "2",
"hive.driver.memory": "4g",
"hive.tez.container.size": "8192",
"hive.tez.cpu.vcores": "4"
}
}
],
"monitoringConfiguration": {
"s3MonitoringConfiguration": {
"logUri": "s3://<bucket name>/hive-logs/"
}
}
}')
JOB_RUN_ID=$(echo $response3 | jq -r '.jobRunId')
#store job_run_id into redis
redis-cli SET job_run_id_LOB1 $JOB_RUN_ID
response4=$(aws emr-serverless get-job-run --application-id $applicationId --job-run-id $JOB_RUN_ID)
jobRun=$(echo $response4 | jq -r '.jobRun')
JOB_RUN_ID=$(echo $jobRun | jq -r '.jobRunId')
JOB_STATE=$(echo $jobRun | jq -r '.state')
EMR Serverless 优化
使用最新的 EMR 版本
强烈建议使用最新的 EMR 版本,因为最新版本具有最新的性能。截至目前(2024 年 4 月),EMR Serverless 最新版本为 emr-7.0.0。
利用 ARM 架构
强烈建议选择 arm64 EMR 架构而不是 x86_64 EMR 架构,因为前者可以提供更具成本效益的性能。
将 Hive 作业转换为 Spark SQL 作业
EMR Serverless 的 Hive 作业引擎是 Tez,这意味着 EMR Serverless 目前不支持 Hive on Spark。
在实践中,我们发现即使在 EMR Serverless 上运行的 Hive on Tez 也比在客户本地环境中运行的 Hive on Spark 更快。如果将 Hive Job 转换为 Spark SQL Job 并利用 spark 引擎,作业的性能可以进一步提升。
由于这种 Hive SQL 转换 Spark SQL 并不复杂,只需将 Hive SQL 包装在 Spark 语句中即可,如果对性价比有硬性要求,这样的转换是相当可行的。
具体配置每个作业的资源配置,然后配置每个应用程序的资源配置
上述 3 种优化 EMR Serverless Job 性能的方法不需要考虑每个作业的具体上下文。
还有另一种实现 EMR Serverless 作业性能优化的方法,需要分析每个应用程序以及每个作业的容量利用率和执行时间。
如果在很短的时间(例如秒级)内完成一项复杂的工作,并且消耗非常大的资源池,例如数千个 vCPU,数万 GB 内存,优化方向可能是将资源限制在一定水平,以使其具有可比性。低成本与工作完成时间的平衡。
开放集成测试
使用 scala 或 python(pyspark)在 spark 中进行传统开发方式的先决条件是需要在工程师的笔记本电脑或专用于开发的主机上部署 IDE(可以是 VSCode 或 IntelliJ)。
工程师编写代码并使用该机器上存储的示例数据完成自测试。之后,如果用 scala 编写,则应通过 sbt 将代码打包为 jar 文件;如果用 pyspark 编写,则应将代码打包为脚本。
然后将 jar/script 文件上传到集成开发环境,通过执行 spark xxx.jar/xxx.py 命令,可以对代码进行集成测试。
这种对 spark 代码进行集成测试的方式是一种封闭的方式:如果在集成测试中发现了 bug,工程师不可能直接在集成开发环境中进行调试,因为代码已经被包装为 jar/脚本文件。
他/她必须通过他/她的自测试环境(部署在他/她的笔记本电脑上的 IDE)完成调试工作。这种集成测试的方式会受到很大的影响,特别是当代码需要调试相当长的时间才能达到正确的状态时,考虑到业务逻辑本身很复杂。
EMR Serverless 提供 EMR Studio,可以实现开放的集成测试方式。该代码是通过 Jupyter 笔记本单元编写和测试的。上游数据源和下游数据目的地可以通过在单元中编写代码来连接。然后,测试的代码可以打包为 Spark jar 文件或 pyspark 脚本文件,最后作为 EMR 无服务器作业提交。
步骤 1:创建 EMR Studio
步骤 2:创建一个 Interactive Application
通过按照下面的快照设置配置来创建交互式应用程序:
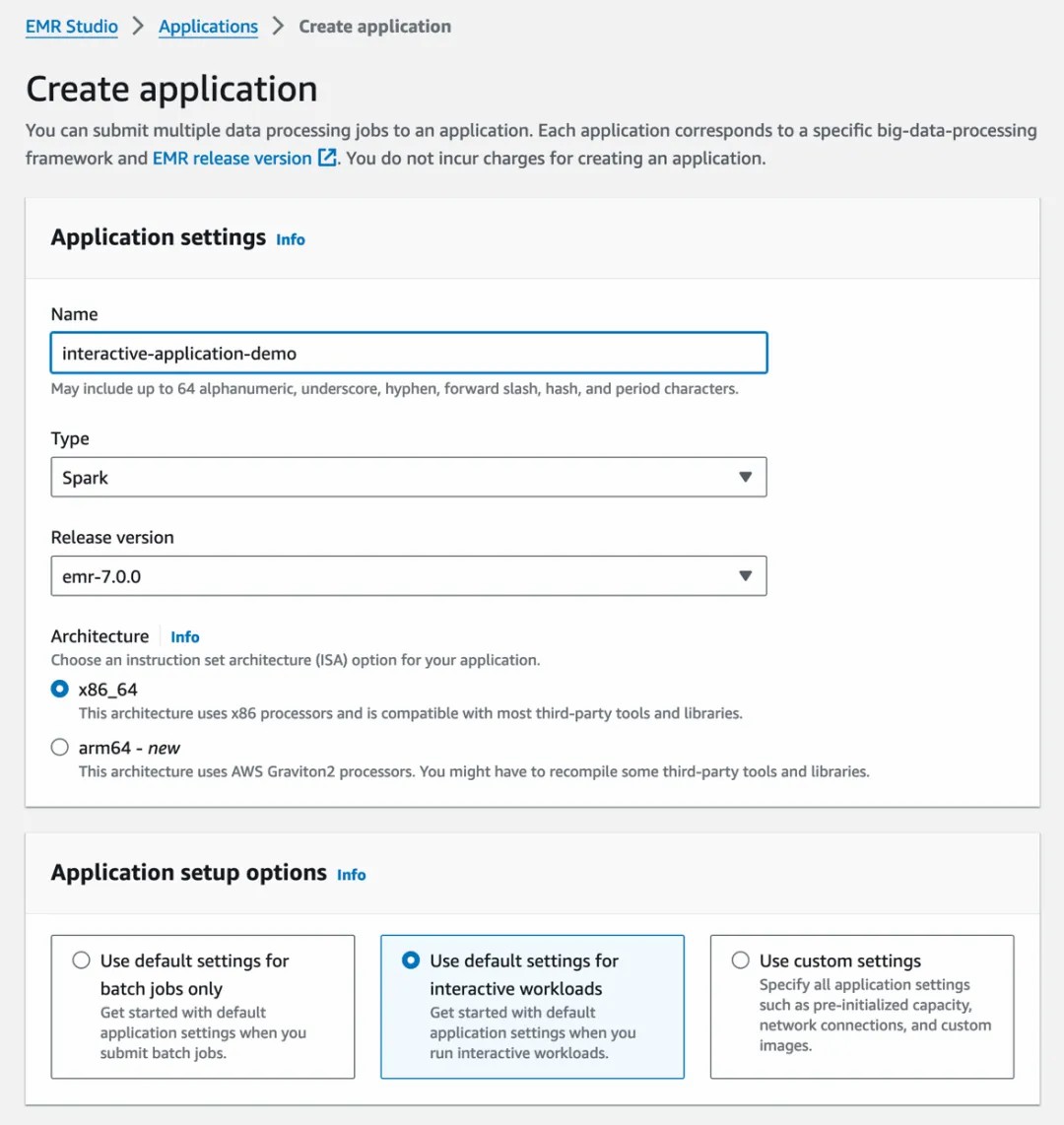
步骤 3:在 EMR Studio 下创建 Workspace
在 EMR Studio 下创建一个工作区,如下图所示:
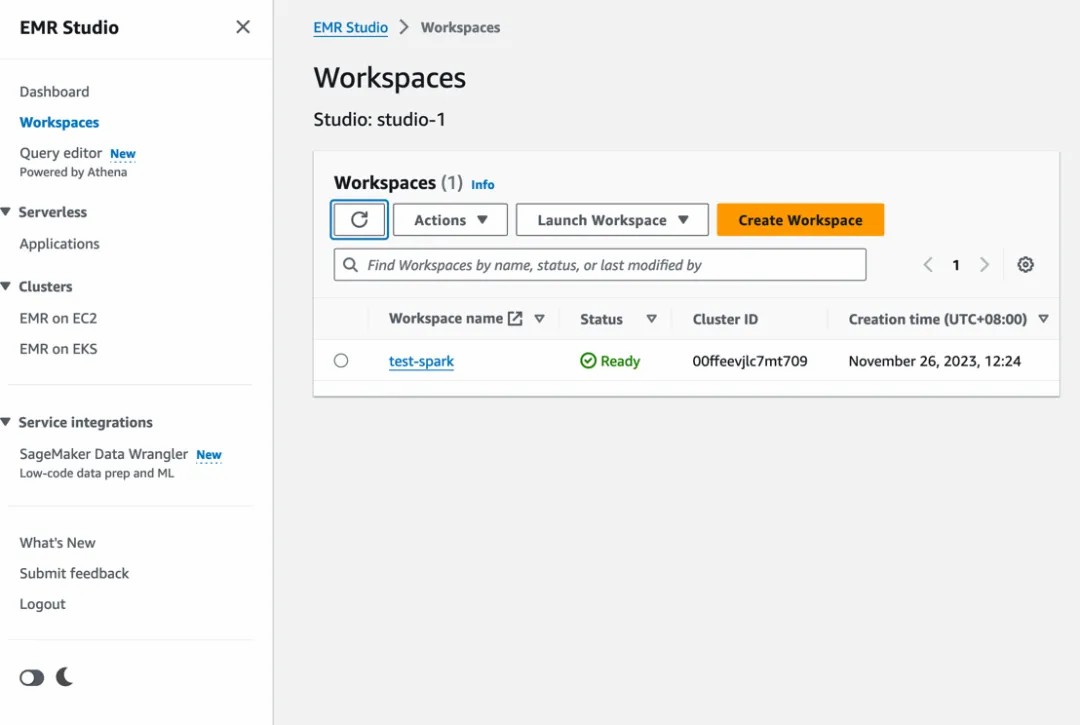
步骤 4:启动工作区,并将笔记本与第二步中创建的交互式应用程序和上一节中创建的工作角色 attach 在一起

总结
Serverless 的数仓平台的优势总结如下:
(1)解决了原有平台算力瓶颈问题,显著地提升了平台整体运行效率
原有的最长的数据处理任务需要十几个小时才能完成。同样的任务在新平台上运行 2 – 3 个小时就可以完成)。
原有的 hive@cdh 即便已经使用 spark 作为引擎,同样的 job 运行比新平台要慢不止 4-5 倍。
(2)数据调度平台和数据处理引擎、数据存储介质完成了架构解耦,显著地提高了平台的健壮性和扩展性
原有的平台,数据调度工具 DolphinScheduler,大数据集群的计算和存储都强耦合的运行在 CDH 集群上。集群的任何一个 module 出现问题,都可以导致集群的不可用,进而导致其他 module 都不可用。
具体说,计算引擎和存储是最容易出现问题的部分,如果原有的集群出现了内存溢出或者存储容量被打满而导致集群不可用的情况,会连带地导致调度工具 DolphinScheduler 的不可用以及存储或者计算的不可用。
新的平台的解耦架构实现了调度工具、计算引擎、存储介质的解耦,避免了这些问题。同时计算引擎采用 Serverless 架构,可以根据 Job 的需要动态的进行最优的算力匹配。存储介质的 S3 也可以进行几乎无限制的扩容,保证业务的需要。
(3)新平台为后续的精细化运营提供了可能
新平台可以在面向集团不同部门开放数据应用的同时,实现不同部门不同人的精细化权限管控:不同的人根据其权限的不同看到的数据资产的内容是不同的。同时,新平台可以针对不同的业务部门进行财务成本的分摊核算。
(4)新平台显著降低了集成开发成本
新平台同时支持 Spark 和 Hive,原来平台的开发方式在新平台上可以平移,无需增加任何成本。新平台在此基础上提供了 Serverless 的 EMR Studio 的方式,可以在平台上进行开放式(而非打 jar 包)代码集成调试,降低了开发成本。
本文由 白鲸开源 提供发布支持!
热门相关:如果你给我,我们就吃吧 替罪新娘:前夫,放過我 寄宿生:危险的同居 火热的暧昧性爱近况 临时加彩礼?反手闪婚女主播!